Shedding Heavy Memories: Context Compaction in Codex, Claude Code, and OpenCode
✨Article Summary (AI Generated)
This article uses a 15,400-token login bug fix scenario to dissect the context compaction strategies of three mainstream CLI agents: Codex CLI, Claude Code, and OpenCode. Codex CLI takes a single-layer "handoff summary" approach; Claude Code employs a three-tier progressive mechanism — tool result trimming, Prompt Cache-friendly strategies, and a 9-section structured LLM summary; OpenCode implements "stepped governance" through non-destructive timestamp-based message hiding paired with a 5-heading LLM summary. The article reveals a core insight: the best context management isn't about endlessly expanding memory capacity, but learning to forget with precision.
When using AI agents for deep programming tasks, you've surely encountered this predicament: at first, the AI is sharp and responsive, hitting every mark; but as conversation turns accumulate, it seems to get progressively dumber.
When context is nearly exhausted, the AI rushes to finish, leading to poor results — the community calls this Context Anxiety, and just like us humans, haste makes waste. To keep the conversation going, the agent must shed some memories (compress — compact). But how to shed, what to shed, and how to recover afterward have become key markers of whether an agent runtime is truly mature.
Today, let's tear apart three mainstream CLI agents — Codex CLI, Claude Code, and OpenCode — and see how each performs their "compression magic" when facing the same login bug.
Note: This analysis is based on the open-source repository logic of Codex CLI and OpenCode, along with community reverse engineering and leaked source code verification of the Claude Code runtime.
Scenario Replay: A 15,400-Token Login Bug Fix
Imagine you're fixing a login endpoint returning 401 Unauthorized. You summon your AI agent and embark on an intense debugging session.
Here's the complete conversation log:
| # | Role | Summary | Est. Tokens |
|---|---|---|---|
| #1 | System | System prompt (40+ tool definitions) | ~800 |
| #2 | User | "Login page returns 401, help me debug" | ~100 |
| #3 | Assistant | "Let me search for auth-related logic" | ~150 |
| #4 | Tool Call | grep "auth" --include="*.ts" | ~50 |
| #5 | Tool Result | (50 search results returned) | ~2,000 |
| #6 | Assistant | "Found several hits, let me check auth.ts" | ~150 |
| #7 | Tool Call | read_file "src/auth.ts" | ~50 |
| #8 | Tool Result | (Full file content, ~300 lines) | ~3,500 |
| #9 | Assistant | "Found it — token validation doesn't handle expiry" | ~300 |
| #10 | User | "OK, but keep backward compatibility with old sessions" | ~80 |
| #11 | Assistant | "Got it, let me also check the middleware" | ~150 |
| #12 | Tool Call | read_file "src/middleware.ts" | ~50 |
| #13 | Tool Result | (Full middleware content) | ~2,500 |
| #14 | Assistant | "Middleware needs changes too, I'll handle it" | ~200 |
| #15 | Tool Call | edit_file "src/auth.ts" (patch) | ~100 |
| #16 | Tool Result | "Successfully applied." | ~30 |
| #17 | Tool Call | edit_file "src/middleware.ts" (patch) | ~100 |
| #18 | Tool Result | "Successfully applied." | ~30 |
| #19 | Assistant | "Code changes done, let me run the tests" | ~100 |
| #20 | Tool Call | bash "npm test" | ~50 |
| #21 | Tool Result | (3 tests failed with stack traces) | ~3,000 |
| #22 | Assistant | "3 tests failed, let me fix the test cases" | ~200 |
| #23 | Tool Call | edit_file "src/auth.test.ts" (patch) | ~150 |
| #24 | Tool Result | "Successfully applied." | ~30 |
| #25 | Tool Call | bash "npm test" | ~50 |
| #26 | Tool Result | (All tests passing, full output) | ~1,500 |
Just 26 messages, yet they've consumed roughly 15,400 tokens. The five bolded tool results (#5, #8, #13, #21, #26) alone total about 12,500 tokens — 81% of the total. This data was critical during debugging, but once the bug is fixed, it becomes dead weight in the context. If left uncleaned, the next conversation turn might overflow the window and lose the system prompt or the user's core requirements.
Codex CLI: Writing a Crisp "Handoff Memo"
OpenAI's Codex CLI (source, Rust implementation) takes an approach that feels very intuitive to humans: summarize and replace.
Its core idea can be captured in one sentence: hand the entire conversation to an LLM to write a "handoff summary," then replace the original history with that summary.
Dual-Path Design
Codex offers two compression paths:
- Local path (
compact.rs): The client calls an LLM to generate the summary, compatible with any model provider. - Remote path (
compact_remote.rs): Directly calls OpenAI's internal API endpointresponses/compact, letting the server handle compression. OpenAI models only.
Note that "local" and "remote" here don't refer to whether an LLM call is needed — both paths require LLM involvement. The difference is where the core "generate summary" step runs. In the local path, the client constructs the summarization prompt (loaded from the built-in template templates/compact/prompt.md), streams the LLM API call via ModelClientSession, and processes the returned result — the entire orchestration happens on your machine, so it works with any model provider. In the remote path, the client sends the prepared conversation history and tool definitions to OpenAI's compact_conversation_history endpoint for server-side summary generation — but the client is far from hands-off. Before the call, it trims overly long function call histories and builds the complete prompt object including tool specifications and system instructions; after the call, it filters the results (e.g., discarding stale developer role messages, keeping only genuine user and assistant content), restores ghost snapshots for /undo functionality, and recalculates token usage.
In short, the remote path only outsources the "compression" step to OpenAI's server — pre-processing and post-processing remain client-side. The advantage is that OpenAI's server likely has dedicated optimizations for this endpoint (such as more economical models or internal caching) that aren't available through the generic API. This reflects OpenAI's vertical integration of their own infrastructure.
The Compression Flow in Detail
When taking the local path, Codex first extracts recent user messages (hard-capped at ~20,000 tokens), then sends a brief summarization prompt to the LLM. This prompt has just 4 core points:
You are performing a "context checkpoint compression." Generate a handoff summary for another LLM that will continue the task, including: current progress and key decisions, important constraints and user preferences, remaining TODOs, and critical data needed to continue work.
The keyword is "handoff" — it's not writing meeting minutes, but a briefing that lets the next person (model) hit the ground running.
Applied to our login bug scenario:
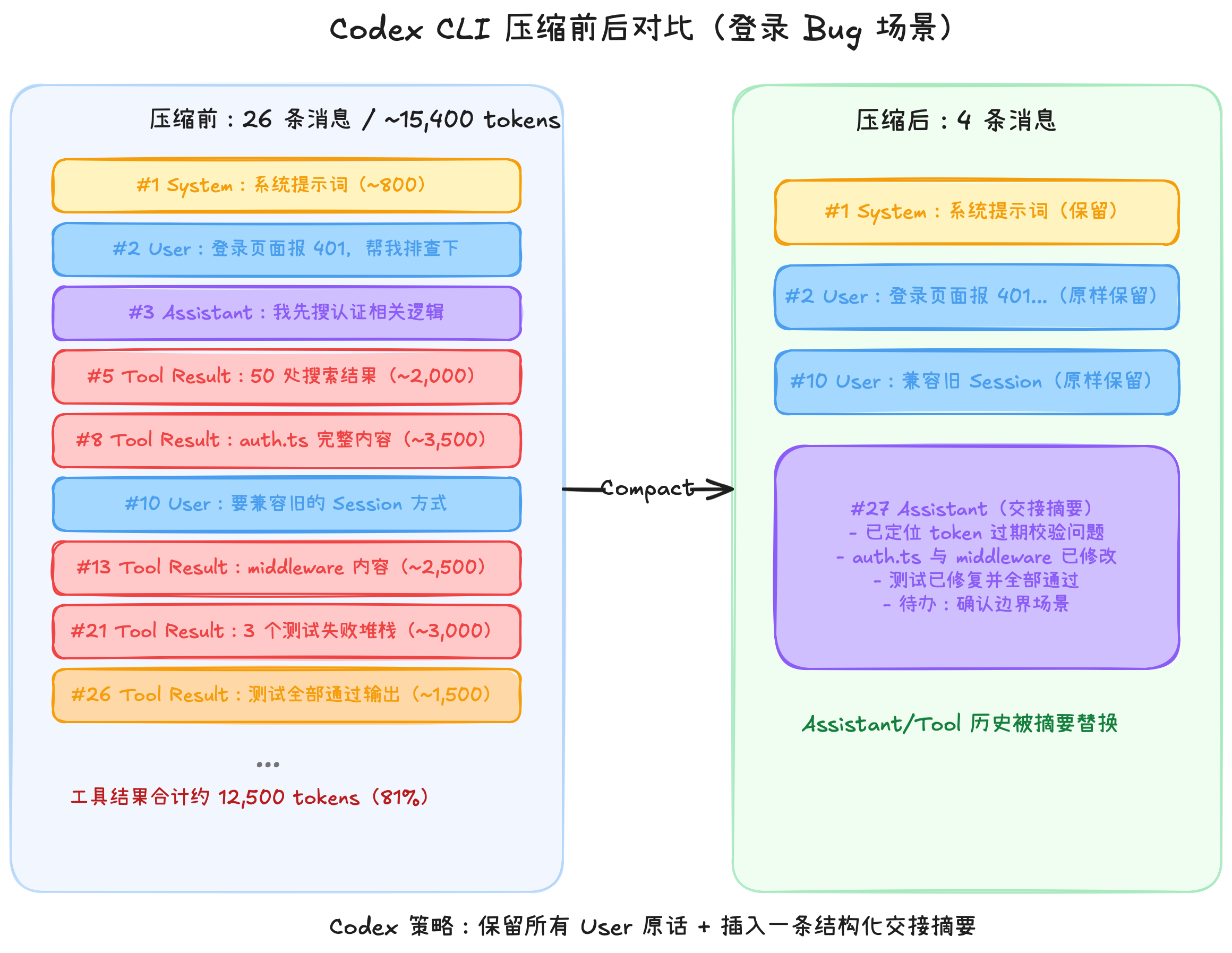
Breaking it down:
Notice the before-and-after — all messages collapse to just 4. Codex deeply respects "user intent": it physically deletes all assistant replies and tool-related messages, but preserves all user messages verbatim (#2 and #10).
It then inserts a fabricated assistant message containing a structured handoff summary. This summary includes the task objective, completed items, key architectural decisions, and remaining TODOs. For the new model, it doesn't need to see those massive file dumps and test stack traces — it just needs to know "the tests are fixed" and that's enough.
Auto-Trigger and Fallback
When token usage approaches the model's context window limit, Codex automatically triggers compression (no need for manual /compact). If space is still insufficient after compression, it falls back to more aggressive "head trimming" — chopping from the earliest messages to ensure the conversation can continue.
The biggest advantage of Codex's approach is its intuitiveness: the handoff summary concept is something every working professional understands. The downside is it's rather "all-or-nothing" — all AI replies and tool results get replaced by a summary, and if that summary misses a critical detail, it's truly gone forever.
Claude Code: Three-Tier "Precision Forgetting"
Anthropic's Claude Code takes a more nuanced approach. Rather than pursuing one-shot physical deletion, it designs three progressively stronger cleanup mechanisms — from light to heavy, avoiding LLM calls whenever possible.
Note: Claude Code is not open source. The following analysis is based on community reverse engineering and public materials; actual implementation may vary across versions.
Layer 1: Tool Result Trimming (Zero LLM Cost)
This is the most frequent and lightweight layer. No LLM call needed — it's purely a local rules engine that runs automatically before every request.
The logic is simple:
- Always protect the results of the most recent tool calls (active data can't be deleted)
- Older tool results beyond the protection window → replaced with
[Old tool result content cleared]placeholder
Applied to our scenario:
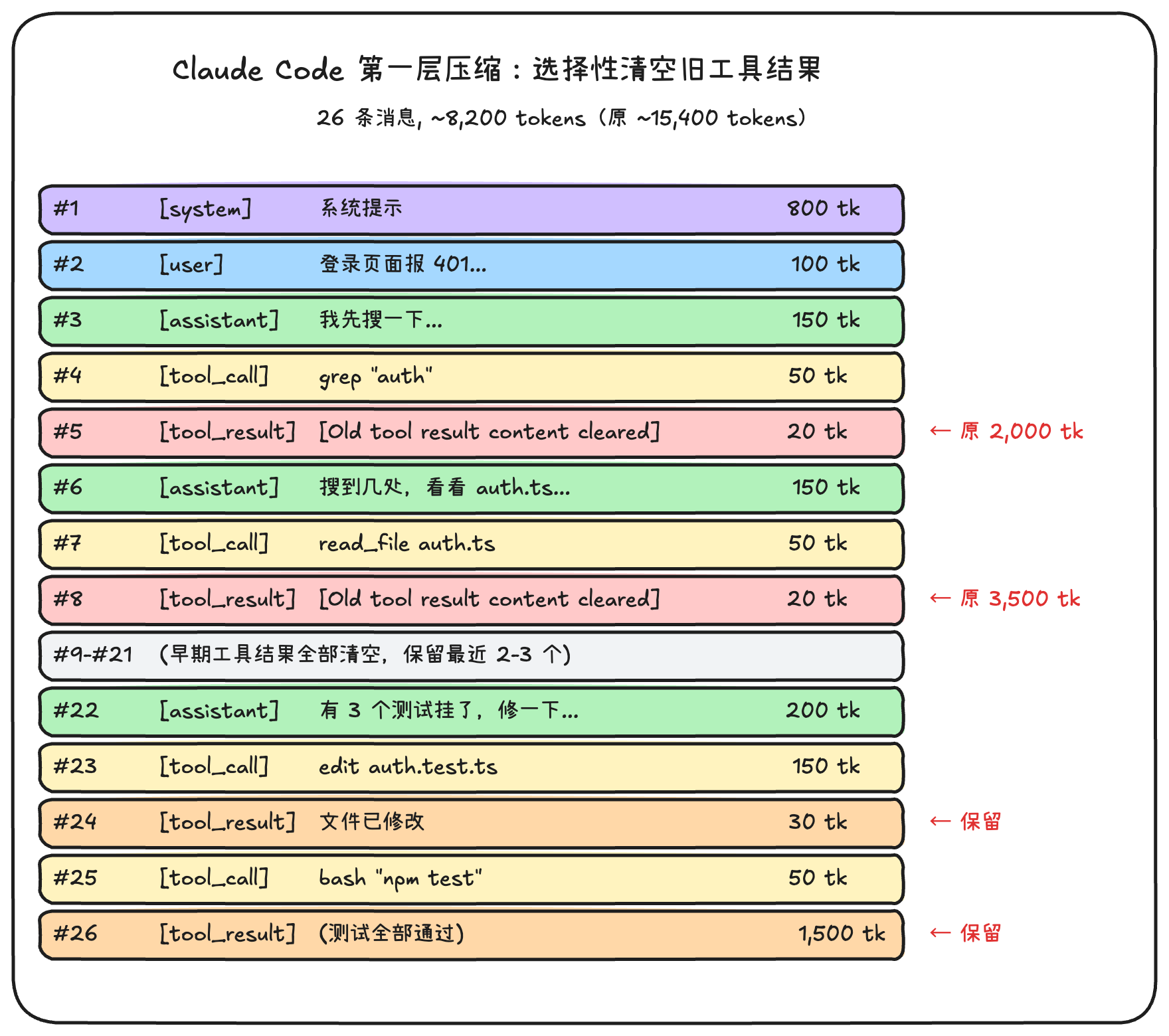
This approach is remarkably clever: it maintains the AI's "flow state." The AI remembers it searched the code (#4's tool_call is still there), and remembers it read files (#7's tool_call is still there) — it just doesn't remember what the search returned or what the file contained. If it truly needs to look again, it will simply re-issue a read_file.
I find this layer's design exquisitely elegant — it achieves "selective amnesia" rather than "total forgetting." Like remembering you read a great book last year but forgetting the specifics — you can always flip through it again when needed.
Layer 2: Cache-Friendly Strategy (Prompt Cache)
This is Claude Code's signature move, and the unique differentiating advantage among the three.
Anthropic's API supports Prompt Cache — if the prefix of your message to the API matches the previous request, the server can reuse prior computation results, dramatically reducing cost and latency.
What does this mean? When cleaning messages, Claude Code strives to avoid modifying the first half of the message sequence. It takes a "surgical" approach: trimming only at the tail, ensuring the beginning of the message sequence remains absolutely consistent. The trade-off is slightly lower cleanup efficiency, but the payoff is maximized cache hit rate.
Applied to our scenario. Suppose after Layer 1 cleanup, the message sequence is #1-#26 (tool results already replaced with placeholders). Context still exceeds the limit and needs further trimming. A "naive" approach would delete from the earliest messages — but Claude Code doesn't do that:
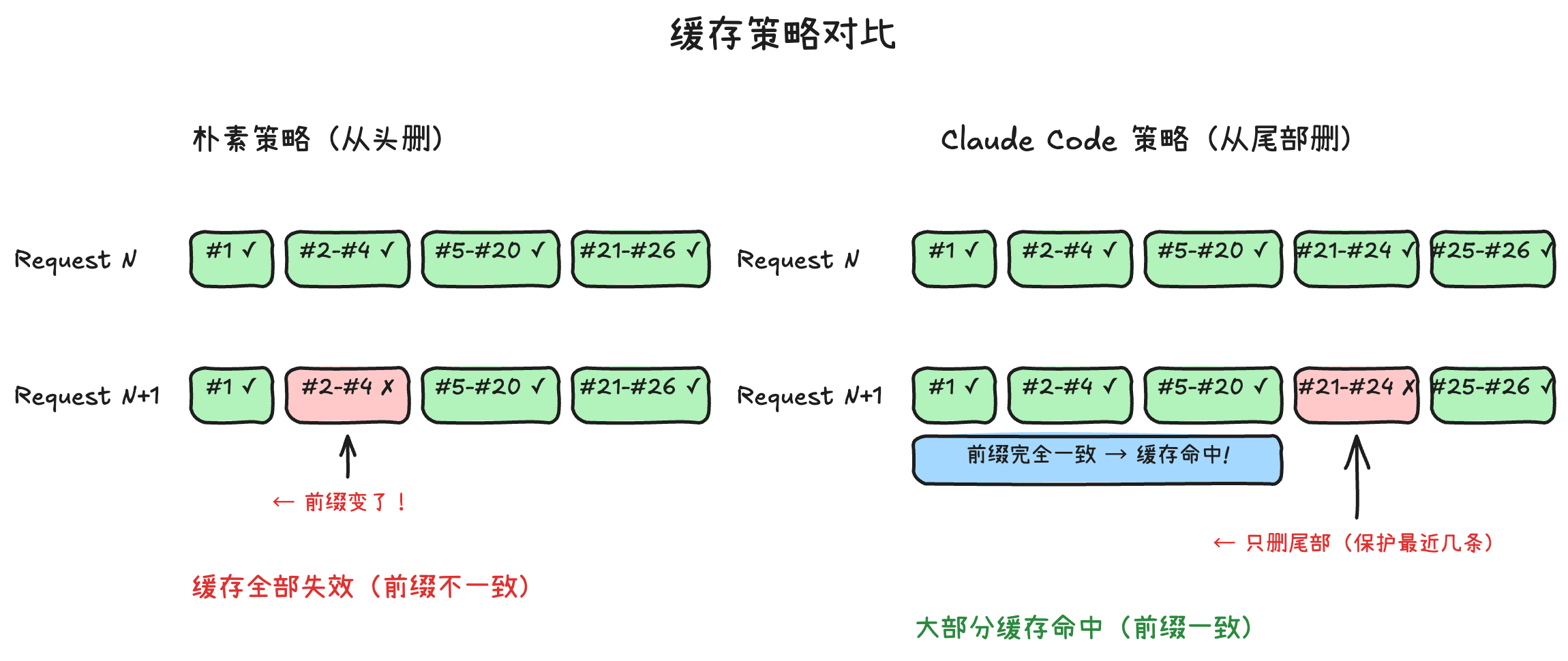
The naive strategy on the left deletes the oldest messages, which seems reasonable, but the cost is that the entire prefix changes — the API cache completely invalidates, and the next request must compute from scratch. Claude Code's strategy on the right is the opposite: it would rather delete less, as long as the prefix portion of the message sequence remains identical to the previous request, allowing Anthropic's Prompt Cache to hit.
For long-running tasks (like having the AI help you refactor an entire module), this strategy yields significant cost savings — because most of each API request's content can hit cache, and you only pay for the newly added tail content.
Layer 3: 9-Section Structured LLM Summary (Last Resort)
When the first two layers can't prevent context from continuing to grow, the system triggers a final full summary. According to the source code, the auto-compaction threshold is effective context window - 13,000 tokens (where effective window = model context window - min(max output tokens, 20,000)).
However, even when the threshold is reached, the system doesn't jump straight to an LLM summary. When auto-compaction triggers, the system first tries Session Memory Compact — leveraging structured information already in session memory to substitute for a full LLM call. This means most auto-compactions don't even need an LLM call. Only when the session memory path is unavailable or insufficient does the system fall back to the traditional LLM summary flow, generating a structured summary with 9 fixed sections:
- User's original intent
- Core technical concepts
- Files and code of interest
- Errors encountered and how they were fixed
- Problem-solving logic chain
- Summary of all user messages
- TODO items
- What's currently being worked on
- Suggested next steps
This summary has extremely strict requirements — the prompt demands the model directly quote key phrases from the original text rather than paraphrasing everything. This prevents "context drift" (the model subtly diverging from the original meaning during retelling).
Applied to our scenario:

After compression, Claude Code performs a series of post-processing steps — what I call "state reconstruction":
- Injects a lead-in at the beginning of the new conversation ("This session continues from a previous conversation...")
- Automatically re-reads recently edited files (up to 5 files, total budget 50,000 tokens, 5,000 tokens per file), ensuring the AI has the latest code
- Re-declares tool and skill definitions
- Project specifications in
CLAUDE.md, as part of the system prompt, remain permanently resident and are unaffected by compression
Users can also attach custom instructions during manual compaction, such as /compact Focus on API changes, to steer the compression toward a specific focus.
Additionally, there's a passive fallback path: when the API returns a prompt_too_long error, the system automatically initiates a reactive compression and retries the request, ensuring users don't encounter an abrupt error from context overflow. To prevent infinite loops from repeated compression failures, automatic compaction pauses after 3 consecutive failures.
Claude Code's approach is the most complex of the three, but also the most "cost-effective" — most of the time it only needs to execute the Layer 1 rules engine cleanup, or complete compaction via the Session Memory path, requiring no extra LLM calls at all.
OpenCode: Prune First, Summarize Later — "Stepped Governance"
The open-source newcomer OpenCode (source, TypeScript + Effect-TS implementation) offers a more balanced strategy. In session/compaction.ts, it implements a stepped governance flow: use low-cost measures to free up space first, and only call on the LLM when truly necessary.
Step 1: Prune (Mark as Hidden, Not Physical Deletion)
OpenCode's first move isn't deletion — it's "marking." The rules are crystal clear:
- Only execute when pruning can free more than 20,000 tokens (minor cleanups aren't worth the hassle)
- Always preserve the most recent 40,000 tokens as a "safety cushion" (active work can't be touched)
skilltype tool outputs are never pruned (they contain operational instructions)- Protect the full content of the last 2 user turns
Key design: Unlike Claude Code's placeholder replacement, OpenCode's pruning is not physical deletion. Instead, it stamps old messages with a compacted = Date.now() timestamp, making them "invisible" in subsequent requests. The data is still in the database — just hidden.

Key point: The data isn't truly lost. This leaves room for future history traversal features — if developers need auditing, or if the agent triggers some rollback logic, this data can be pulled back into context. This is a very forward-thinking design.
Step 2: LLM 5-Heading Summary
If things are still too bloated after pruning, OpenCode uses a hidden, dedicated agent (without disturbing the user's current interaction) to call an LLM and generate a summary. This summary follows a fixed 5-heading structure:

OpenCode has a wonderfully thoughtful design after summarization: it automatically replays the last user message. This ensures the agent's most recent memory point stays on the user's latest instruction, rather than on some cold summary text. The user is completely unaware that compression happened — your last message gets resent, the AI continues responding, as if nothing happened.
Another highlight: OpenCode follows the user's language. If you've been communicating in Chinese, its summary will also be in Chinese. For non-native English-speaking developers, this is a very friendly design.
I think OpenCode's approach is the most "developer-friendly" of the three — fully open-source code (TypeScript), modern architecture (Effect-TS), and the non-physical deletion design leaves ample room for extension. If you want to deeply customize compression behavior, OpenCode is the easiest to get started with.
The Three Musketeers Face Off
Let's put all three approaches side by side:
Input: 26 messages, ~15,400 tokens (same "fix login bug" scenario)
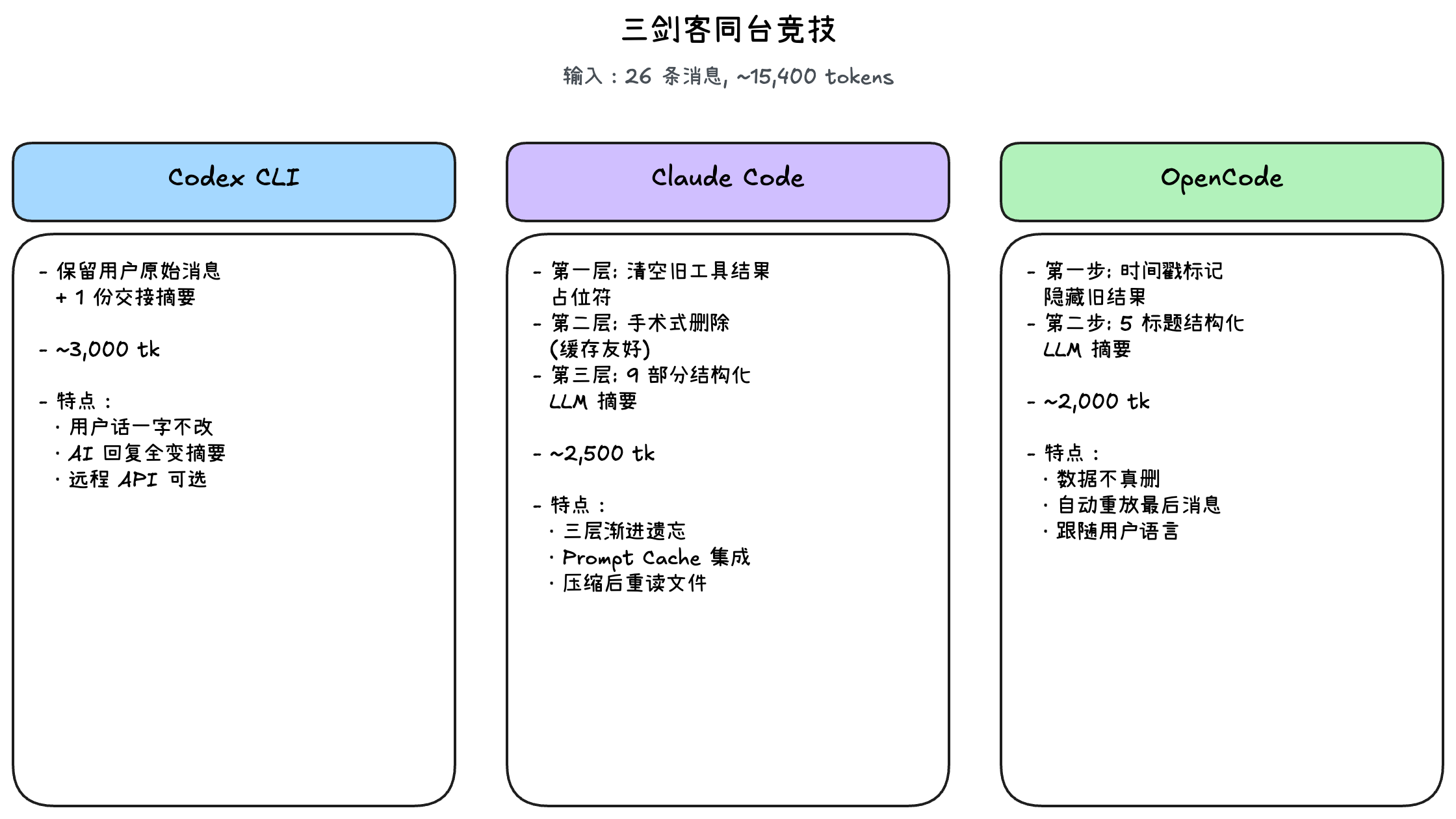
| Dimension | Codex CLI | Claude Code | OpenCode |
|---|---|---|---|
| Compression Layers | Single (summary) | Three (trim/cache/summary) | Two (hide/summary) |
| LLM Calls | Required | Only at Layer 3 | Only at Step 2 |
| User Messages | Permanently preserved verbatim | Summarized (Layer 3) | Summarized + last message replayed |
| Tool Result Handling | Physical deletion | Placeholder replacement | Timestamp-based hiding |
| Cache Optimization | No special design | Deep Prompt Cache integration | Focused on reducing redundant reads |
| Post-Compression Behavior | Passive waiting | Proactive re-reading of relevant files | Auto-replay of last instruction |
Differences Worth Expanding On
On whether to preserve user messages verbatim: Codex chooses to keep user messages intact, compressing only model responses. The advantage is that the AI can always look back at what you said, but the cost is reduced compression efficiency when user messages themselves are lengthy. Claude Code and OpenCode choose to compress everything into summaries — more aggressive but more space-efficient.
On caching: This is Claude Code's most unique advantage. The other two see significant changes in API request content after compression, essentially invalidating previous caches. Claude Code deliberately maintains prefix stability, allowing post-compression requests to still reuse prior caches. For long-running tasks, this translates to meaningful cost savings.
On non-physical deletion: OpenCode's timestamp marking approach is a forward-thinking design. While the current version doesn't implement history traversal, the data isn't truly lost, leaving the door open for future possibilities. Both Codex and Claude Code's compressions are irreversible.
Final Thoughts
If I were to describe these three with an analogy:
- Codex CLI is like a senior employee writing a handoff memo. They tear up the previous drafts and hand you a clear status report — blunt but effective.
- Claude Code is like a scholar with the ability to forget with precision. They first erase minor annotations in their books, and only when the bookshelf truly can't hold any more do they condense entire books into one-page outlines. They care deeply about the efficiency of flipping through books (caching).
- OpenCode is like a pragmatic stepped governance administrator. They first box up old files and label them (hide), and only summarize when absolutely necessary. Their most thoughtful touch? After summarizing, they remind you: "The last thing you said was about this, right?"
Ultimately, in 2026, the best context management isn't about endlessly expanding an LLM's memory capacity, but learning how to forget with precision. After all, an agent that remembers everything is often the one most easily distracted by noise.
References:
- Codex CLI: openai/codex (see
codex-rs/core/src/compact.rs) - Claude Code community resources:
- Claude Code System Prompts
- Sam Saffron's Gist
- Claude Code's Compaction Engine
- Leaked source repository (unofficial leak, used for verification)
- OpenCode: anomalyco/opencode (see
packages/opencode/src/session/compaction.ts)