我把 Harness Engineering 也提炼成了 SKILL
✨文章摘要(AI生成)
笔者分享了将 Harness Engineering 知识提炼为可复用 Agent Skill 的经验。在系统阅读了 Anthropic、OpenAI、Martin Fowler、LangChain 等来源的文章后,提炼出 Harness 设计的七个核心层:项目搭建、上下文工程、约束与防护、多 Agent 架构、评估与反馈、长时间任务、诊断。最终产出的 harness-engineering 技能覆盖三大场景——新项目搭建、Agent 行为诊断、持续改进,采用渐进式披露架构。定量评估显示有技能时断言通过率 100%,无技能时 83%。核心洞察:Agent 表现不好,80% 的原因不在模型,在 Harness。
为什么写这个
最近两年,笔者在使用各种AI编码助手(Claude Code、Cursor、Copilot等)的过程中,反复遇到一个问题:Agent时好时坏,虽然整体来说随着模型能力进步是向好的,但是向好的过程是曲折波动的。
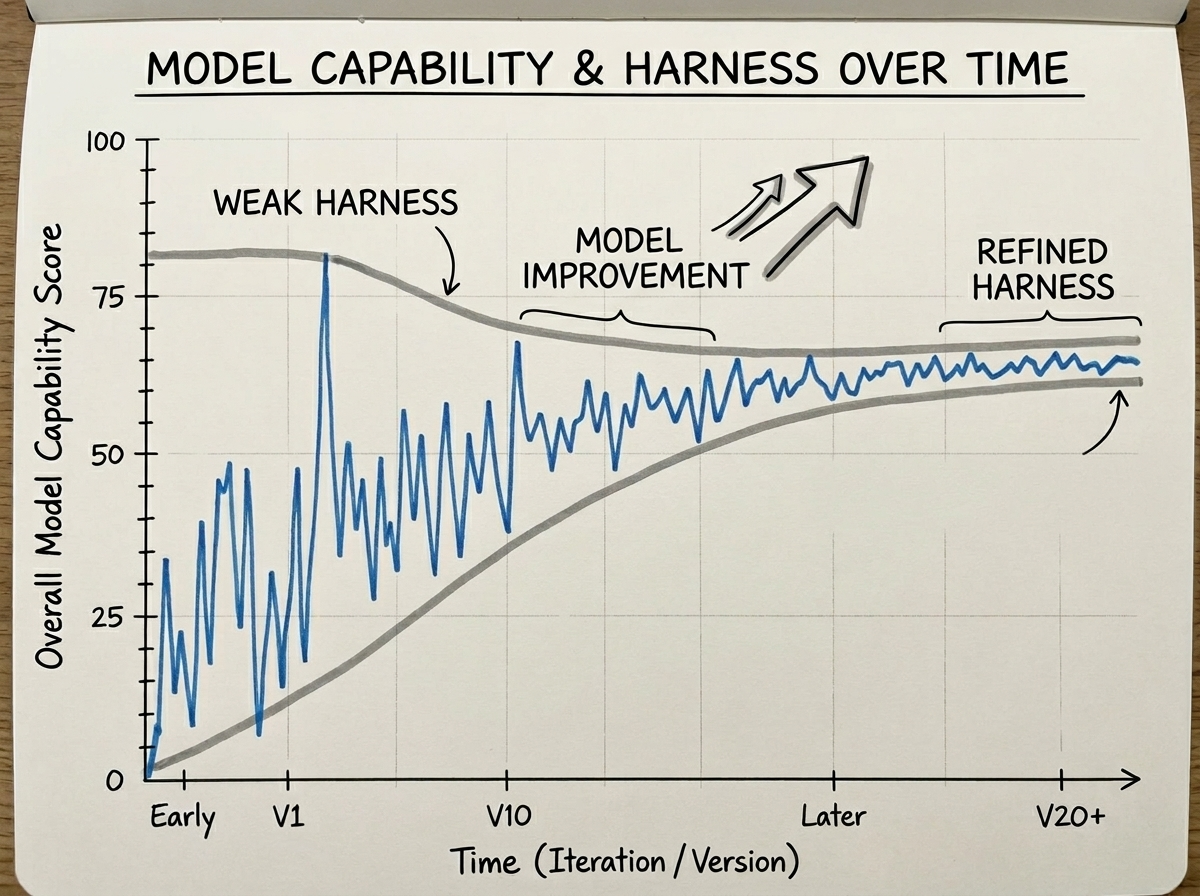
有时候它写的代码完美契合项目风格,有时候它像个第一天入职的实习生——不知道项目结构、不遵守约定、还把之前商量好的决策忘得一干二净。
然后开始从 Prompt Engineering 中使用结构化、few shot、few example 等技巧,来让 AI 的输出更加稳定。 后面又使用 Context Engineering 来让 Agent 的上下文更加丰富,来让 Agent 的表现更加稳定。
最近几周,一个更系统的词汇出现了:Harness Engineering。
Agent表现不好,80%的原因不在模型,在Harness。 - Anthropic
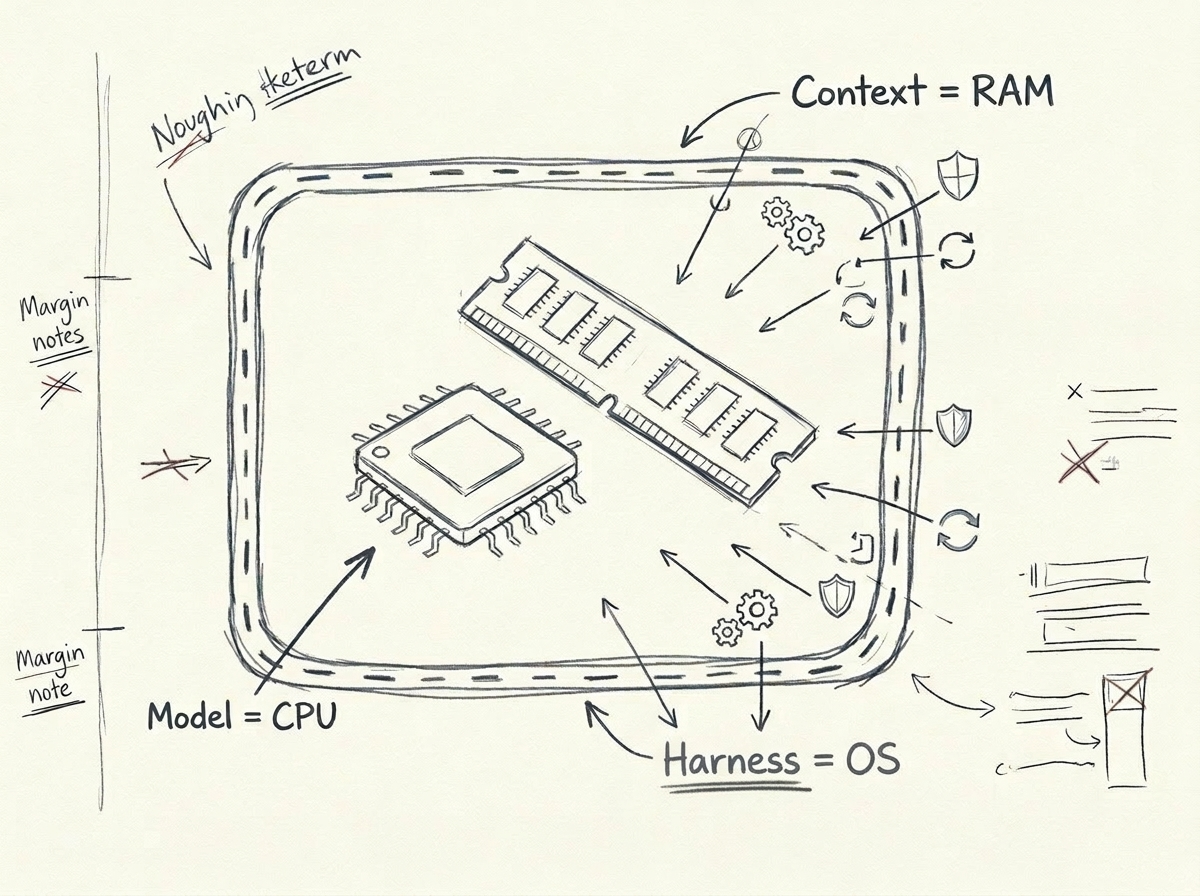
什么是Harness?简单说:
- 模型 = CPU(算力本身)
- 上下文窗口 = RAM(工作记忆)
- Harness = 操作系统(调度、约束、反馈、文件系统——一切让CPU有效工作的基础设施)
你不会指望一个CPU在没有操作系统的裸机上高效运行。同理,你也不该指望一个模型在没有Harness的项目里稳定输出。
我学到了什么
笔者系统阅读了以下来源的文章:
- Anthropic — 构建高效Agent、多Agent研究系统、长时间运行Agent的Harness设计
- OpenAI — AGENTS.md设计模式、Context Engineering最佳实践
- Martin Fowler — Harness Engineering的工程哲学("Relocating Rigor")
- LangChain — Agent框架 vs 运行时 vs Harness的分类学
- philschmid — 2026年Agent Harness的重要性
- 独立开发者实践 — Hermes Agent的自演化、Vue Lynx的设计笔记驱动开发
- 学术论文 — 自然语言Agent Harness的形式化研究
读完之后,我发现这些文章虽然角度各异,但核心思想收敛到了七个层:
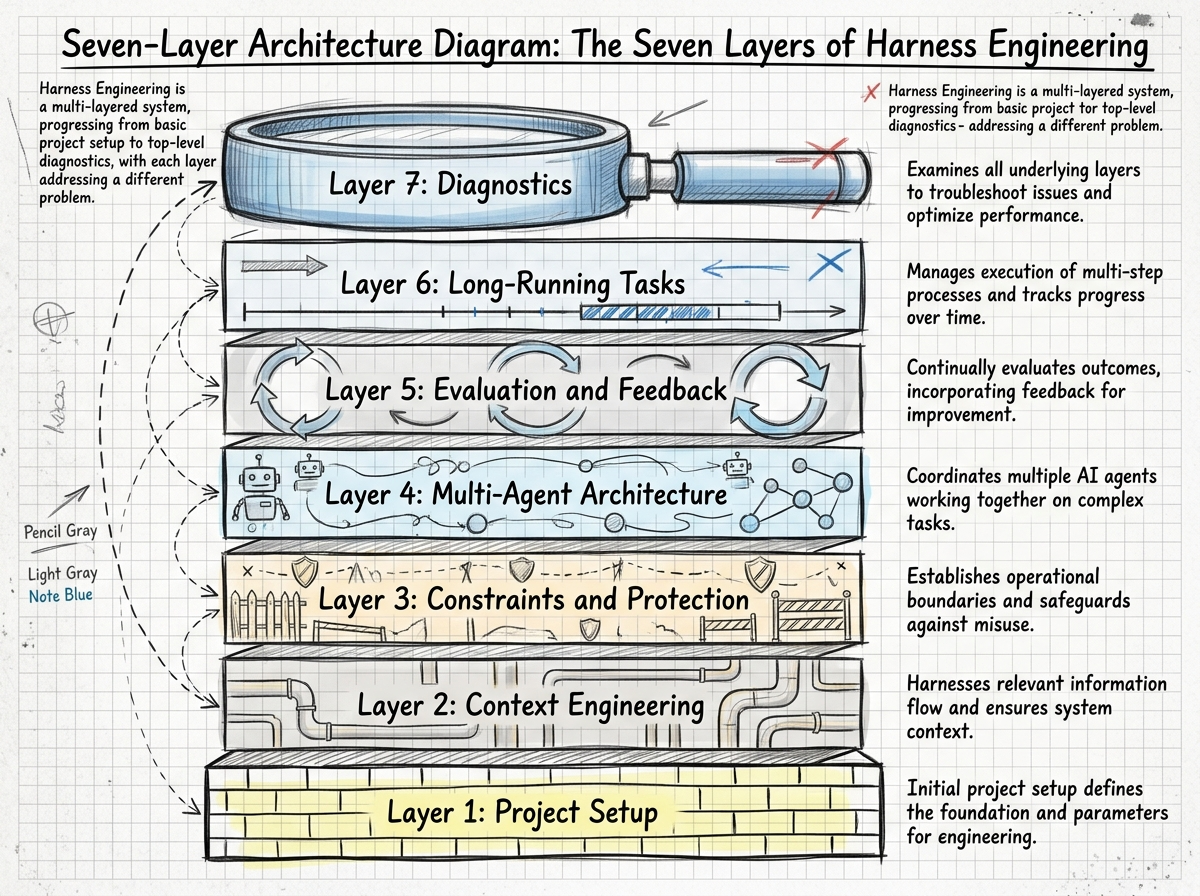
| 层级 | 解决什么问题 | 一句话总结 |
|---|---|---|
| 项目搭建 | Agent不知道项目是什么 | AGENTS.md是目录,不是百科全书 |
| 上下文工程 | Agent看到的信息不对 | 给地图,不给手册 |
| 约束与防护 | Agent犯重复的错 | 每犯一次错,加一条规则 |
| 多Agent架构 | 单Agent搞不定复杂任务 | 分工明确,协议清晰 |
| 评估与反馈 | 不知道Agent做得好不好 | 让AI检查AI |
| 长时间任务 | Agent跑着跑着就走偏了 | 进度文件 + 上下文重置 |
| 诊断 | 用户骂Agent不好用 | 问题在Harness,不在模型 |
所以我做了个技能
读完这些文章,笔者意识到这些模式完全是可复用的。不管你的项目是React前端、Python后端还是Rust CLI工具——Harness的设计原则是通用的。
于是我把这些知识提炼成了一个 Agent Skill,名叫 harness-engineering。
它做什么
这个技能有三个核心使用场景:
场景一:新项目搭建
当你启动一个新项目,告诉Agent"帮我搭建Harness工程",它会:
- 评估你的项目类型、技术栈、团队规模
- 创建
AGENTS.md(表of目录式的Agent导航文件) - 建立
docs/目录(架构、约定、数据模型等) - 配置约束层(lint规则、类型检查、pre-commit hooks)
- 设置评估与反馈机制
场景二:Agent表现不佳时的诊断
这是最有意思的场景。当你开始抱怨——
- "它怎么又犯同样的错误?"
- "它根本不遵守我们的约定!"
- "它写的代码质量太差了"
这个技能会被触发,引导Agent去诊断Harness层的缺失,而不是怪模型:
| 你的抱怨 | 大概率原因 | 修复方式 |
|---|---|---|
| 总犯同一个错 | 没有约束阻止它 | 加一条lint规则 |
| 不遵守约定 | 约定没写下来或Agent找不到 | 写入docs/,在AGENTS.md中引用 |
| 忘记之前的决定 | 跨会话上下文未持久化 | 用progress.md记录决策 |
| 代码质量差 | 没有好代码的示例 | 在DESIGN_NOTES.md中加示例 |
场景三:持续改进
每次发现新的可复用Harness模式,更新到技能中,让它在其他项目中也能受益。
它怎么组织的
技能采用渐进式加载架构:
harness-engineering/
├── SKILL.md # 入口文件(<60行),路由到具体参考文档
└── references/
├── 01-project-setup.md # 项目搭建
├── 02-context-engineering.md # 上下文工程
├── 03-constraints.md # 约束与防护
├── 04-multi-agent.md # 多Agent架构
├── 05-eval-feedback.md # 评估与反馈
├── 06-long-running.md # 长时间任务
└── 07-diagnosis.md # 诊断SKILL.md本身非常精简——它就像一个路由器,根据当前场景指引Agent去读对应的参考文档。这遵循了Harness Engineering本身的原则:渐进式披露,按需加载。
几个让我印象深刻的模式
有几个模式特别触动笔者,感同身受,这里单独拿出来聊聊。
"给地图,不给手册"
这个观点从推文中看到。传统做法是给Agent写详细的分步指令(手册),但这让Agent变得脆弱——任何偏差都会导致它不知所措。
更好的做法是给Agent一张地图:
# 不好的写法(手册)
Step 1: 打开 src/auth/login.ts
Step 2: 找到 handleLogin 函数
Step 3: 在第42行添加...
# 好的写法(地图)
Auth系统在 src/auth/。登录流程:login.ts → validate.ts → session.ts。
限流中间件在 src/middleware/rateLimit.ts——参考它的模式。
每次修改auth都要在 src/auth/__tests__/ 里加测试。地图让Agent能自主导航,手册让它成为脆弱的执行机器。
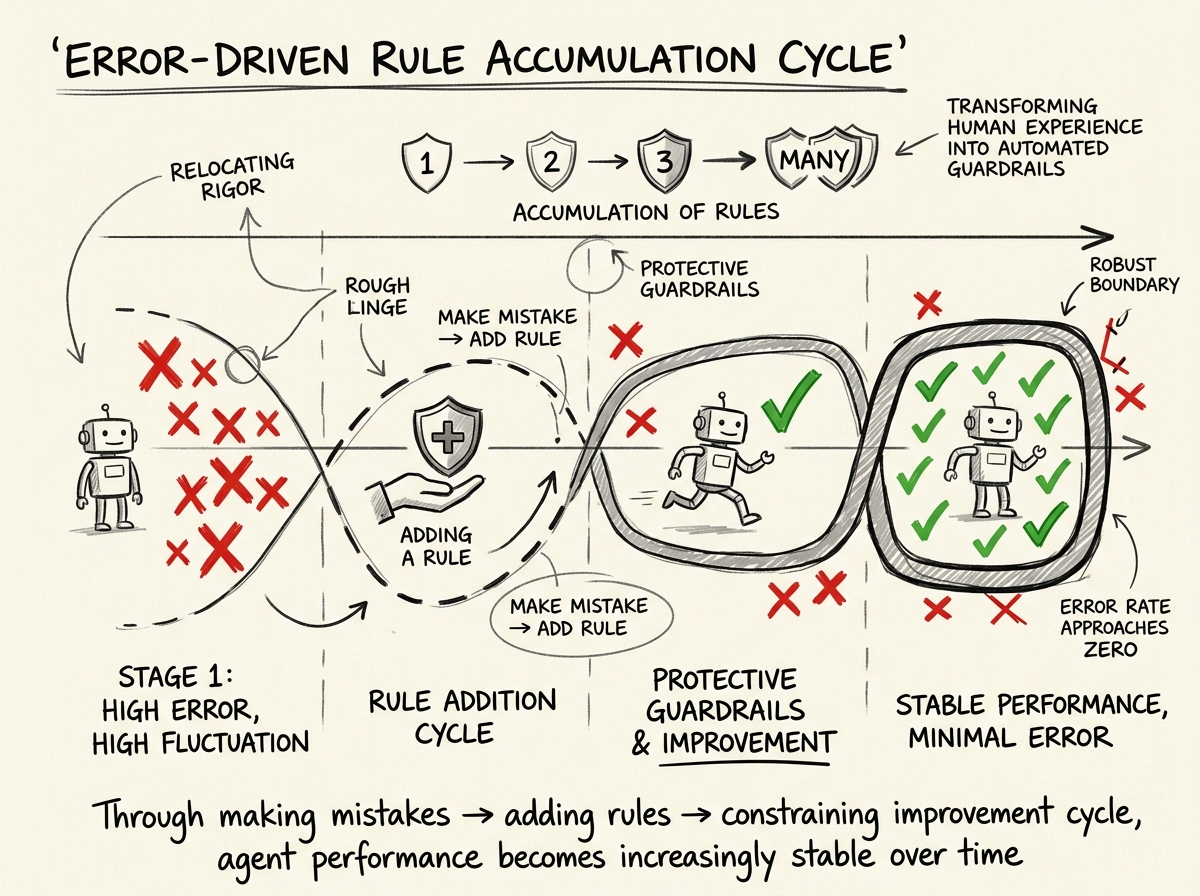
"每犯一次错,加一条规则"
这个模式来自多篇文章的交叉验证。核心思想:
- Agent犯了一个错
- 你修复了这个错
- 然后你加一条规则,永远阻止这类错再次发生
这条规则可以是lint规则、类型约束、测试用例,或者只是文档中的一条约定。随着时间推移,Harness积累了越来越多的规则,Agent的错误率对已知模式趋近于零。
这其实就是Martin Fowler说的 "Relocating Rigor"——把人类通过Code Review、经验、直觉实施的质量把关,迁移到自动化检查中。Agent在被检查的边界内自由运行。
Harness = 数据集
这个观点来自Anthropic。每次Agent交互都是一个训练信号:
- 它尝试了什么
- 什么成功了
- 什么失败了
- 修复方案是什么
这些痕迹(traces)就是你的竞争优势。它们是让你的Harness随时间越来越好的数据——不是微调模型,而是优化操作系统。
技能评估:有没有用?
笔者遵循skill-creator的流程,对这个技能做了定量评估。设计了3组测试场景,每组跑with-skill和without-skill两个版本:
| 测试场景 | 有技能 | 无技能 |
|---|---|---|
| 新项目搭建 | 6/6 ✅ | 4/6 |
| Agent行为诊断 | 6/6 ✅ | 5/6 |
| 跨模块依赖问题 | 6/6 ✅ | 6/6 |
| 合计 | 18/18 (100%) | 15/18 (83%) |
有技能的版本在所有场景下都通过了全部断言。无技能的版本在"新项目搭建"场景下缺失较多——它不知道要创建AGENTS.md、不知道docs/应该怎么组织、不会设置渐进式披露的上下文架构。
当然,17%的差距不算巨大。但关键是:有技能时Agent的输出一致且完整,无技能时看运气。对于一个工程实践类技能来说,一致性比偶尔的惊艳更有价值。
怎么安装
这个技能可通过 GitHub 安装:
npx skills add 10xChengTu/harness-engineering安装后,当你在Claude Code、OpenCode或其他支持Skills的Agent中工作时:
- 启动新项目 → 技能自动触发,引导搭建Harness
- 遇到Agent质量问题 → 开始抱怨时技能会介入诊断
- 主动询问 → "帮我改进这个项目的Harness"
最后
Harness Engineering目前还是一个非常早期的领域。模型在变强,今天需要的约束明天可能就多余了——所以这个技能本身也遵循一个核心原则:为删除而构建。
如果你也在用AI Agent做开发,不妨试试给你的项目加上Harness。从最简单的开始——一个AGENTS.md文件、几条lint规则、一个progress.md。然后观察Agent的表现变化。
你大概率会和笔者有同样的感受:不是模型不行,是我们没给它一个好的工作环境。
本文涉及的所有参考文章和完整技能源码,均可在GitHub 仓库中找到。