scrapy 爬虫详解
✨文章摘要(AI生成)
笔者在这篇博客中详细介绍了 Scrapy 爬虫的基本原理及其运行过程。首先,笔者阐述了爬虫的基本工作流程,包括身份验证、数据请求、数据解析及保存数据的步骤。接着,笔者重点讲解了 Scrapy 框架的 5+2 结构组件,包括引擎、调度器、下载器、数据管道、爬虫、中间件等,强调了各组件的功能及其在爬虫工作中的重要性。通过图示,笔者进一步解释了数据从请求到保存的整个流程,让读者对 Scrapy 的操作有了更深的理解。此外,笔者还提供了安装 Scrapy 及创建项目的实战指导,鼓励小白用户勇于尝试,最终通过实例和源码链接引导读者深入学习。
爬虫的原理
废话:这个月前几天才开学,事比较少,所以就自学了一下 scrapy 来爬取 B 站文章以及标题,后面感觉数据不够,就又爬了每篇文章的点赞数以及评论观看投币数等等来做 NLP 中的训练;
我们先简单讲一下爬虫的原理,但不细讲,知道就行,因为后面是直接用框架,然后你遇到问题再去查印象会更深;
整个程序运行的过程
- 表明自己的身份,我是谁(headers),我在哪(ip 地址),我要干什么,当然是爬数据了~
- 有了这些信息,下一步当然就是干最重要的事了,请求数据(request)从服务器中获取数据并返回(response),你问服务器为什么要给你数据,因为你是用户啊,服务器就是给用户服务的,我们之前是伪装了用户的身份信息的,但如果你是 python 的身份信息,那它当然不会给你数据(解决反爬机制)
- 返回的信息是一大堆数据,这些东西可以通过浏览器的渲染排好版地展示再用户地面前,但是我们当然不可能每次都通过浏览器来人工地处理数据,所以需要使用一种规则来获取我们想要的数据(这里地数据每次地格式是差不多的,如果有差别需要重新设计规则)比如:正则表达式、xpath、css 选择器等等,当然,这些都是针对静态数据,动态数据需要我们去浏览器手动分析,这里大概了解就行,后面会继续讲解;
- 最后就是忙活了这么久,收获的时候了(保存数据),选择合理的保存方法对后面处理这些数据是很关键的,但其实影响也不会太大,大多数也都可以后面相互转换,常见的方法就是 txt、csv、json 等格式,或者直接保存到数据库里面;
注: 这里涉及到很多专有词,如果你才接触爬虫的话,对于这些是很陌生的,请不要被吓着,这些词汇百度一下一两句话你就懂了,而且后面也会在例子中尽量讲到
介绍 scrapy 的运行过程
如果你在上面对爬虫爬取的过程还有点模糊的话,那么这里就能加深你的理解了,毕竟 scrapy 框架也是爬虫,原理是一致的,只是功能多了不少,在这么多功能的前提下,我们仅仅只需要遵守它的编程规则就可以了话不多说,看图: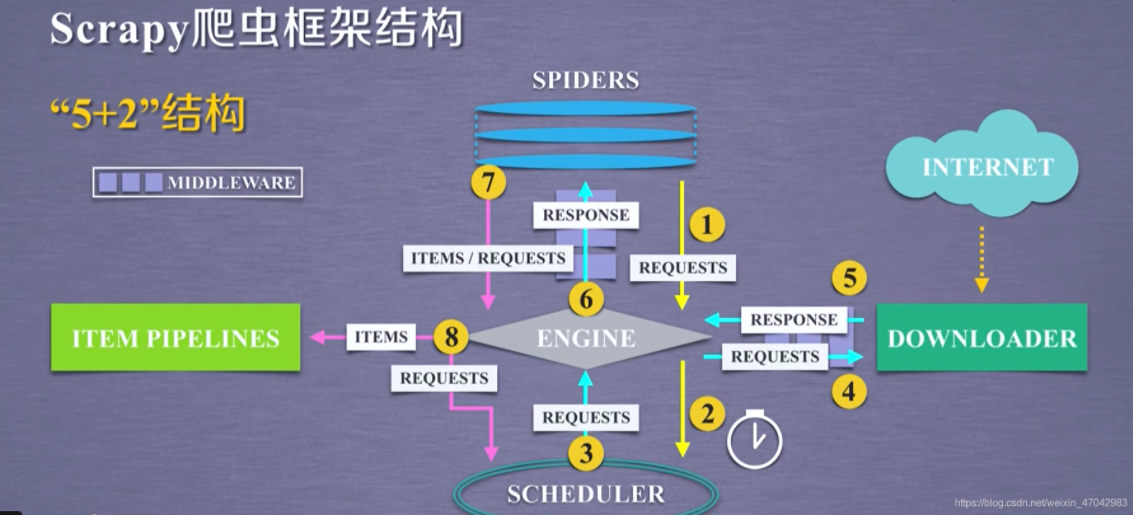
先介绍它的 5+2 结构的组件
- ENGINE:这个可以说是最重要但也最不重要的组件了,一方面是因为所有其他的组件都是通过这个引擎来进行活动的,另一方面是这个我们是不用对其进行任何操作的,真好~
- SCHEDULER:爬虫的时间调度器,因为 scrapy 是自带多线程异步爬取的,你问我多线程是什么,一个字“快”
- DOWNLOADER:下载器,去服务器获取数据,相当于整个框架的前线士兵;
- ITEM PIPELINES:前面不是说了最后一步是保存数据码,这个地方就是 scrapy 框架给我们来保存数据的地方;
- SPIDER:设置爬虫的地方
- MIDDLEWARE:中间件(自带有两个中间件,也可以自己创建中间件,需要遵循规则,这篇文章不会细讲)本来上面五个结构就能满足我们爬取数据的需求,但是由于一些反爬机制或者其他的原因,比如 url 本来就是没数据的等等,而导致我们的程序被终止,这显然是不具有鲁棒性的,不够灵活,所以 scrapy 就增加了这两个中间键让用户自定义处理一些异常等
- 6 包含两个组件,从图中我们可以看出这两个组件只是处理的地方不同而已,一个是在形成爬虫那里,一个是在下载数据那里
过程
其实图中已经很详细了,不过咋们是保姆级教程,所以再来解释一番: 1-4:爬虫通过引擎调动时间表去网页下载内容,里面是通过 requests 完成的; 5-6:返回内容并交给爬虫里面的 parse 方法进行解析获取自己想要的内容; 7-8:保存内容,item 是你要保存内容的对象(就是学生:姓名、学号这些) pipline 就是保存你设计的 item 对象为某种格式;
挺简单的,后面看了代码你的整体逻辑会更加清晰
实战开始~
如果你真的是小白小白,安装 anaconda3 -> 创建环境(conda create -n <环境名> python=3.7)-> pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple 好吧,现在开始实操->
激活你的环境(我的爬虫环境名为 EasyTitle,这里我是在 VSCODE 里面使用的终端,你也可以在任何编译器里面这样做,anaconda 自带很多编译器,也可以使用 anaconda_promapt,同时你也要选择之后项目所在的位置,就是路径: cd <路径名>):  ) 创建项目 在终端输入 scrapy startproject bili , 其中 bili 是我的项目名
) 创建项目 在终端输入 scrapy startproject bili , 其中 bili 是我的项目名  然后,你的该目录下就会出现一个 bili 的文件夹,这就是 scrapy 工作的地方,cd bili 进入这个文件夹(这步就不展示图了);该文件夹如下
然后,你的该目录下就会出现一个 bili 的文件夹,这就是 scrapy 工作的地方,cd bili 进入这个文件夹(这步就不展示图了);该文件夹如下 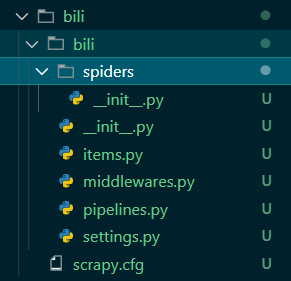 接下来就是重点了,打好精神~ bili 项目下分两个文件< bili >< scrapy.cfg >,bili 里面有 spider、items、middlewares、piplines、setting 这些文件或文件夹(不提 init)
接下来就是重点了,打好精神~ bili 项目下分两个文件< bili >< scrapy.cfg >,bili 里面有 spider、items、middlewares、piplines、setting 这些文件或文件夹(不提 init)
- spider 文件夹里面是装着你的爬虫,后面生成的爬虫都会存放在该目录
- items 容器设计你的保存对象
- pipline 保存内容到文件
- miiddleware 自定义处理可能会出现的一些异常情况
- settings 一些设置,比如启动关闭 middleware,设置每次爬取的延时时间等等 基于上面的理解,我们我们来一步步分析: 首先生成我们的一只爬虫:
(后续更新)算了,懒得写了,直接看源码吧:https://github.com/Justin3go/Bili_Spider-bili_dataset-