了解 API 相关范式(RPC、REST、GraphQL)
✨文章摘要(AI生成)
笔者在本文中探讨了三种常见的 API 范式:RPC、REST 和 GraphQL。
- RPC 允许开发者像调用本地方法一样调用远程方法,具有高效低延迟的优点,但与底层系统紧密耦合,降低了可重用性。
- REST 则是一种面向资源的风格,强调客户端与服务器的解耦,支持多种数据格式,便于缓存,但在实践中缺乏统一结构,可能导致高负载和数据过度获取。
- GraphQL 作为一种查询语言,允许客户端灵活请求所需数据,减少了请求次数,但存在性能问题和学习成本。
总体而言,RPC 适合内部微服务,REST 适用于标准 API 建模,而 GraphQL 在数据获取的灵活性上占优势,开发者应根据具体需求选择合适的 API 范式。
前言
两个独立的应用程序经常需要相互访问交谈,或则可以是同一个应用程序,但部署在不同的服务器,或者现在常用的前后端分离式架构等等需要经常相互访问交谈,因此开发人员经常搭建桥梁 API(Application Programming Interfaces)
关于 API 的定义,你可以简单看看这篇文章-- What is an API: Definition, Types, Specifications, Documentation
关于历史出现的 API 范式,我们可以参考 Rob Crowley的这张图:
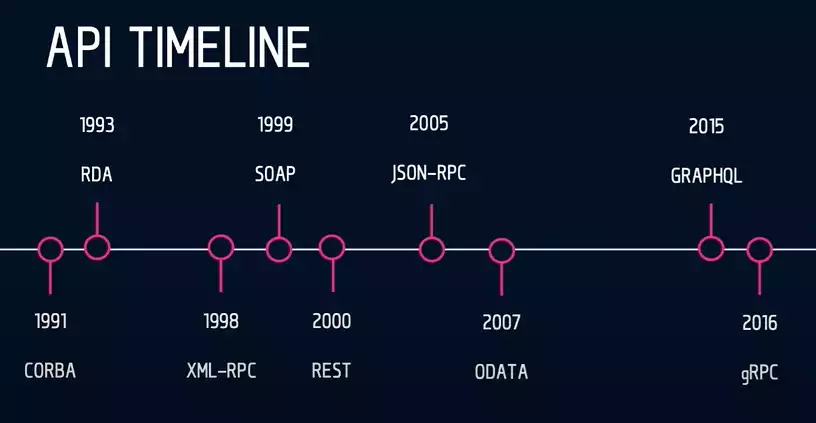
目前使用的较多的就是 RPC、REST、GraphQL,接下来将会对这三种范式进行优缺点的讨论...
RPC(Remote Procedure Call)
简介
RPC 出现的最初目的,就是为了让计算机能够跟调用本地方法一样去调用远程方法,我们可以简单理解为一个本地方法调用+网络通信
工作过程
客户端调用远程过程,将参数和附加信息序列化为消息,并将消息发送到服务器。收到消息后,服务器反序列化其内容,执行请求的操作,并将结果发送回客户端。

相关规范
RPC 只是一个概念,但是这个概念有很多规范,都有具体的实现,如:RMI(Sun/Oracle)、Thrift(Facebook/Apache)、Dubbo(阿里巴巴/Apache)、gRPC(Google)、Motan1/2(新浪)、Finagle(Twitter)、brpc(百度/Apache)、.NET Remoting(微软)、Arvo(Hadoop)、JSON-RPC 2.0(公开规范,JSON-RPC 工作组)
参考《凤凰架构》:
- 朝着面向对象发展,不满足于 RPC 将面向过程的编码方式带到分布式,希望在分布式系统中也能够进行跨进程的面向对象编程,代表为 RMI、.NET Remoting,之前的 CORBA 和 DCOM 也可以归入这类,这条线有一个别名叫做分布式对象(Distributed Object)。
- 朝着性能发展,代表为 gRPC 和 Thrift。决定 RPC 性能的主要就两个因素:序列化效率和信息密度。序列化效率很好理解,序列化输出结果的容量越小,速度越快,效率自然越高;信息密度则取决于协议中有效荷载(Payload)所占总传输数据的比例大小,使用传输协议的层次越高,信息密度就越低,SOAP 使用 XML 拙劣的性能表现就是前车之鉴。gRPC 和 Thrift 都有自己优秀的专有序列化器,而传输协议方面,gRPC 是基于 HTTP/2 的,支持多路复用和 Header 压缩,Thrift 则直接基于传输层的 TCP 协议来实现,省去了额外应用层协议的开销。
- 朝着简化发展,代表为 JSON-RPC,说要选功能最强、速度最快的 RPC 可能会很有争议,但选功能弱的、速度慢的,JSON-RPC 肯定会候选人中之一。牺牲了功能和效率,换来的是协议的简单轻便,接口与格式都更为通用,尤其适合用于 Web 浏览器这类一般不会有额外协议支持、额外客户端支持的应用场合。
优点
实现 RPC 的可以传输协议可以直接建立在 TCP 之上,也可以建立在 HTTP 协议之上。大部分 RPC 框架都是使用的 TCP 连接(gRPC 使用了 HTTP2)。
- 调用简单,清晰,透明,不用像 rest 一样复杂,就像调用本地方法一样简单(同样也是缺点,就是后续提到的耦合度强)
- 高效低延迟,性能高
- 使用自定义 TCP 协议进行传输可以极大地减轻了传输数据的开销。 这也就是为什么通常会采用自定义 TCP 协议的 RPC 来进行进行服务调用的真正原因。
- 成熟的 RPC 框架还提供好了“服务自动注册与发现”、"智能负载均衡"、“可视化的服务治理和运维”、“运行期流量调度”等等功能减轻开发者心智负担
缺点
- 与底层系统紧密耦合:API 的抽象级别有助于其可重用性。它对底层系统越紧密,对其他系统的可重用性就越低。RPC 与底层系统的紧密耦合不允许在系统功能和外部 API 之间存在抽象层。这会引发安全问题,因为很容易将有关底层系统的实现细节泄露到 API 中。RPC 的紧耦合使得可扩展性需求和松耦合团队难以实现。因此,客户端要么担心调用特定端点的任何可能的副作用,要么尝试找出要调用的端点,因为它不了解服务器如何命名其功能。
- 各个函数可能复用率低:创建新功能非常容易(这也可以算作优点之一)。因此,可能经常没有编辑现有的,而是创建了新的,最终得到了大量难以理解的重叠功能。
REST(Representational state transfer)
介绍
REST – REpresentational State Transfer
RESTful 实例可以查看我之前写的 Django这个笔记或者 NestJS这个笔记,如果你使用过 REST,可以直接忽略这段话,继续下面的阅读。
下面谈谈偏理论的东西,如何理解 REST:
REST 本质上是面向资源编程,这也是与 RPC 面向过程编程最主要的区别,需要注意的是,REST 只是一种风格,不遵循它编译器也不会报错,只是不能享受到对应的一些好处罢了,需要设计者灵活考虑。
既然是面向资源编程,所以我们可以这样理解一个符合 RESTful 的接口:
- 看 URL 就知道我们的目标是什么资源
- 看方法就知道我们需要对该资源进行什么样的操作
- 看返回码就知道操作的结果如何
比如我们要获取这个编号的咖啡信息
curl -X GET https://api.justin3go.com/coffees/1REST 的指导原则
REST 的指导原则部分内容引用该篇文档的机翻:
统一接口
通过将 通用性原则应用于 组件接口,我们可以简化整体系统架构并提高交互的可见性。
多个体系结构约束有助于获得统一的接口并指导组件的行为。
以下四个约束可以实现统一的 REST 接口:
- 资源标识 ——接口必须唯一标识客户端和服务器之间交互中涉及的每个资源。
- 通过表示操作资源 ——资源在服务器响应中应该有统一的表示。API 消费者应该使用这些表示来修改服务器中的资源状态。
- 自描述消息 ——每个资源表示都应该携带足够的信息来描述如何处理消息。它还应提供有关客户端可以对资源执行的其他操作的信息。
- 超媒体作为应用程序状态的引擎 ——客户端应该只有应用程序的初始 URI。客户端应用程序应使用超链接动态驱动所有其他资源和交互。
客户端服务器
客户端-服务器设计模式强制 关注点分离,这有助于客户端和服务器组件独立发展。
通过将用户界面问题(客户端)与数据存储问题(服务器)分开,我们提高了跨多个平台的用户界面的可移植性,并通过简化服务器组件提高了可扩展性。
随着客户端和服务器的发展,我们必须确保客户端和服务器之间的接口/契约不会中断。
无状态
无状态 要求从客户端到服务器的每个请求都必须包含理解和完成请求所需的所有信息。
服务器无法利用服务器上任何先前存储的上下文信息。
为此,客户端应用程序必须完全保持会话状态。
可缓存
可 缓存约束 要求响应应隐式或显式将自身标记为可缓存或不可缓存。
如果响应是可缓存的,则客户端应用程序有权在以后的等效请求和指定时间段内重用响应数据。
分层系统
分层系统风格允许架构通过约束组件行为由分层层组成。
例如,在分层系统中,每个组件都无法看到与其交互的直接层之外的信息。
按需代码(可选)
REST 还允许通过下载和执行小程序或脚本形式的代码来扩展客户端功能。
下载的代码通过减少需要预先实现的功能数量来简化客户端。服务端可以将部分特性以代码的形式交付给客户端,客户端只需要执行代码即可。
优点
- 解耦客户端和服务器:耦合性低,兼容性好,提高开发效率
- 不用关心接口实现细节,相对更规范,更标准,更通用,跨语言支持
- 缓存友好:重用大量 HTTP 工具,REST 是唯一允许在 HTTP 级别缓存数据的样式。相比之下,任何其他 API 上的缓存实现都需要配置额外的缓存模块。
- 多种格式支持:支持多种格式来存储和交换数据
缺点
- 没有统一的 REST 结构:正如之前所说,只是一种风格,有一些指导原则,所以构建 REST API 没有完全正确的方法。如何建模资源以及建模哪些资源仍灵活多变,取决于业务场景。这使得 REST 理论上很简单但实践中较为困难。
- 高负载:REST API 会返回大量丰富的元数据,方便客户端仅从响应中就可以了解有关应用程序状态的所有必要信息,随之而来的就是一定的性能问题(高负载)。这个缺点和下面一个缺点也是后续 GraphQL 被提出的主要原因。
- 过度获取和获取不足:无法预估后续业务场景会如何变化,这导致了最初设计的 API 很难根据业务场景不断变化并且不能影响到之前的业务。
GraphQL(Graph query language)
介绍
如果你熟悉 REST,但不熟悉 GraphQL,推荐阅读这篇文章--GraphQL vs. REST,里面有较为详细的对比与介绍
首先来说,它是一种查询语言,具有一定的语法规则(即学习成本--有编程基础的话较小),可以解决上述 REST 中的一些问题。
引用官网的介绍:
GraphQL 是一种用于 API 的查询语言,也是使用现有数据完成这些查询的运行时。GraphQL 为您的 API 中的数据提供了完整且易于理解的描述,使客户能够准确地询问他们需要什么,仅此而已,随着时间的推移更容易发展 API,并启用强大的开发人员工具。
Q&A
这里引用一下官网的 FAQ
ls GraphQL a database language like SQL?
No, but this is a common misconception.
GraphQL is a specification typically used for remote client-server communications. Unlike SQL, GraphQL is agnostic to the data source(s) used to retrieve data and persist changes. Accessing and manipulating data is performed with arbitrary functions called resolvers. GraphQL coordinates and aggregates the data from these resolver functions, then returns the result to the client. Generally, these resolver functions should delegate to a business logic layer responsible for communicating with the various underlying data sources. These data sources could be remote APIs, databases, local cache, and nearly anything else your programming language can access.
For more information on how to get GraphQL to interact with your database, check out our documentation on resolvers.
Does GraphQL replace REST?
No, not necessarily. They both handle APIs and can serve similar purposes from a business perspective. GraphQL is often considered an alternative to REST, but it’s not a definitive replacement.
GraphQL and REST can actually co-exist in your stack. For example, you can abstract REST APIs behind a GraphQL server. This can be done by masking your REST endpoint into a GraphQL endpoint using root resolvers.
For an opinionated perspective on how GraphQL compares to REST, check out How To GraphQL.
看到上述两个 FAQ 我自己蹦出了这样的想法:
首先我想到的是一个比较荒谬的问题:既然 GraphQL 是一种查询语言,SQL 也是一种查询语言,那为什么不直接前端传入 sql 直接拿数据呢?
显然这是有很多问题的,最主要的问题就是这相当于无后端,全部逻辑都集中在了客户端,这对于客户端的压力是非常大的,并且也是非常不安全的,就类似于破解单机游戏一样...
高耦合的话我理解前端程序也可以进行多层抽象来解耦,比如 MVC 这类。但这又要重新经历一次类似的 web 架构演变,对现有的生态也是极大的破坏...
上述只是一些胡乱猜想,不必当真,回到这里的话 GraphQL 就是对后端提供的 GraphQL 运行时查询的语言,官方语法为 SDL。而这个运行时是应用程序业务逻辑外面的一层接口暴露,我们开发人员需要对每一个接口业务字段
然后与 REST 的区别我理解就是:二者本质都可以理解为面向资源编程
- GraphQL 通过一个运行时,使用规定的语法可以更加精准灵活地操作资源(灵活度也是有一定限度的,只是相对来说)
- 而 REST 就能根据提前定义好地 URL,通过不同的方法操作资源
这部分可能各有各的想法思考,欢迎友善讨论~
工作过程
在查询之前需要 schema,客户端可以验证他们的查询以确保服务器能够响应它。在到达后端应用程序时,GraphQL 操作将针对整个 schema 进行解释,并使用前端应用程序的数据进行解析。向服务器发送大量查询后,API 会返回一个 JSON 响应,其中的数据形状与我们请求的数据完全相同。
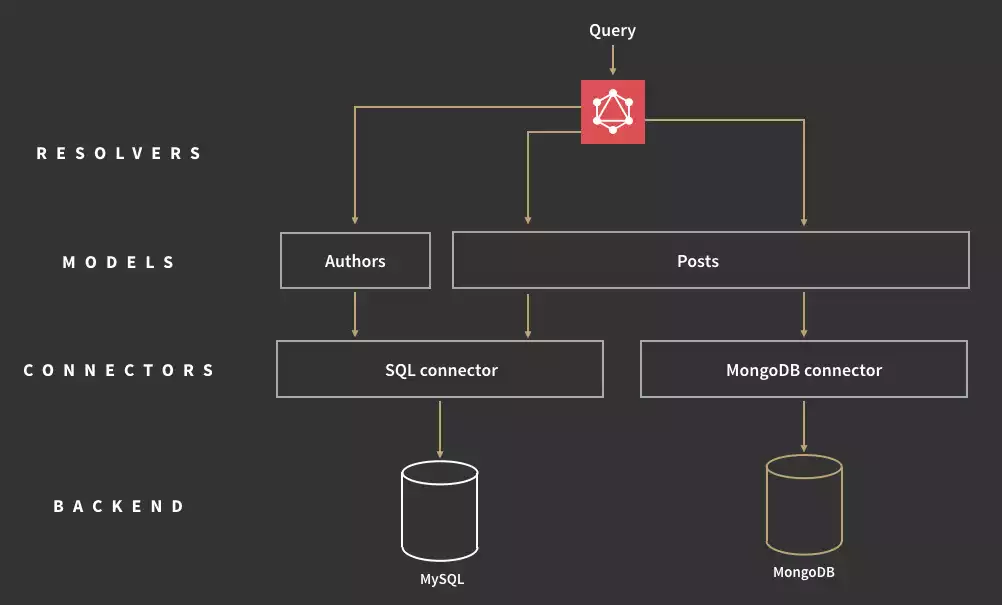
参考:_Jonas Helfer
除了 RESTful CRUD 操作之外,GraphQL 还具有允许来自服务器的实时通知的订阅。
GraphQL 需要我们对暴露出去的每一个字段规定一个函数进行处理,比如一个简单的 node 搭建的应用程序如下:
var express = require('express');
var graphqlHTTP = require('express-graphql');
var { buildSchema } = require('graph');
// 构建 schema,这里定义查询的语句和类型
var schema = buildSchema(`
typr Account {
name: String
age: Int
sex: String
department: String
}
type Query {
hello: String
accountName: String
age: Int
account: Account
}
`)
// 定义查所对应的 resolver,也就是查询对应的处理器
var root = {
hello: () => 'Hello world',
accountName: () => 'justin3go',
age: () => 18,
account: () => ({
name: '',
age: 18,
sex: '',
department: ''
})
}
var app = express();
app.use('/graphql', graphqlHTTP({
schema: schema,
rootValue: root,
graphiql:true
}));
app.listen(4000)本篇文章不做其实战介绍,可直接参考NestJS 官网搭建 GraphQL 教程以及其仓库有非常丰富并值得参考的相关代码:
Nest 提供了两种构建 GraphQL 应用程序的方法,代码优先和模式优先方法。您应该选择最适合您的。这个 GraphQL 部分的大部分章节分为两个主要部分:一个是如果你先采用代码,你应该遵循,另一个是如果你先采用模式,则应该使用。
在代码优先方法中,您使用装饰器和 TypeScript 类来生成相应的 GraphQL 模式。如果您更喜欢专门使用 TypeScript 并避免在语言语法之间切换上下文,则此方法很有用。
在模式优先方法中,事实来源是 GraphQL SDL(模式定义语言)文件。SDL 是一种在不同平台之间共享模式文件的与语言无关的方式。Nest 基于 GraphQL 模式自动生成您的 TypeScript 定义(使用类或接口),以减少编写冗余样板代码的需要。
优点
- 非常适合图形数据:深入链接关系但不适合平面数据的数据
- 请求的数据不多不少,按需请求,非常灵活
- 获取多个资源,只用一个请求
- 描述所有可能类型的系统。便于维护,根据需求平滑演进,添加或者隐藏字段(无需版本控制)
缺点
- 性能问题:GraphQL 以复杂性换取其强大功能。一个请求中包含太多嵌套字段会导致系统过载。因此,REST 仍然是复杂查询的更好选择。
- 缓存复杂性:由于 GraphQL 没有重用 HTTP 缓存语义,因此它需要自定义缓存工作。
- 一定的学习成本:没有足够的时间弄清楚 GraphQL 生态和 SDL,许多项目决定遵循众所周知的 REST 路径。
总结
| RPC | REST | GraphQL | |
|---|---|---|---|
| 组成 | 本地过程调用 | 6 项指导原则 | SDL |
| 格式 | JSON、XML、Protobuf、Thrift、FlatBuffers、 | XML、JSON、HTML、plain text | JSON |
| 学习成本 | 低 | 低 | 中 |
| 社区生态 | 丰富 | 丰富 | 正在丰富中 |
- RPC 适用于内部微服务,IO 密集的服务调用用 RPC,服务调用过于密集与复杂,RPC 就比较适用
- REST 具有 API 的最高抽象和最佳建模。但它在网络上往往更重、更固定(通常为了兼容会有冗余字段)
- GraphQL 在灵活获取数据上优势很大,但具有一定的学习成本。
最后
具体的 API 范式体会起来可能也是因人而异,上述的总结也可能有所偏差,欢迎友善讨论提出一些建议或者纠正一些错误