Node 进程及集群相关
✨文章摘要(AI生成)
笔者在这篇文章中深入探讨了 Node.js 中的进程及集群相关概念,首先介绍了 Node.js 的多进程创建方法,包括spawn()、exec()、execFile()和fork(),并详细阐述了它们的区别和适用场景。接着,笔者分析了 Node.js 的多进程架构,强调主进程与工作进程的角色分配,以及如何利用多核 CPU 的优势。
此外,文章还介绍了进程间通信的原理,尤其是通过 IPC 通道传递消息的机制。笔者提到,Node.js 支持多个进程监听相同端口的能力,使用send()方法直接转发 socket 句柄,从而避免了传统代理模式的缺陷。
最后,笔者讨论了集群的稳定性和负载均衡策略,包括平滑重启和重启频率控制,并对 Node.js 的cluster模块进行了简要介绍,指出其在多核 CPU 利用率和进程管理上的优势。
创建进程
相信大家耳边听烂的一句话就是“JavaScript是单线程的”,为了弥补面对单线程对多核使用不足的问题,node很方便的提供了几个创建进程的方法:
spawn():启动一个子进程来执行命令exec():启动一个子进程来执行命令,与spawn()不同的是其接口不同,它有一个回调函数获知子进程的状况execFile():启动一个子进程来执行可执行文件fork():与spawn()类似,不同点在于它创建node的子进程只需指定要执行的JavaScript文件模块即可
spawn()与exec()、execFile()不同的是,后两者创建时可以指定timeout属性设置超时时间,一旦创建的进程超过设定的时间将会被杀死;
exec()与execFile()不同的是,exec()适合执行已有的命令,execFile()适合执行文件;
| 类型 | 回调/异常 | 进程类型 | 执行类型 | 可设置超时时间 |
|---|---|---|---|---|
spawn() | × | 任意 | 命令 | × |
exec() | √ | 任意 | 命令 | 对 |
execFile() | √ | 任意 | 可执行文件 | √ |
fork() | × | Node | JavaScript文件 | × |
一般来说创建多线程只是为了充分将 CPU 资源利用起来,在做服务端时,事件驱动的机制已经可以很好的解决大并发的问题了,注意和每请求/每进程的服务端模型区分
Node 多进程架构
经典的主从模式:
- 主进程不负责具体的业务处理,而是负责调度或管理工作进程,它是趋于稳定的
- 工作进程负责具体的业务处理
比如我们这里编写一个经典的代码试试:

这里主进程中查询了当前机器 cpu 的核心数,根据不同的核心数复制对应数量的工作进程,从而真正利用到多核 CPU 的优势,当然由于我这台服务器只有单核,所以这里只开出了一个子进程,这里假设有 8 核的话就是如下效果:

当然,这是个反面例子,因为我们本来就是要利用多核 CPU 的性能才开出多个进程,而这里在单核 CPU 上开出 8 个进程是没用的,反而调度器还要来回切换进程进行处理,因为操作系统有句经典的话就是“宏观上并发执行,微观上交替执行”,所以我这里这样做是没用的,只是为了演示。
进程通信原理
这里先复习一下操作系统中进程通信的方式详细链接 或 详细链接:
- 共享内存通信方式
- 消息传递通信方式(利用操作系统提供的消息传递系统实现进程通信)
- 消息缓冲通信方式:直接通信方式
- 信箱通信方式:间接通信方式,对同步的要求没那么严格
- 共享文件通信方式:管道通信方式
除此之外,还有一些其他的通信方式比如:
- 信号量通信,传递的信息较少
- 套接字通信
而node是通过管道技术实现的,当然这个管道与上述中的管道有所区别,是在node中的一个抽象层面,具体在 windows 中是用命名管道,linux 使用unix domain socket实现的,最终体现出现就是进程之间创建 IPC 通道,通过这个通道,进程之间才能通过message和send()传递消息
细节上:
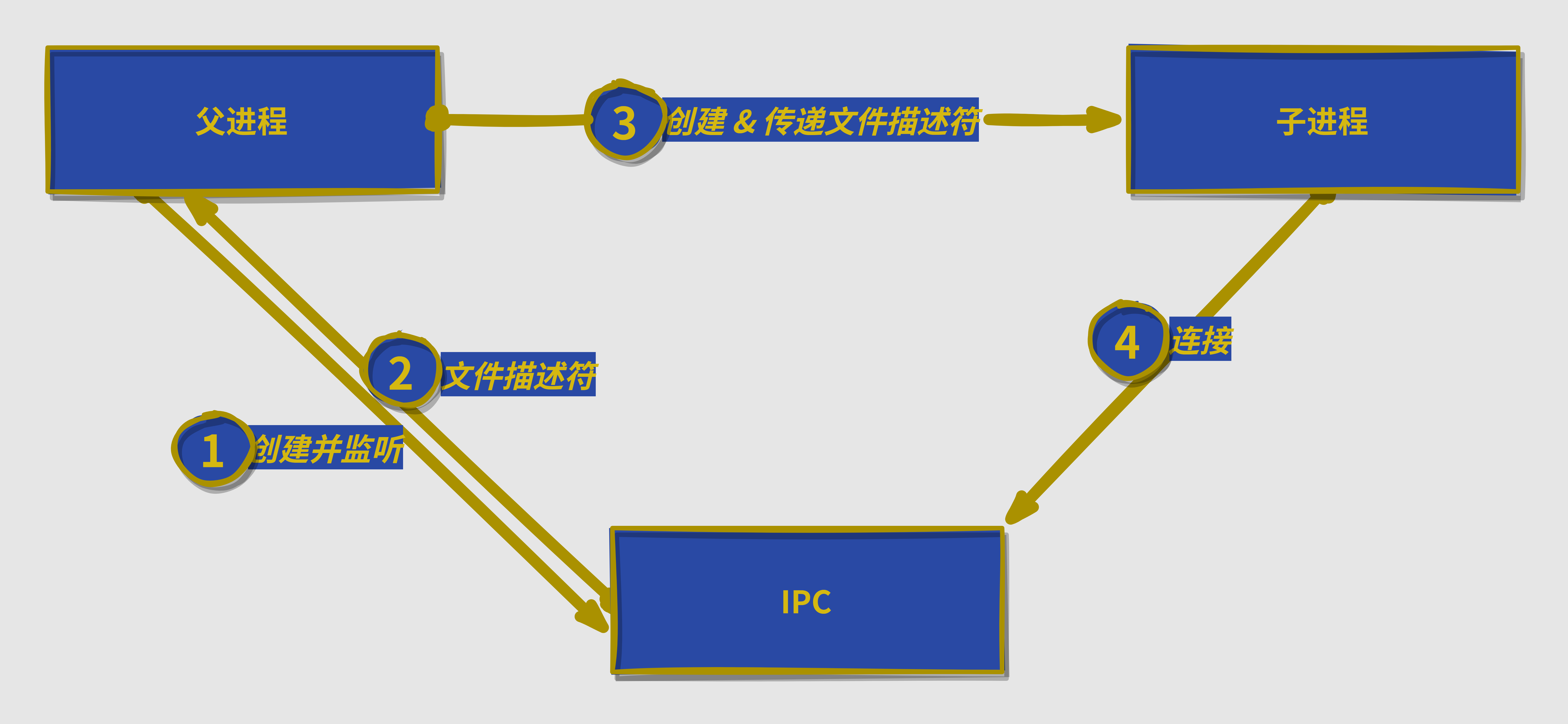
- 父进程在实际创建子进程之前,会创建 IPC 通道并监听它,然后才真正创建出子进程,并通过环境变量(NODE_CHANNEL_FD)告诉子进程这个 IPC 通道的文件描述符
- 子进程在启动的过程中,根据文件描述符去链接这个已存在的 IPC 通道,从而完成父子进程之前的连接(创建的子进程为
node进程默认为遵守这个约定,而非node进程的要么自实现遵守约定,要么不能通信) - IPC 通道被抽象为
Stream对象,在调用send()时发送数据(类似于write()),接收到的消息会通过message事件(类似于data)触发给应用层
多个进程监听相同的端口
1. 首先是为什么要让多个进程来监听相同的端口
因为我们要使用主从模式,使不同的工作线程来处理同一个应用,但是操作系统中,一般来说都是一个端口对应一个进程即一个应用
⚠如何不做任何处理,直接让多个进程监听同一个端口是会报错的
2. 那为什么不能使用如下这种方法呢?
我们在使用主从模式的时候,可以使用主进程来监听主端口(如 80),即主进程对外接收所有的网络请求,再将这些请求分别代理到不同的端口的进程上
答:
通过代理,虽然可以避免端口不能被重复监听的问题,甚至可以在代理进程上做适当的负载均衡,使得每个子进程可以较为均衡地执行任务。
但是由于进程每接收到一个连接,就会用掉一个文件描述符,因此代理方案中客户端连接到代理进程需要消耗,代理进程连接到工作进程这两个阶段需要消耗掉两个文件描述符。而操作系统地文件描述符是有限地,代理方案浪费了一倍数量地文件描述符影响了系统的扩展能力
3. 那该如何解决呢?
node中还存在发送句柄的操作,句柄是一种可以用来标识资源的引用,因此我们可以直接在主进程收到 socket 请求后,将这个 socket 通过send()方法发送给工作进程,而不是代理方案中的与工作进程重新建立新的 socket 连接,是通过 IPC 进程通信方式直接发送句柄,同时我们将 socket 发送给了子进程之后,主进程自己也可以关闭监听,之后由子进程来处理请求,这样最终效果就变为了“多个进程监听相同的端口”但不报错。
// 主进程
const child = require('child_process').fork('child.js');
const child1 = cp.fork('child.js');
const child2 = cp.fork('child.js');
// Open up the server object and send the handle
const server = require('net').createServer();
server.listen(1337, function () {
child1.send('server', server);
child2.send('server', server);
// 关掉主进程的监听,让子进程来处理这些请求
server.close();
});// 工作进程
const http = require('http');
const server = http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('handled by child, pid is ' + process.pid + '\n');
});
process.on('message', function (m, tcp) {
if (m === 'server') {
tcp.on('connection', function (socket) {
server.emit('connection', socket);
});
}
});
最终发送到 IPC 通道的信息都是字符串,刚才上述代码发送的其实是句柄文件描述符,是一个整数,
send()方法会将原始信息结合其他信息包装为一个对象并序列化为字符串传递过去,另一边再JSON.parse()就可以了
集群稳定
子进程的相关事件快速入口
自动重启
通过监听子进程的exit事件来获知其退出的信息,然后做一些操作,比如重启一个工作进程来继续服务:
// master.js
const fork = require('child_process').fork;
const cpus = require('os').cpus();
const server = require('net').createServer();
server.listen(1337);
const workers = {};
const createWorker = function () {
const worker = fork(__dirname + '/worker.js');
// 退出时重新启动新的进程
worker.on('exit', function () {
console.log('Worker ' + worker.pid + ' exited.');
delete workers[worker.pid];
createWorker();
});
// 句柄转发
worker.send('server', server);
workers[worker.pid] = worker;
console.log('Create worker. pid: ' + worker.pid);
};
for (let i = 0; i < cpus.length; i++) {
createWorker();
}
// 进程自己退出时,让所有工作进程退出
process.on('exit', function () {
for (let pid in workers) {
workers[pid].kill();
}
});缺点,上述代码是在子进程退出后重启的新进程来处理请求,这中间有一段空白期,我们应该在子进程退出前就启动的新的工作进程从而实现平滑重启:
// worker.js
process.on('uncaughtException', function (err) {
process.send({ act: 'suicide' });
// 停止接收新的连接
worker.close(function () {
// 所有已有连接断开后,退出进程
process.exit(1);
});
// 设个超时自动断开,避免长连接断开需要较久的时间
setTimeout(function () {
process.exit(1);
}, 5000);
});const createWorker = function () {
const worker = fork(__dirname + '/worker.js');
// 启动新的进程
worker.on('message', function (message) {
if (message.act === 'suicide') {
createWorker();
}
});
worker.on('exit', function () {
console.log('Worker ' + worker.pid + ' exited.');
delete workers[worker.pid];
});
worker.send('server', server);
workers[worker.pid] = worker;
console.log('Create worker. pid: ' + worker.pid);
};当业务代码本来就有严重的问题,无论重启多少次都会报错,我们应该有合适的策略放弃重启,比如单位时间内只能重启有限次数,否则就放弃(最好需要添加日志、报警等):
// 重启次数
const limit = 10;
// 时间单位
const during = 60000;
const restart = [];
const isTooFrequently = function () {
// 记录重启时间
const time = Date.now();
const length = restart.push(time);
if (length > limit) {
// 取出最后 10 个记录
restart = restart.slice(limit * -1);
}
// 最后一次重启到前 10 次重启之间的时间间隔
return restart.length >= limit && restart[restart.length - 1] - restart[0] < during;
};
const workers = {};
const createWorker = function () {
// 检查是否太过频繁
if (isTooFrequently()) {
// 触发 giveup 事件后,不再重启
process.emit('giveup', length, during);
return;
}
const worker = fork(__dirname + '/worker.js');
worker.on('exit', function () {
console.log('Worker ' + worker.pid + ' exited.');
delete workers[worker.pid];
});
// 重新启动新的进程
worker.on('message', function (message) {
if (message.act === 'suicide') {
createWorker();
}
});
// 句柄转发
worker.send('server', server);
workers[worker.pid] = worker;
console.log('Create worker. pid: ' + worker.pid);
};负载均衡
合理分配任务,避免单方面忙碌和单方面空闲
常见的策略如下:
- 轮询:每个请求按时间顺序逐一分配到不同的后端服务器,如果后端服务器 down 掉,能自动剔除。
- 指定权重:指定轮询几率,weight 和访问比率成正比,用于后端服务器性能不均的情况。
- IP 绑定 ip_hash:每个请求按访问 ip 的 hash 结果分配,这样每个访客固定访问一个后端服务器,可以解决 session 的问题。
- fair(第三方):按后端服务器的响应时间来分配请求,响应时间短的优先分配。
- url_hash(第三方):按访问 url 的 hash 结果来分配请求,使每个 url 定向到同一个后端服务器,后端服务器为缓存时比较有效。
状态共享
解决数据共享最直接、简单的方式就是通过第三方来进行数据存储,然后单独使用一个进程来轮询获取数据,并主动通知给各个工作线程
Cluster 模块
刚才进程之间的管理都是我们自己手动写的,其实node有很方便的cluster模块,用以解决多核 CPU 的利用率问题,同时也了较完善的 API,用以处理进程的健壮性问题。
参考
- 《深入浅出 NodeJS》
- https://zhuanlan.zhihu.com/p/89356016