前端工程化的学习(偏向 vite 构建工具)
✨文章摘要(AI生成)
笔者在学习前端工程化时,决定深入了解 Vite 构建工具,尤其是在项目中需要封装组件的过程中,感受到脚手架的缺乏带来的不便。Vite 的优势在于其开发环境中基于 ES 模块的按需加载,极大提升了启动速度,尤其在处理大型项目时表现出色。与 Webpack 相比,Vite 更关注开发体验,而 Webpack 则强调兼容性。
笔者总结了 Vite 的几个重要特性,如依赖预构建、路径补全、以及对 CSS 和静态资源的处理方式。同时,笔者提到构建优化的重要性,包括体积优化和分包策略,以提高浏览器的缓存效率。整体而言,Vite 的设计理念使得前端开发更为高效,帮助开发者更专注于代码编写而非运行细节。
好早就听说了 vite,也早就简单的使用并了解了一点,之前在公司实习团队也正在迁移 webpack 的项目到 vite,但我自己却一直没有深入,毕竟还是初级前端工程师,功力还欠缺很多,但最近封装了一个小组件,整个项目不使用脚手架挺难受的,到处参考别人的代码希望能找到组件开发的最佳实践,整个过程举步维艰,所以开始先从 vite 入手学习一下前端工程化相关的东西了...
为什么需要构建工具
摘抄一段vite官网对打包的描述:
使用工具抓取、处理并将我们的源码模块串联成可以在浏览器中运行的文件
现阶段我们基本都不会直接编写可以浏览器上运行的文件,更多的是使用各种新的框架(Vue/React)、语法(TypeScript/less/sass),用这些工具编写出来的代码时不能直接在浏览器上直接运行的,我们需要每次都手动使用不同的解释器/编译器去将用高级语法编写的代码转换为能在浏览器中运行的代码:  所以简单理解构建工具(打包工具)要做的就是这样一件事:将这条工具链内置,面向开发者透明,避免开发者每次查看效果都要重复机械化地输入不同的命令,除此之外,构建工具还可以使用各种优化工具优化最终生成的文件。 一般来说,一个构建工具会有以下功能:
所以简单理解构建工具(打包工具)要做的就是这样一件事:将这条工具链内置,面向开发者透明,避免开发者每次查看效果都要重复机械化地输入不同的命令,除此之外,构建工具还可以使用各种优化工具优化最终生成的文件。 一般来说,一个构建工具会有以下功能:
- 模块化支持:兼容多种模块化规范写法,支持从
node_modules中引入代码(浏览器本身只识别路径方式的模块导入,imoprt { forEach } from 'loadsh'这样直接以名字导入需构建工具识别) - 框架编译/语法转换:如:
tsc->lessc->vueComplier - 构建产物性能优化:文件打包、代码压缩、code splitting、tree shaking...
- 开发体验优化:hot module replacement、跨域解决等...
- ... 总的来说,构建工具让我们开发人员可以更加关注代码的编写,而非代码的运行。
五花八门的构建工具
市面上常见的构建工具有如下(这里简单说一下各种构建工具的特点,具体展开就太多了,大家感兴趣可以直接去官网看看):
- grunt:基于配置驱动的,开发者需要做的就是了解各种插件的功能,然后把配置整合到 Gruntfile.js 中,然后就可以自动处理一些需要反复重复的任务,例如代码压缩、编译、单元测试、linting 等工作,配置复杂度较高且 IO 操作较多。
- gulp:Gulp 最大特点是引入了流的概念,同时提供了一系列常用的插件去处理流,流可以在插件之间传递。这使得它本身被设计的非常简单,但却拥有强大的功能,既可以单独完成构建,也可以和其他工具搭配使用
- webpack:最主流的打包构建工具,兼容覆盖基本所有场景,前端工程化的核心,但相应带来的缺点就是配置繁琐
- rollup:由于 webpack 配置繁琐,对于小型项目开发者较不友好,他们更倾向于 rollup。其配置简单,易于上手,成为了目前最流行的 JS 库打包工具
- esbuild:使用 go 语言并大量使用了其高并发的特性,速度极快。不过目前 Esbuild 还很年轻,没有达到 1.0 版本,并且其打包构建与 Rollup 类似更关注于 JS 本身,所以并不适合单独使用在前端项目的生产环境之中
- parcel:...
- ...
- vite:开发环境基于 esmodule 规范按需加载,速度极快,具有极佳的开发体验,生产环境底层调用 rollup,接下来主要介绍 webpack 与 vite 之间的一个对比。
其实官网介绍 vite 的优势已经非常详细了,我自身也没有额外的理解,这里就直接摘要一段官网的话:
当我们开始构建越来越大型的应用时,需要处理的 JavaScript 代码量也呈指数级增长。包含数千个模块的大型项目相当普遍。基于 JavaScript 开发的工具就会开始遇到性能瓶颈,Vite 以 原生 ESM 方式提供源码。这实际上是让浏览器接管了打包程序的部分工作:Vite 只需要在浏览器请求源码时进行转换并按需提供源码。根据情景动态导入代码,即只在当前屏幕上实际使用时才会被处理。
再贴两张大家可能已经很熟的对比图:  相信大家看了上述官网的摘要差不多已经明白为什么 vite 在开发环境下启动速度非常快的原因了,主要就是使用了浏览器原生支持的
相信大家看了上述官网的摘要差不多已经明白为什么 vite 在开发环境下启动速度非常快的原因了,主要就是使用了浏览器原生支持的esmodule规范,当然还少不了 vite 本身在这之上做的一些优化,比如依赖预构建 我在一篇文章中看到过这样一个问题:这个思路既然能解决开发启动速度上的问题,为什么 webpack 不能支持呢? 答:
- webpack 的设计理念就是大而全,它需要兼容不同的模块化,我们的工程既有可能跑在浏览器端,也有可能跑在服务端,所以 webpack 会将不同的模块化规范转换为独有的一个函数
webpack_require进行处理,为了做到这一点,它必须一开始就要统一编译转换模块化代码,也就意味着它需要将所有的依赖全部读取一遍; - 而我们在使用 vite 项目的时候,就只能使用
esmodule规范,但项目的依赖仍然可能使用了不同的模块规范,vite 会在依赖预构建中处理这一步,将依赖树转换为单个模块并缓存在/node_modules/.vite下方便浏览器按需加载,将打包的部分工作交给了浏览器执行,优化了开发体验。而构建交给了rollup同样会兼容各种模块化规范...
总结:webpack 更多的关注兼容性,而 vite 关注浏览器端的开发体验,侧重点不一样
vite 处理细节
自身对前端工程化的理解也比较浅,从 vite 官网文档中可以学到不少前端工程化相关的知识,知识点总结至 vite 官网,快速入口
1. 导入路径补全
在处理的过程中如果说看到了有非绝对路径或者相对路径的引用, 他则会尝试开启路径补全:
import _ from "lodash" // 补全前,浏览器并不认识这种裸模块导入
import _ from "/node_modules/.vite/lodash"; // 补全后,使用依赖预构建处理后的结果2. 依赖预构建
主要就是为了解网络多包传输的性能问题,官网原话:
一些包将它们的 ES 模块构建作为许多单独的文件相互导入。例如,
lodash-es有超过 600 个内置模块!当我们执行import { debounce } from 'lodash-es'时,浏览器同时发出 600 多个 HTTP 请求!尽管服务器在处理这些请求时没有问题,但大量的请求会在浏览器端造成网络拥塞,导致页面的加载速度相当慢。
通过预构建
lodash-es成为一个模块,我们就只需要一个 HTTP 请求了!
重写前:
// a.js
export default function a() {}export { default as a } from "./a.js"vite 重写以后:
function a() {}顺便解决了以下两个问题:
- 不同的第三方包会有不同的导出格式,Vite 会将作为 CommonJS 或 UMD 发布的依赖项转换为 ESM
- 对路径的处理上可以直接使用.vite/deps, 方便路径重写
其他:构建这一步由 esbuild 执行,这使得 Vite 的冷启动时间比任何基于 JavaScript 的打包器都要快得多
注意:这里都是指的开发环境,生产环境会交给 rollup 去执行
3. vite 与 ts
vite 他天生就对 ts 支持非常良好, 因为 vite 在开发时态是基于 esbuild, 而 esbuild 是天生支持对 ts 文件的转换的快速入口
4. 环境变量
一个产品可能要经过如下环境:
开发环境
测试环境
预发布环境
灰度环境
生产环境 不同的环境使用的数据应该是隔离的,或者是经过处理的,比如小流量环境,很显然,不同环境在一些密钥上的设置上是不同的,环境变量在这时候就尤为重要了,vite 中内置了 dotenv 对环境变量进行处理: dotenv 会自动读取.env 文件, 并解析这个文件中的对应环境变量 并将其注入到 process 对象下(但是 vite 考虑到和其他配置的一些冲突问题, 他不会直接注入到 process 对象下) 配置:
.env # 所有情况下都会加载 .env.local # 所有情况下都会加载,但会被 git 忽略 .env.[mode] # 只在指定模式下加载 .env.[mode].local # 只在指定模式下加载,但会被 git 忽略 然后文件里使用
VITE前缀的命名变量VITE_SOME_KEY=123,可以在vite.config.ts中配置envPrefix: "ENV_"修改这个前缀 使用:
console.log(import.meta.env.VITE_SOME_KEY) // 123
console.log(import.meta.env.DB_PASSWORD) // undefined其他:为什么 vite.config.js 可以书写成 esmodule 的形式(vite 明明是运行在服务端的), 这是因为 vite 他在读取这个 vite.config.js 的时候会率先 node 去解析文件语法, 如果发现你是 esmodule 规范会直接将你的 esmodule 规范进行替换变成 commonjs 规范
5. vite 对 css 的处理
基本流程:1. vite 在读取到 main.js 中引用到了 Index.css
- 直接去使用 fs 模块去读取 index.css 中文件内容
- 直接创建一个 style 标签, 将 index.css 中文件内容直接 copy 进 style 标签里
- 将 style 标签插入到 index.html 的 head 中
- 将该 css 文件中的内容直接替换为 js 脚本(方便热更新或者 css 模块化), 同时设置 Content-Type 为 js 从而让浏览器以 JS 脚本的形式来执行该 css 后缀的文件
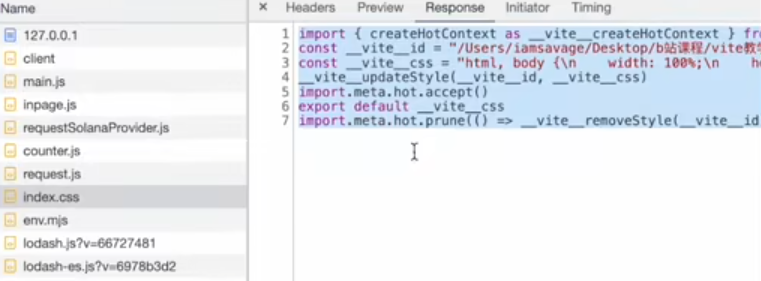
处理重复类名
 全部都是基于 node
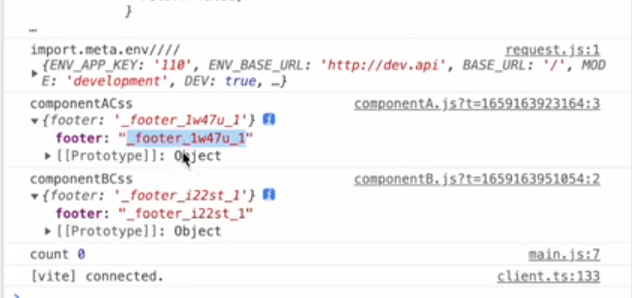
全部都是基于 node - module.css (module 是一种约定, 表示需要开启 css 模块化)
- 他会将你的所有类名进行一定规则的替换(将 footer 替换成 _footer_i22st_1)
- 同时创建一个映射对象
- 将替换过后的内容塞进 style 标签里然后放入到 head 标签中 (能够读到 index.html 的文件内容)
- 将 componentA.module.css 内容进行全部抹除, 替换成 JS 脚本
- 将创建的映射对象在脚本中进行默认导出
config 参考
// 摘自 https://github.com/passerecho/vite-
css: { // 对 css 的行为进行配置
// modules 配置最终会丢给 postcss modules
modules: { // 是对 css 模块化的默认行为进行覆盖
localsConvention: "camelCaseOnly", // 修改生成的配置对象的 key 的展示形式(驼峰还是中划线形式)
scopeBehaviour: "local", // 配置当前的模块化行为是模块化还是全局化 (有 hash 就是开启了模块化的一个标志, 因为他可以保证产生不同的 hash 值来控制我们的样式类名不被覆盖)
// generateScopedName: "[name]_[local]_[hash:5]" // https://github.com/webpack/loader-utils#interpolatename
// generateScopedName: (name, filename, css) => {
// // name -> 代表的是你此刻 css 文件中的类名
// // filename -> 是你当前 css 文件的绝对路径
// // css -> 给的就是你当前样式
// console.log("name", name, "filename", filename, "css", css); // 这一行会输出在哪??? 输出在 node
// // 配置成函数以后, 返回值就决定了他最终显示的类型
// return `${name}_${Math.random().toString(36).substr(3, 8) }`;
// }
hashPrefix: "hello", // 生成 hash 会根据你的类名 + 一些其他的字符串(文件名 + 他内部随机生成一个字符串)去进行生成, 如果你想要你生成 hash 更加的独特一点, 你可以配置 hashPrefix, 你配置的这个字符串会参与到最终的 hash 生成, (hash: 只要你的字符串有一个字不一样, 那么生成的 hash 就完全不一样, 但是只要你的字符串完全一样, 生成的 hash 就会一样)
globalModulePaths: ["./componentB.module.css"], // 代表你不想参与到 css 模块化的路径
},
preprocessorOptions: { // key + config key 代表预处理器的名
less: { // 整个的配置对象都会最终给到 less 的执行参数(全局参数)中去
// 在 webpack 里就给 less-loader 去配置就好了
math: "always",
globalVars: { // 全局变量
mainColor: "red",
}
},
},
devSourcemap: true,
},6. 静态资源
服务时引入一个静态资源会返回解析后的公共路径:
import imgUrl from './img.png'
document.getElementById('hero-img').src = imgUrl例如,imgUrl 在开发时会是 /img.png,在生产构建后会是 /assets/img.2d8efhg.png。
行为类似于 Webpack 的 file-loader。区别在于导入既可以使用绝对公共路径(基于开发期间的项目根路径),也可以使用相对路径。
为什么要使用 hash
浏览器是有一个缓存机制 静态资源名字只要不改, 那么他就会直接用缓存的 刷新页面--> 请求的名字是不是同一个 --> 读取缓存 --> 所以我们要尽量去避免名字一致(每次开发完新代码并构建打包时)
1. 显式 URL 引入
未被包含在内部列表或 assetsInclude 中的资源,可以使用 ?url 后缀显式导入为一个 URL。这十分有用,例如,要导入 Houdini Paint Worklets 时:
import workletURL from 'extra-scalloped-border/worklet.js?url'
CSS.paintWorklet.addModule(workletURL)2. 将资源引入为字符串
资源可以使用 ?raw 后缀声明作为字符串引入。
import shaderString from './shader.glsl?raw'比如 svg 文件如果我们以 url 的方式导入文件,则相当于导入一张图片,只能对其进行图片的相关操作,如果我们想要对其进行 svg 相关的操作,我们则需要使用?raw的方式导入:
import svgIcon from "./assets/svgs/fullScreen.svg?url"; // 这种是以图片的方式加载 svg,无其他特殊操作
import svgRaw from "./assets/svgs/fullScreen.svg?raw"; // 加载 svg 的源文件,这种方式的加载可以做到修改 svg 的颜色等操作
console.log("svgIcon", svgIcon, svgRaw);
document.body.innerHTML = svgRaw;
const svgElement = document.getElementsByTagName("svg")[0];
svgElement.onmouseenter = function() {
// 不是去改他的 background 也不是 color
// 而是 fill 属性
this.style.fill = "red";
}
// 第一种使用 svg 的方式
// const img = document.createElement("img");
// img.src = svgIcon;
// document.body.appendChild(img);
// 第二种加载 svg 的方式3. 导入脚本作为 Worker
脚本可以通过 ?worker 或 ?sharedworker 后缀导入为 web worker。
// 在生产构建中将会分离出 chunk
import Worker from './shader.js?worker'
const worker = new Worker()// sharedworker
import SharedWorker from './shader.js?sharedworker'
const sharedWorker = new SharedWorker()// 内联为 base64 字符串
import InlineWorker from './shader.js?worker&inline'性能优化
- 代码逻辑上的优化,如:
- 使用
lodash工具中的防抖、节流而非自己编写;数组数据量大时,也可以使用lodash中的forEach方法等等 for(let i = 0; i < arr.length; i++){}替换为for(let i = 0, len = arr.length; i < len; i++)这样只用通过作用域链获取一次父作用域中的arr变量- ...
- 使用
- 构建优化(构建工具关注的事):体积优化->压缩、treeshaking、图片资源压缩、cdn 加载、分包...
- ...
其中分包知识我第一次接触到,这里记录一下: 主要是为了配合浏览器中的缓存策略
- 假设这样一个场景,我们使用
lodash中的forEach函数编写了console('1'),最终打包后的代码如果不分包则会将lodash中的相关实现和console('1')合并为一个文件传给浏览器; - 而我们的业务代码经常变化,比如
console('1')-->console('2')这时候我们仍然需要将lodash中的相关实现和console('1')合并为一个文件传给浏览器; - 但显然
lodash中的代码实现并没有更改,浏览器直接使用以前的就可以了 - 所以分包就是把一些不会经常更新的文件,进行单独打包处理为一个文件,配置参考
最后
前端工程化我也是最近开始学习,如有理解错误希望各位大佬不吝赐教