试下微调 GPT-3 做一个心理问答机器人
✨文章摘要(AI生成)
笔者在这篇文章中分享了如何利用 GPT-3 微调创建一个心理问答机器人。
- 首先,笔者选择了 Google Colab 作为开发环境,避免了复杂的本地环境配置
- 接着,笔者详细介绍了如何安装 OpenAI 命令行工具并设置 API_KEY,确保能够调用 GPT-3 服务
- 数据集的准备至关重要,笔者使用了两份公开的中文心理问答数据集,并将其转换为符合
jsonl格式的问答对 - 上传数据后,笔者通过简单的命令开始微调模型,并展示了如何在微调完成后进行调用
尽管结果尚可接受,但由于数据量较小,效果有限。最后,笔者表达了对未来 API 的期待,并回忆起学习 Python 的初衷。整个过程不仅展示了技术实现,也反映了笔者的学习与探索精神。
前言
最近,笔者做的一个小程序还差最后一个心理问答的功能,主要功能基本就完成了。我想偷个懒,那就调用别人的 API 吧,正好 GPT-3 非常火,那就试试?
准备
Colab
这是一个谷歌的线上 jupyter-notebook 网站,可以直接在上面运行 Python 代码,非常方便:
最好就用这个吧,环境啥的都配好了,笔者之前的电脑有许多 python 的环境,但换电脑之后就好久没写过 python 了,所以也偷个懒,不安装环境了...
顺便提一下,单纯 windows 好像不能使用 openai 的命令行工具,而一台 linux 服务器可以使用,但如果是国内的服务器就会被墙,需要在对应服务器上去想一些办法。
所以,推荐用这个...
openai 命令行工具
在jupyter的单元格里输入以下命令安装一个命令行工具,就和你npm i -g nest一样:
! pip install --upgrade openai
Successfully installed🎉🎉🎉
一个 API_KEY
在这里创建并复制保存就可以了
然后继续在刚才的jupyter下面将这个API_KEY导出为环境变量:
import os
os.environ['OPENAI_API_KEY'] = '<your api key>'
顺便提一下:新用户都有 18 美元的免费额度可以试用
数据集格式要求
首先,openai 官方文档上明确要求了传过去的数据集格式为jsonl格式的文件,就三点要求:
- utf-8 编码
- 每行为一个正确的 JSON 格式
- 换行符为
\n
没啥说的,如下是一个笔者的数据集截图:

然后,你可以使用这行命令来校验你的数据集格式是否正确:
openai tools fine_tunes.prepare_data -f "./2.jsonl"数据处理
如下是笔者的两个数据源(中文心理问答数据集,都是公开的(^_^)):
我们需要将这些数据处理里为问答对的模式,并遵循上面的jsonl格式:
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...由于数据标注得非常给力,笔者的数据集处理就非常简单了,基本没做什么复杂的转换...
处理第一个数据源
import json
from tqdm import tqdm
with open("./dataset/src/ques_ans1.json") as f:
file_contents = f.read()
# print(file_contents)
parsed_json = json.loads(file_contents)
print(len(parsed_json))
for item in tqdm(parsed_json):
question = item["ques_info"]["title"] + item['ques_info']['content']
for ans in item["answers_info"]:
if ans["recommend_flag"] == "推荐":
goodAns = ans["content"]
result = { "prompt": question, "completion": goodAns }
with open("./dataset/target/1.jsonl", "a") as f:
f.write(json.dumps(result) + "\n")非常简单的逻辑,就不过多介绍了,就是问题保留,答案只要是推荐,就与问题组成一个问答对,问题可是重复使用,直到答案用完;当然这段代码还有优化空间,但数据量不多,就算了。笔者懒😴
处理第二个数据源
import json
from tqdm import tqdm
with open("./dataset/src/EFA_Dataset_v20200314_latest.txt") as f:
lines = f.readlines()
for line in tqdm(lines):
parsed_line = json.loads(line)
question = parsed_line["title"]
for chat in parsed_line["chats"]:
label = chat["label"]
if "knowledge" in label and label["knowledge"] == True and label["negative"] == False:
goodAns = chat["value"]
result = { "prompt": question, "completion": goodAns }
with open("./dataset/target/2.jsonl", "a") as f:
f.write(json.dumps(result) + "\n")这里的逻辑也不难,只要答案是知识性的并且不是消极的,笔者就将其作为了一条问答对。
上传数据
然后我们将我们处理后的数据上传至Google drive进行持久化存储,你直接上传到 colab 也可以,不过断开连接后文件就消失了,你又要重新上传。
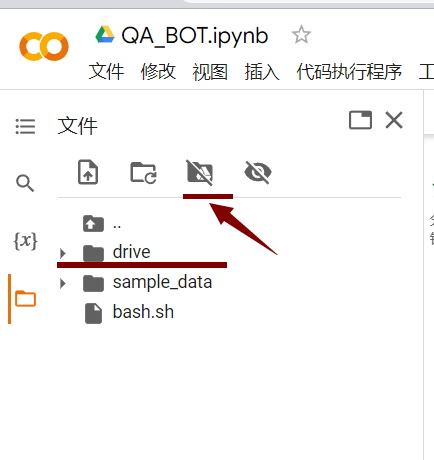
然后点击装载就会出现对应的文件夹,没有出来的可以点击附件的文件刷新按钮,然后就可以使用对应的文件了
开始微调
开始
然后,输入如下代码就可以开始微调了:
! openai api fine_tunes.create -t "/content/drive/MyDrive/2.jsonl" -m ada注意,笔者这里只上传了一个8MB的文件,就花了免费额度的 4 美元;如果你也是免费用户,使用时不能超过 15 美元,即数据集不能太大(笔者最开始就上传了全部数据集 254MB,就会报错)
-m 是你开始的基本模型的名称(ada、babbage、curie 或 davinci)。您可以使用后缀参数自定义微调模型的名称,ada 最便宜,最快,笔者这里尝试一下就是使用的这个参数。
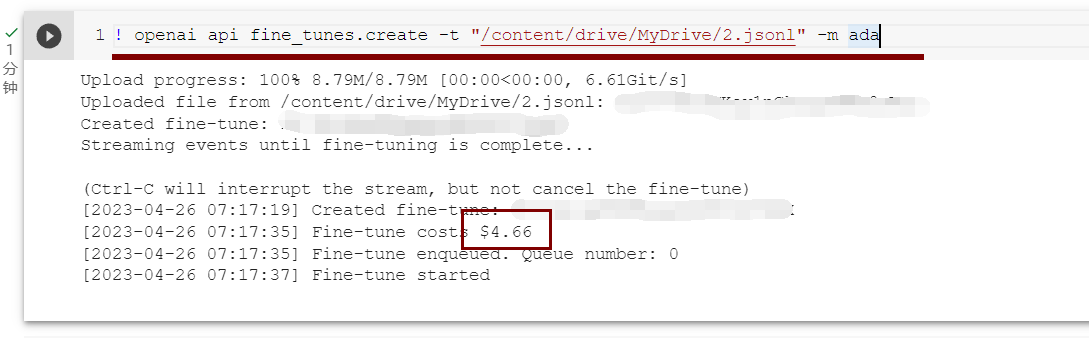
相关命令
微调过程中只要任务已经创建,就不会随这里 colab 的关闭而关闭,如下是恢复事件流的代码:
! openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>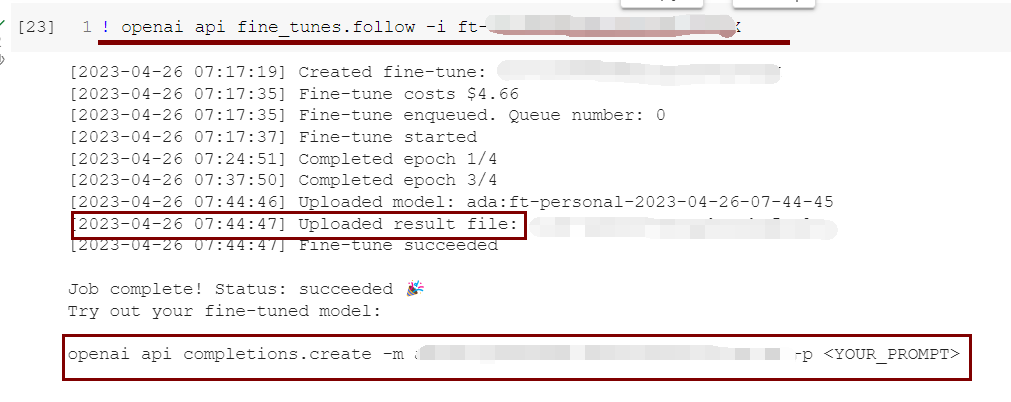 如上笔者等待了一段时间重新查看,它已经训练完成了,然后我们就可以输入最后一行给出的命令来演示结果
如上笔者等待了一段时间重新查看,它已经训练完成了,然后我们就可以输入最后一行给出的命令来演示结果
结果演示
这里还可以使用 python 进行调用,其他语言的使用方法见这
import openai
result = openai.Completion.create(
model="<your model>", # 上面截图最后一行我打码的那部分
prompt="我真的好累,压力超级超级大,周围人都在认真学习,我感觉我就是一个废物",
max_tokens=1000)
completion = result["choices"][0]["text"]
print(completion.encode("raw_unicode_escape").decode("unicode_escape"))这里最后是做了一个 unicode 编码转中文显示的操作;
如下是演示结果:
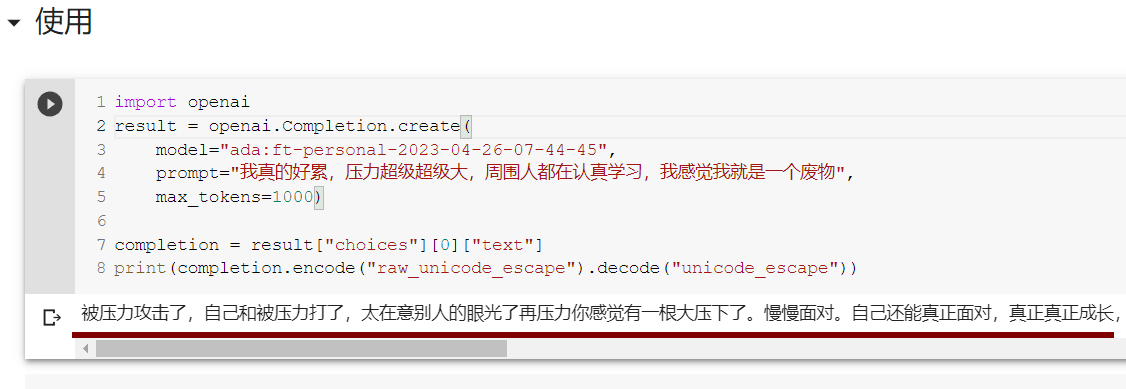
效果有点拉,不过也能接受,毕竟数据才 8MB,模型也是用的那个最快最便宜的。
最后
我等着阿里通义千问的 API 出来...等不及了🤔
再次编写 python 代码,彷佛回到了大一暑假刚学 python 的日子,那时候还在为 python 爬虫的 BUG 而烦恼。