DRF学习笔记
restful介绍
1,web应用模式(了解)
目的: 知道web开发的两种模式
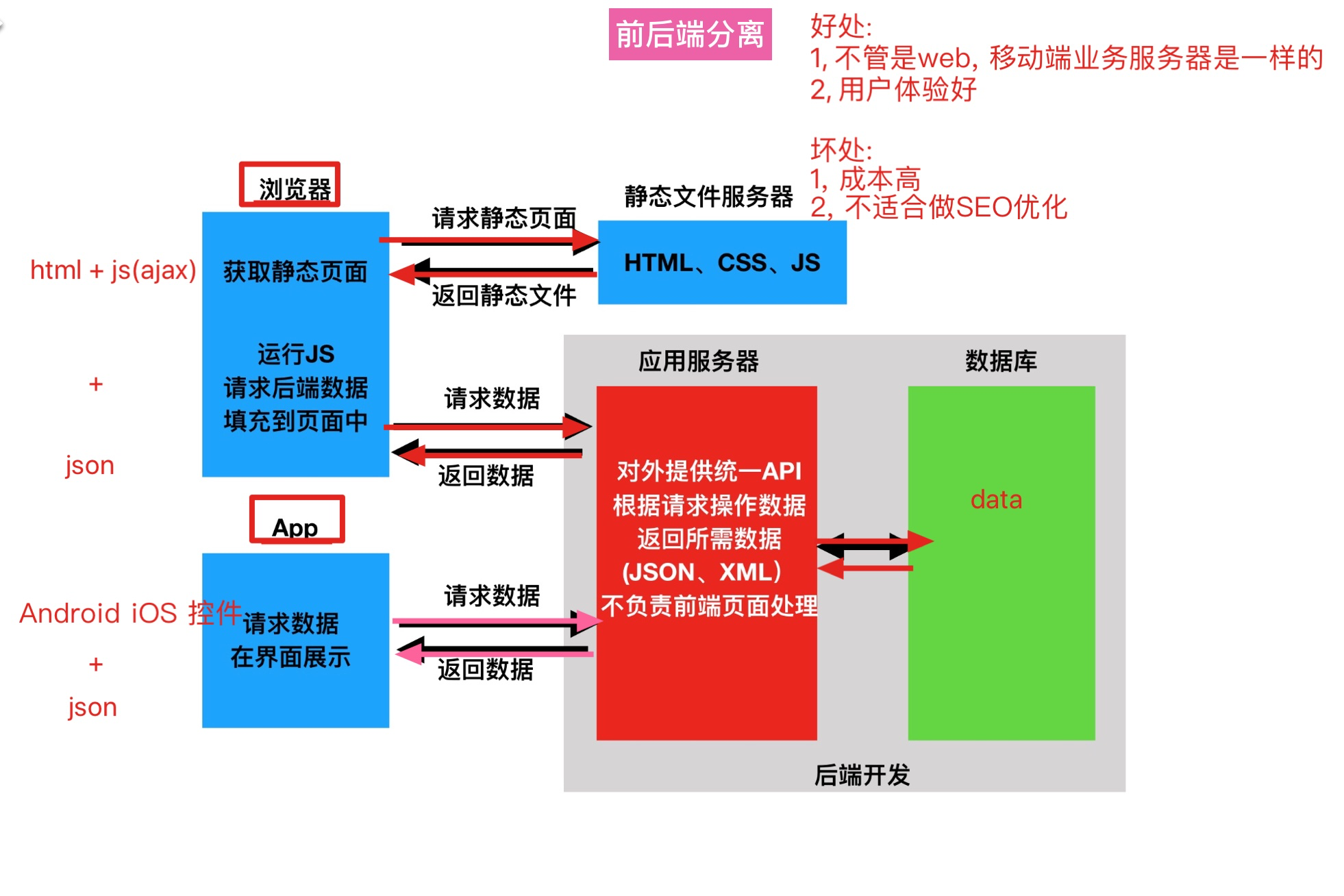
前后端分离:
- 注意点: 业务服务器和静态服务器是分开的
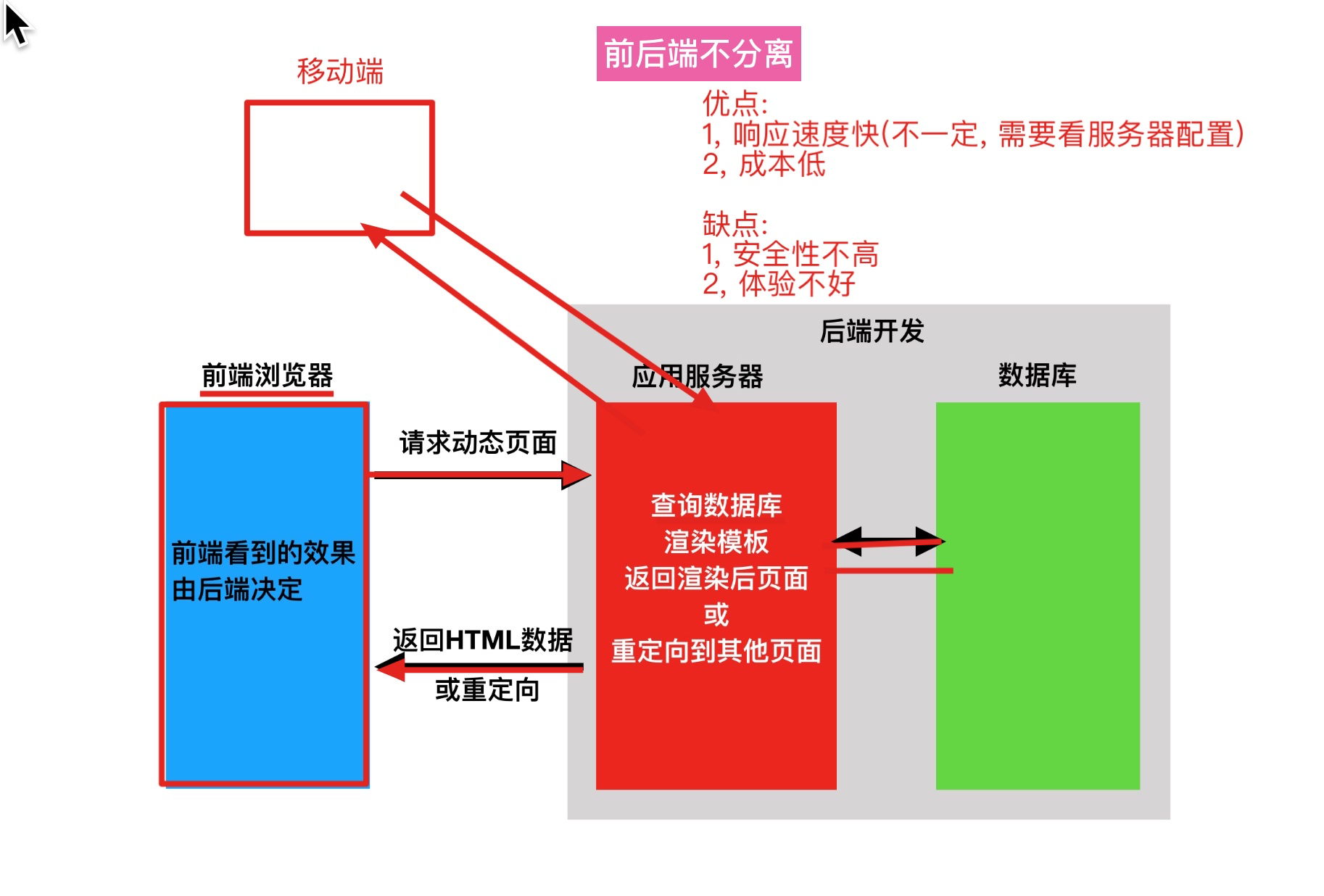
前后端不分离:
- 注意点: 页面和数据都是有后端处理的
2,restful风格介绍(了解)
- 目的: 知道为什么需要使用restful风格进行开发
- 原因
- 每个后端开发人员可能都有自己的定义方式,风格迥异
- 解决办法:
- restful
3,restful设计风格(了解)
目的: 知道常见的restful风格的标准
具体的标准:
api部署的域名, 主域名或者专有域名
把API部署在专有域名之下
https://api.example.com //不是www开头的部署在主域名之下
域名/api/版本, 通过url地址或者请求头accept
应该把版本号放在URL中
路径, 只能有名词, 不能有动词
//不是'/getProducts' GET /products :将返回所有产品清单 POST /products :将产品新建到集合 GET /products/4 :将获取产品 4 PATCH(或)PUT /products/4 :将更新产品 4http请求动词, get, post, update, delete
GET(SELECT):从服务器取出资源(一项或多项)。 POST(CREATE):在服务器新建一个资源。 PUT(UPDATE):在服务器更新资源(客户端提供改变后的完整资源)。 DELETE(DELETE):从服务器删除资源过滤信息
如果记录数量很多,服务器不可能都将它们返回给用户。API应该提供参数,过滤返回结果。
下面是一些常见的参数。
?limit=10:指定返回记录的数量 ?offset=10:指定返回记录的开始位置。 ?page=2&per_page=100:指定第几页,以及每页的记录数。 ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序。 ?animal_type_id=1:指定筛选条件参数的设计允许存在冗余,即允许API路径和URL参数偶尔有重复。比如,GET /zoos/ID/animals 与 GET /animals?zoo_id=ID 的含义是相同的。
状态, 200, 201, 204, 400, 401, 403, 404
200 OK - [GET]:服务器成功返回用户请求的数据 201 CREATED - [POST/PUT/PATCH]:用户新建或修改数据成功。 202 Accepted - [*]:表示一个请求已经进入后台排队(异步任务) 204 NO CONTENT - [DELETE]:用户删除数据成功。 400 INVALID REQUEST - [POST/PUT/PATCH]:用户发出的请求有错误,服务器没有进行新建或修改数据的操作 401 Unauthorized - [*]:表示用户没有权限(令牌、用户名、密码错误)。 403 Forbidden - [*] 表示用户得到授权(与401错误相对),但是访问是被禁止的。 404 NOT FOUND - [*]:用户发出的请求针对的是不存在的记录,服务器没有进行操作,该操作是幂等的。 406 Not Acceptable - [GET]:用户请求的格式不可得(比如用户请求JSON格式,但是只有XML格式)。 410 Gone -[GET]:用户请求的资源被永久删除,且不会再得到的。 422 Unprocesable entity - [POST/PUT/PATCH] 当创建一个对象时,发生一个验证错误。 500 INTERNAL SERVER ERROR - [*]:服务器发生错误,用户将无法判断发出的请求是否成功。错误处理
如果状态码是4xx,服务器就应该向用户返回出错信息。一般来说,返回的信息中将error作为键名,出错信息作为键值即可。
json{ error: "Invalid API key" }返回结果
针对不同操作,服务器向用户返回的结果应该符合以下规范。
- GET /collection:返回资源对象的列表(数组)
- GET /collection/resource:返回单个资源对象
- POST /collection:返回新生成的资源对象
- PUT /collection/resource:返回完整的资源对象
- PATCH /collection/resource:返回完整的资源对象
- DELETE /collection/resource:返回一个空文档
其他
返回的数据格式应该使用json,避免使用xml
django基础复习
4,restful案例(了解)
目的: 可以使用restful风格设计图书增删改查的案例
案例:
功能 路径 请求方式 响应状态码 获取所有的书籍 /books get 200 创建书籍 /books post 201 获取单个书籍 /books/ get 200 修改书籍 /books/ put 201 删除书籍 /books/ delete 204
5,数据准备
目的: 可以将图书和英雄的信息添加到数据中
操作流程:
1, 创建项目, 创建book子应用
2, 在子应用中定义模型类
pythonfrom django.db import models # 定义图书模型类BookInfo class BookInfo(models.Model): btitle = models.CharField(max_length=20, verbose_name='名称') bpub_date = models.DateField(verbose_name='发布日期') bread = models.IntegerField(default=0, verbose_name='阅读量') bcomment = models.IntegerField(default=0, verbose_name='评论量') is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') class Meta: db_table = 'tb_books' # 指明数据库表名 verbose_name = '图书' # 在admin站点中显示的名称 verbose_name_plural = verbose_name # 显示的复数名称 def __str__(self): """定义每个数据对象的显示信息""" return self.btitle # 定义英雄模型类HeroInfo class HeroInfo(models.Model): GENDER_CHOICES = ( (0, 'male'), (1, 'female') ) hname = models.CharField(max_length=20, verbose_name='名称') hgender = models.SmallIntegerField(choices=GENDER_CHOICES, default=0, verbose_name='性别') hcomment = models.CharField(max_length=200, null=True, verbose_name='描述信息') hbook = models.ForeignKey(BookInfo, on_delete=models.CASCADE, verbose_name='图书') # 外键 is_delete = models.BooleanField(default=False, verbose_name='逻辑删除') class Meta: db_table = 'tb_heros' verbose_name = '英雄' verbose_name_plural = verbose_name def __str__(self): return self.hname3, 注册子应用, 设置数据库配置
4, 创建数据库, 迁移
6,查询所有数据(理解)
查询和创建都属于列表视图,而代带参数的请求属于详情视图
目的: 可以编写视图查询所有的书籍信息
注意点:
- http.JsonResponse(books_list,safe=False)
- safe=False允许非字典数据可以被返回
- http.JsonResponse(books_list,safe=False)
代码
python# /book/views.py # 列表视图 class BookInfoView(View): def get(self, request): '''获取所有书籍''' # 1.查询所有的书籍 books = BookInfo.objects.all() # 2.数据转换 book_list = [] for book in books: book_dict = { 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, } book_list.append(book_dict) # 3.返回响应 # safe=False可以安全返回非字典 # json_dumps_params={'ensure_ascii': False}可以解决返回的中文数据为乱码 return http.JsonResponse(book_list, safe=False, json_dumps_params={'ensure_ascii': False}) other: # /book/urls urlpatterns = [ url('books/', views.BookInfoView.as_view()) ] # /project/urls urlpatterns = [ path('admin/', admin.site.urls), path('', include('book.urls')) ]
7,创建对象(理解)
目的: 可以添加书籍对象到数据库中
注意点:
- book = BookInfo.objects.create(**data_dict)
完整代码
python# 请求的时候只需要修改清请求方式就可以了,请求路径是不变的 def post(self, request): '''创建单本书籍''' # 1.获取参数,把json转换为字典 dict_data = json.loads(request.body.decode()) btitle = dict_data.get('btitle') bpub_date = dict_data.get('bpub_date') bread = dict_data.get('bread') bcomment = dict_data.get('bcomment') # 2.校验参数(省略) # 3.数据入库 book = BookInfo.objects.create(**dict_data) # 4.返回响应 book_dict = { 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, } return http.JsonResponse(book_dict)
8,获取单个对象(理解)
目的: 可以获取指定书籍对象
注意点:
- book = BookInfo.objects.get(id=book_id)
完整代码
python# 详情视图 class BookInfoDetailView(View): def get(self, request, pk): # 1.通过pk获取对象 book = BookInfo.objects.get(pk=pk) # 2.转换数据 book_dict = { 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, } # 3.返回响应 return http.JsonResponse(book_dict) # 注意这里的url——path urlpatterns = [ url('^books/$', views.BookInfoView.as_view()), url('^books/(?P<pk>\d+)/$', views.BookInfoDetailView.as_view()) ] # 其中^代表起始符,$代表结束符
9,修改单个对象(理解)
目的: 可以修改指定书籍对象
注意点:
- BookInfo.objects.filter(id=book_id).update(**data_dict)
完整代码
pythondef put(self, request, pk): # 1.获取参数 dict_data = json.loads(request.body.decode()) book = BookInfo.objects.get(pk=pk) # 2.校验参数 # 3.数据入库 BookInfo.objects.filter(pk=pk).update(**dict_data) # 把更新之后的数据拿出来返回 book = BookInfo.objects.get(pk=pk) book_dict = { 'id': book.id, 'btitle': book.btitle, 'bpub_date': book.bpub_date, 'bread': book.bread, 'bcomment': book.bcomment, } # 4.返回响应 return http.JsonResponse(book_dict, status=201)
10,删除单个对象(理解)
目的: 可以删除指定书籍对象
注意点:
- BookInfo.objects.get(id=book_id).delete()
代码
- python
def delete(self, request, pk): # 1.获取数据 book = BookInfo.objects.get(id=pk) # 2.删除数据 book.delete() # 3.返回响应 return http.HttpResponse(status=204)
序列化器
12,序列化器概述(了解)
- 目的: 知道序列化器的作用
- 序列化器的作用:
- 1, 反序列化: 把json(dict), 转成模型类对象 (校验,入库)
- 2, 序列化: 将模型类对象, 转成json(dict)数据
13,序列化器定义(掌握)
目的: 可以定义书籍的序列化器
操作流程:
pythonfrom rest_framework import serializers """ 定义序列化器: 1, 定义类, 继承自Serializer 2, 编写字段名称, 和模型类一样 3, 编写字段类型, 和模型类一样 4, 编写字段选项, 和模型类一样 read_only: 只读 label: 字段说明 序列化器作用: 1, 反序列化: 将json(dict)数据, 转成模型类对象 ①: 校验 ②: 入库 2, 序列化: 将模型类对象, 转成json(dict)数据 """"" #1,定义书籍序列化器 class BookInfoSerializer(serializers.Serializer): id = serializers.IntegerField(read_only=True,label="书籍编号") btitle = serializers.CharField(max_length=20,label="名称") bpub_date = serializers.DateField(label="发布日期") bread = serializers.IntegerField(default=0,label="阅读量") bcomment = serializers.IntegerField(default=0,label="评论量") is_delete = serializers.BooleanField(default=False,label="逻辑删除")
14,序列化器,序列化单个对象(掌握)
目的: 可以将单本数据使用序列化器, 转成json(dict)数据
操作流程:
pythonfrom book.models import BookInfo from book.serializers import BookInfoSerializer #1,获取书籍对象 book = BookInfo.objects.get(id=1) #2,创建序列化器对象, instance=book 表示将哪一本数据进行序列化 serializer = BookInfoSerializer(instance=book) #3,输出序列化之后的结果 print(serializer.data) """ {'id': 1, 'btitle': '射雕英雄传', 'bpub_date': '1980-05-01', 'bread': 12, 'bcomment': 34, 'is_delete': False} """
15,序列化器,序列化列表数据(掌握)
目的: 可以使用序列化器,对列表中的多个对象进行序列化
操作流程:
pythonfrom book.models import BookInfo from book.serializer import BookInfoSerializer #1,查询所有的书籍 books = BookInfo.objects.all() #2,创建序列化器对象,many=True 表示传入的是列表对象(多个数据) serializer = BookInfoSerializer(instance=books,many=True) #3,输出序列化的结果 serializer.data """ [ OrderedDict([('id', 1), ('btitle', '射雕英雄传'), ('bpub_date', '1980-05-01'), ('bread', 12), ('bcomment', 34), ('is_delete', False)]), OrderedDict([('id' ('btitle', '天龙八部'), ('bpub_date', '1986-07-24'), ('bread', 36), ('bcomment', 40), ('is_delete', False)]), OrderedDict([('id', 3), ('btitle', '笑傲江湖'), ('bp, '1995-12-24'), ('bread', 20), ('bcomment', 80), ('is_delete', False)]), OrderedDict([('id', 4), ('btitle', '雪山飞狐'), ('bpub_date', '1987-11-11'), ('bread', 58'bcomment', 24), ('is_delete', False)]), OrderedDict([('id', 6), ('btitle', '金瓶x2'), ('bpub_date', '2019-01-01'), ('bread', 10), ('bcomment', 5), ('is_delete', Fse)]) ] """ # OrderedDict: 有序字典注意点:
- serializer = BookSerializer(instance=books,many=True)
- instance: 需要序列化的对象
- many=True: 默认是None, 如果传入True, 需要序列化的对象是列表
- serializer.data: 表示输出序列化之后的结果
16,英雄序列化器关联外键(掌握)
目的: 可以将关联英雄的书籍信息, 三种形式表示出来
操作流程:
1, 序列化器
python#2,定义英雄序列化器 class HeroInfoSerializer(serializers.Serializer): """英雄数据序列化器""" GENDER_CHOICES = ( (0, 'male'), (1, 'female') ) id = serializers.IntegerField(label='ID', read_only=True) hname = serializers.CharField(label='名字', max_length=20) hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label='性别', required=False) hcomment = serializers.CharField(label='描述信息', max_length=200, required=False, allow_null=True) #1,添加外键,主键表示 必须提供`queryset` 选项, 或者设置 read_only=`True`. # queryset=BookInfo.objects.all()表示把所有书籍全部查出来让他自己去匹配。 # hbook = serializers.PrimaryKeyRelatedField(queryset=BookInfo.objects.all()) # hbook = serializers.PrimaryKeyRelatedField(read_only=True) #2,添加外键, 来自于关联模型类, __str__的返回值 # hbook = serializers.StringRelatedField(read_only=True) #3,添加外键,关联另外一个序列化器,返回整本书的全部信息(书已经定义好序列化器) hbook = BookInfoSerializer(read_only=True)2, 类视图
python""" ===============3, 英雄序列化器, 关联外键 ================= """"" from book.models import HeroInfo from book.serializer import HeroInfoSerializer #1,获取单个英雄 hero = HeroInfo.objects.get(id=1) #2,创建英雄序列化器 serializer = HeroInfoSerializer(instance=hero) #3,输出结果 serializer.data
17,书籍序列化器,关联many(掌握)
django小复习:
python# 知道一个英雄,如何查出这个英雄所在的书籍 hero = HeroInfo.objects.get(id=1) hero.hbook # 反过来,知道一本书,如何查出这本书所关联的所有英雄 book = BookInfo.objects.get(id=1) book.heroinfo_set # 所以在DRF也差不多是这样写的目的: 可以在序列化书籍的时候, 展示关联的英雄的信息
操作流程:
python#1,定义书籍序列化器 class BookInfoSerializer(serializers.Serializer): ... #1,关联英雄字段, 在一方中,输出多方内容的时候加上many=True # heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True,many=True) heroinfo_set = serializers.StringRelatedField(read_only=True,many=True)
使用序列化器改进之前django写的代码
def get(self, request):
'''获取所有书籍'''
# 1.查询所有的书籍
books = BookInfo.objects.all()
# 2.数据转换
# book_list = []
# for book in books:
# book_dict = {
# 'id': book.id,
# 'btitle': book.btitle,
# 'bpub_date': book.bpub_date,
# 'bread': book.bread,
# 'bcomment': book.bcomment,
# }
# book_list.append(book_dict)
# TODO 序列器改进
serializer = BookInfoSerializer(instance=books, many=True)
# 3.返回响应
# safe=False可以安全返回非字典
# json_dumps_params={'ensure_ascii': False}可以解决返回的中文数据为乱码
return http.JsonResponse(serializer.data, safe=False, json_dumps_params={'ensure_ascii': False})反序列化器
反序列化
校验:
- 字段类型校验
- 字段选项校验
- 单字段,校验(方法)
- 多字段校验(方法)
- 自定义校验(方法)
18,反序列化-字段类型校验
目的: 可以使用序列化器,对数据进行校验操作
操作流程: serializer.is_valid(raise_exception=True)
Pythonfrom book.serializer import BookInfoSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶x-插画版", "bpub_date":"2019-01-01", "bread":15, "bcomment":25 } #2,创建序列化器对象 serializer = BookInfoSerializer(data=data_dict) #3,校验, raise_exception=True, 校验不通过,抛出异常信息 # 也可以直接打印错误信息print(serializer.error_messages) # serializer.is_valid() serializer.is_valid(raise_exception=True)
19,反序列化-字段选项校验
目的: 可以使用序列化器,对数据进行选项约束校验
操作流程: serializer.is_valid(raise_exception=True)
1, 序列化器
min_value=0
max_value=50
required: 默认就是True,必须要传递,除非设置了default | false | read_only
有read_only=True,会进行序列化操作,并且反序列化时不需要传该参也能校验通过(不进行反序列化)
约束演示
- python
class BookInfoSerializer(serializers.Serializer): ... bread = serializers.IntegerField(default=0,min_value=0,label="阅读量") bcomment = serializers.IntegerField(default=0,max_value=50,label="评论量") is_delete = serializers.BooleanField(default=False,label="逻辑删除")
2, 类视图
- python
from book.serializer import BookInfoSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶x", "bpub_date":"2019-01-01", "bread":15, "bcomment":99 } #2,创建序列化器对象 serializer = BookInfoSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True)
20,反序列化-单字段校验
在调用is_vaild方法的时候,它会进入你编写的单字段检验方法
其中vaildata()代表多字段校验,而后面跟上下划线加上字段名为方法名的话代表该方法为单字段校验
attrs就是传过来的数据:在这里是btitle
目的: 可以编写单字段校验方法, 对btitle进行校验
操作流程:
1, 序列化器
- python
class BookInfoSerializer(serializers.Serializer): ... #3, 单字段校验, 方法; 需求: 添加的书籍必须包含'金瓶' def validate_btitle(self, attrs): print("value = {}".format(attrs)) #1,判断传入的value中是否包含金瓶 if "金瓶" not in attrs: raise serializers.ValidationError("书名必须包含金瓶") #2,返回结果 return attrs
2, 类视图
- python
from book.serializer import BookInfoSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶x", "bpub_date":"2019-01-01", "bread":15, "bcomment":5 } #2,创建序列化器对象 serializer = BookInfoSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True)
注意点:
- 单字段校验方法
- def validate_==字段名==(self,value):
- pass
- def validate_==字段名==(self,value):
- 如果校验不通过,直接抛出异常即可
- 单字段校验方法
21,反序列化-多字段校验
这里接收的attrs就是传入的整个字典了
目的: 可以编写多字段校验方法, 对阅读量和评论量进行判断(两两之间比较常用多字段校验)
操作流程:
1, 序列化器
- python
class BookInfoSerializer(serializers.Serializer): ... #4,多字段校验, 方法; 添加书籍的时候,评论量不能大于阅读量 def validate(self, attrs): """ :param attrs: 外界传入的需要校验的字典 :return: """ #1,判断评论量和阅读量的关系 if attrs["bread"] < attrs["bcomment"]: raise serializers.ValidationError("评论量不能大于阅读量") #2,返回结果 return attrs
2, 类视图
- python
""" ===============7, 反序列化-多字段校验 ================= """"" from book.serializer import BookInfoSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶xxx", "bpub_date":"2019-01-01", "bread":33, "bcomment":22 } #2,创建序列化器对象 serializer = BookInfoSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True)
22,反序列化-自定义校验(理解)
把自定义的校验方法名加入到字段的选项validators中
目的: 可以自定义方法,对日期进行校验
操作流程:
1, 序列化器
- python
#需求: 添加的书籍的日期不能小于2015年 def check_bpub_date(date): print("date = {}".format(date)) if date.year < 2015: raise serializers.ValidationError("日期不能小于2015年") return date #1,定义书籍序列化器 class BookInfoSerializer(serializers.Serializer): ... bpub_date = serializers.DateField(label="发布日期",validators=[check_bpub_date])
2, 类视图
- python
""" ===============8, 反序列化-自定义校验 ================= """"" from book.serializer import BookInfoSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶xxx", "bpub_date":"2011-11-01", "bread":11, "bcomment":5 } #2,创建序列化器对象 serializer = BookInfoSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True)
数据入库
- 创建新的对象
- 更新 对象
23,反序列化-数据入库create(掌握)
目的: 可以将书籍对象保存到数据库中
操作流程:
1, 序列化器
- python
class BookInfoSerializer(serializers.Serializer): ... #5,重写create方法,实现数据入库 def create(self, validated_data): # print("validated_data = {}".format(validated_data)) #1,创建book对象,入库 book = BookInfo.objects.create(**validated_data) #2,返回响应 return book
2, 类视图
- python
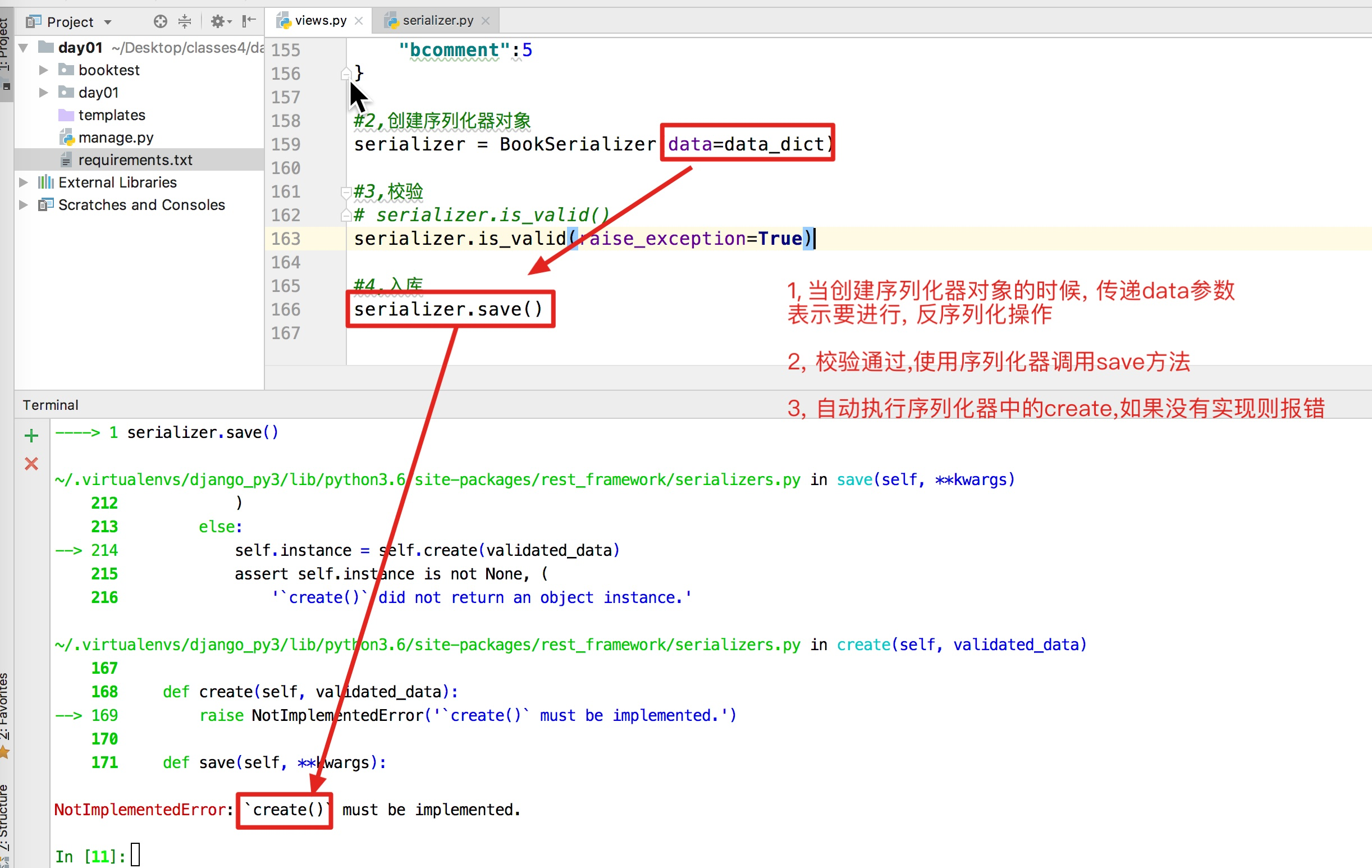
from book.serializer import BookInfoSerializer #1,准备字典数据 data_dict = { "btitle":"金瓶xxx-精装版", "bpub_date":"2015-11-01", "bread":11, "bcomment":5 } #2,创建序列化器对象 serializer = BookInfoSerializer(data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True) #4,入库 serializer.save()
注意点:
24,反序列化-数据更新update(掌握)
当创建序列化器的时候传递了两个参数,它会自动去找update()方法
目的: 可以重写update方法, 更新数据库中指定的书籍
操作流程:
1, 序列化器
- python
class BookInfoSerializer(serializers.Serializer): ... #6,重写update方法,实现数据更新 def update(self, instance, validated_data): """ :param instance: 需要更新的对象 :param validated_data: 验证成功之后的数据 :return: """ #1,更新数据 instance.btitle = validated_data["btitle"] instance.bpub_date = validated_data["bpub_date"] instance.bread = validated_data["bread"] instance.bcomment = validated_data["bcomment"] instance.save() #2,返回数据 book = BookInfo.objects.get(id=instance.id) return book
2, 类视图
- python
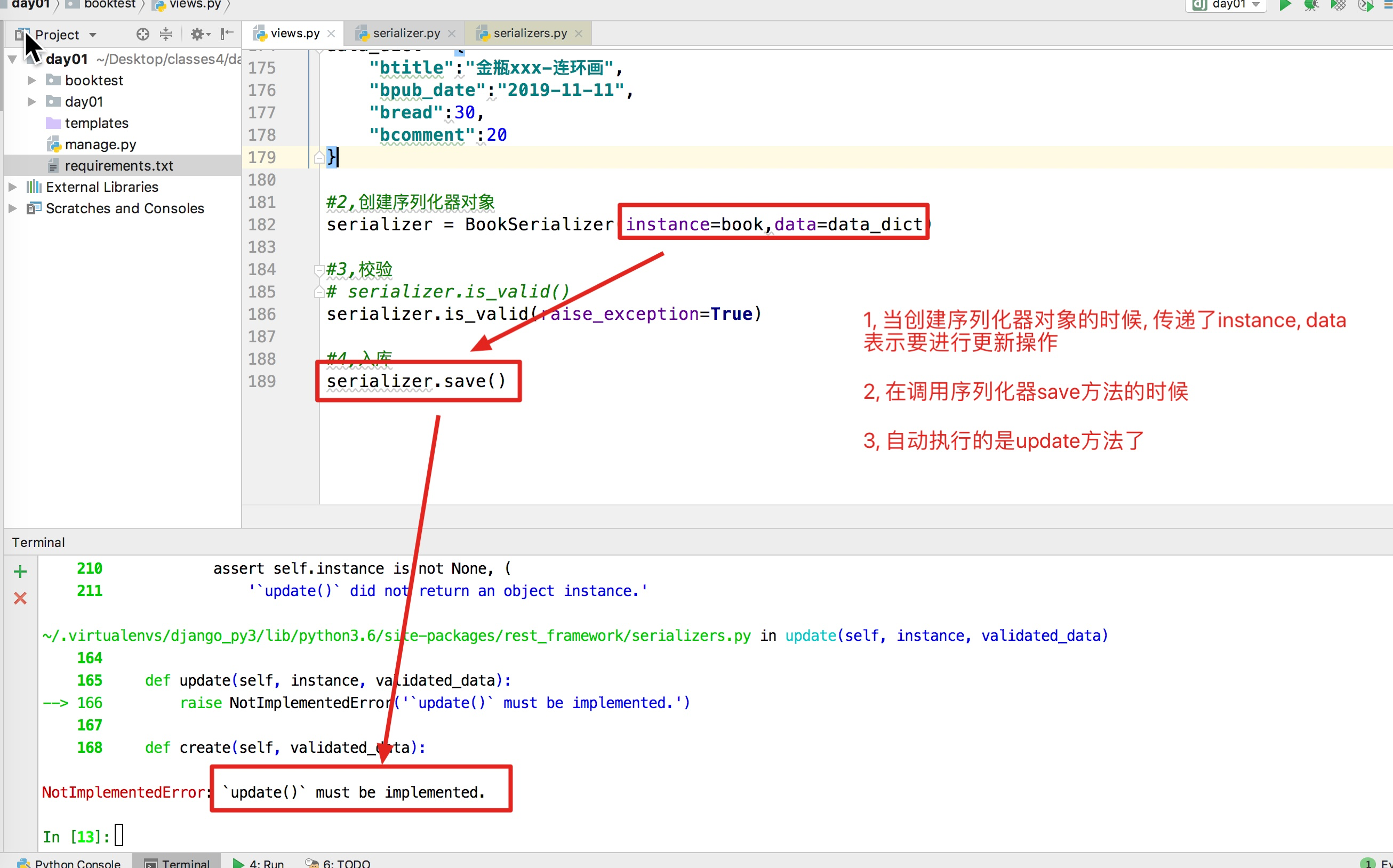
from book.serializer import BookInfoSerializer from book.models import BookInfo #1,准备字典数据 book = BookInfo.objects.get(id=8) data_dict = { "btitle":"金瓶xxx-连环画", "bpub_date":"2019-11-11", "bread":30, "bcomment":20 } #2,创建序列化器对象 serializer = BookInfoSerializer(instance=book,data=data_dict) #3,校验 # serializer.is_valid() serializer.is_valid(raise_exception=True) #4,入库 serializer.save()
注意点:
ModelSerializer
1,ModelSerializer
目的: 可以使用ModelSerializer根据模型类生成字段
作用:
- 1, 可以参考模型类自动生成字段, 还可以自己编写字段
- 2, 提供了create方法,update方法
操作流程:
1, 定义模型类序列化器
- python
from rest_framework import serializers from book.models import BookInfo #1,定义书籍模型类序列化器 class BookInfoSerializer(serializers.ModelSerializer): # mobile = serializers.CharField(max_length=11,min_length=11,label="手机号",write_only=True) class Meta: model = BookInfo #参考模型类生成字段 fields = "__all__" #生成所有字段
2, 测试结果
1, 使用模型类序列化器, 测试序列化
人为在序列器添加字段,而模型类里面不添加主要是有些数据需要校验,但不需要入库,比如短信验证码;
直接输出可能会报错,因为序列化器里面有人为添加的mobile字段,而模型类里面没有,解决方案有1里面的下面几种:
python""" 1, 模型类中添加mobile字段 2, 删除序列化器中的mobile 3, 动态添加一mobile属性 4, 将mobile字段设置为write_only(只写,只进行反序列化) """ from booktest.models import BookInfo from booktest.serializer import BookModelSerializer #1,获取模型类对象 book = BookInfo.objects.get(id=1) # book.mobile = "13838389438" #2,创建序列化器对象 serializer = BookModelSerializer(instance=book) #3,输出结果 serializer.data2, 使用模型类序列化器, 测试反序列化, 入库操作
自动带有create()方法
pythonfrom book.serializers import BookInfoSerializer #1,准备字典数据 book_dict = { "btitle":"鹿鼎记1", "bpub_date":"1999-01-01", "bread":10, "bcomment":5 } #2,序列化器对象创建 serializer = BookInfoSerializer(data=book_dict) #3,校验,入库 serializer.is_valid(raise_exception=True) serializer.save()3, 使用模型类序列化器, 测试反序列化, 更新操作
自动带有update()方法
pythonfrom booktest.serializer import BookModelSerializer from booktest.models import BookInfo #1,准备字典数据, 书籍对象 book = BookInfo.objects.get(id=9) book_dict = { "btitle":"鹿鼎记2", "bpub_date":"1999-01-01", "bread":100, "bcomment":5 } #2,序列化器对象创建 serializer = BookModelSerializer(instance=book,data=book_dict) #3,校验,入库 serializer.is_valid(raise_exception=True) serializer.save()
2, fields
目的: 可以使用fields生成指定的字段
操作流程:
1, 序列化器
- python
#1,定义书籍模型类序列化器 class BookModelSerializer(serializers.ModelSerializer): mobile = serializers.CharField(max_length=11,min_length=11,label="手机号",write_only=True) class Meta: model = BookInfo #参考模型类生成字段 # fields = "__all__" #生成所有字段 #1,生成指定的字段 fields = ["id","btitle","mobile"] fields: 生成指定的字段
注意点:
- 进入到ModelSerializer父类, 1063行源码中存在
3,read_only_fields
目的:可以使用read_only_fields设置只读字段
操作流程:
1,序列化器
- python
#1,定义书籍模型类序列化器 class BookModelSerializer(serializers.ModelSerializer): .... class Meta: .... #2,设置只读字段 read_only_fields = ["btitle","bpub_date"]
4,extra_kwargs
目的: 可以使用extra_kwargs, 给生成的字段,添加选项约束,就是它自动生成的约束满足不了实际需求
操作流程:
对应的字段名加上选项名的字典就可以了
1, 序列化器
- python
#1,定义书籍模型类序列化器 class BookModelSerializer(serializers.ModelSerializer): ... class Meta: ... #3,给生成的字段添加额外约束 extra_kwargs = { "bread":{ "max_value":999999, "min_value":0 }, "bcomment": { "max_value": 888888, "min_value": 0 } }
一级视图APIView
5,APIView之request
目的: 知道APIView的特点, 并且可以通过request获取参数
特点:
1, 继承自View
2, 提供了自己的request对象
- get参数: request.query_params
- post参数: request.data
3, 提供了自己的response对象
4, 并且提供了认证, 权限, 限流等功能
获取数据的方式不一样了
操作流程:
1, 类视图
- python
#1,定义类,集成APIView class BookAPIView(APIView): def get(self,request): """ View获取数据方式: GET: request.GET POST: request.POST request.body APIView获取数据方式 GET: reqeust.query_params POST: request.data :param request: :return: """ #1,获取APIVIew中的get请求参数 # print(request.query_params) return http.HttpResponse("get") def post(self,request): # 2,获取APIView中的post的参数 print(request.data) return http.HttpResponse("post")
6,APIView之Response
目的: 可以使用response响应各种数据和状态
好处:
- 1,使用一个类, 就可以替代以前View中的各种类型的Response(HttpResponse,JsonResponse….)
- 2, 可以配合状态码status使用
操作流程:
1,类视图
- python
from rest_framework.views import APIView from django import http from rest_framework.response import Response from rest_framework import status #1,定义类,集成APIView class BookAPIView(APIView): def get(self,request): ... return Response([{"name":"zhangsan"}, {"age":13}],status=status.HTTP_404_NOT_FOUND)
7,APIView实现列表视图
目的: 可以使用序列化器和APIView对列表视图进行改写
操作流程:
1, 子路由
- python
from django.conf.urls import url from . import views urlpatterns = [ # url(r'^books/$',views.BookAPIView.as_view()), url(r'^books/$',views.BookListAPIView.as_view()) ]
2, 类视图
- python
#2,序列化器和APIView实现列表视图 class BookListAPIView(APIView): def get(self,request): #1,查询所有的书籍 books = BookInfo.objects.all() #2,将对象列表转成字典列表 serializr = BookInfoModelSerializer(instance=books,many=True) #3,返回响应 return Response(serializr.data) def post(self,request): #1,获取参数 data_dict = request.data #2,创建序列化器 serializer = BookInfoModelSerializer(data=data_dict) #3,校验,入库 serializer.is_valid(raise_exception=True) serializer.save() #4,返回响应 return Response(serializer.data,status=status.HTTP_201_CREATED)
3, 序列化器
- python
from rest_framework import serializers from booktest.models import BookInfo #1,定义书籍模型类序列化器 class BookInfoModelSerializer(serializers.ModelSerializer): class Meta: model = BookInfo fields = "__all__"
8,APIView实现详情视图
目的: 可以使用模型类序列化器和APVIew改写详情视图
操作流程:
1, 子路由
- python
from django.conf.urls import url from . import views urlpatterns = [ ... url(r'^books/(?P<book_id>\d+)/$',views.BookDetailAPIView.as_view()), ]
2, 类视图
- python
# 3,序列化器和APIView实现详情视图 class BookDetailAPIView(APIView): def get(self, request, book_id): # 1,获取书籍 book = BookInfo.objects.get(id=book_id) # 2,创建序列化器对象 serializer = BookInfoSerializer(instance=book) # 4,返回响应 return Response(serializer.data, status=status.HTTP_200_OK) def put(self, request, book_id): # 1,获取数据,获取对象 data_dict = request.data book = BookInfo.objects.get(id=book_id) # 2,创建序列化器对象 serializer = BookInfoSerializer(instance=book, data=data_dict) # 3,校验,入库 serializer.is_valid(raise_exception=True) serializer.save() # 4,返回响应 return Response(serializer.data, status=status.HTTP_201_CREATED) def delete(self, request, book_id): # 1,删除书籍 BookInfo.objects.get(id=book_id).delete() # 2,返回响应 return Response(status=status.HTTP_204_NO_CONTENT)
二级视图与Mixin
9,二级视图,实现列表视图
目的: 可以通过GenericAPIView改写列表视图
主要就是把各个方法调用的模型类放到类的属性上,这样比如换成英雄的时候只需要改改类属性就可以了,而不是到每个方法里面单独修改,相对于之前的,代码还没有减少但复用性更好;
操作流程:
1,子路由
- python
url(r'^generic_apiview_books/$',views.BookListGenericAPIView.as_view()),
2, 类视图
- python
#4,二级视图GenericAPIView特点 """ 特点: 1, GenericAPIView,继承自APIView类,为列表视图, 和详情视图,添加了常用的行为和属性。 行为(方法) get_queryset get_serializer 属性 queryset serializer_class 2, 可以和一个或多个mixin类配合使用。 """ #5,使用二级视图GenericAPIView实现, 列表视图 class BookListGenericAPIView(GenericAPIView): #1,提供公共的属性 queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer def get(self,request): #1,查询所有的书籍 # books = self.queryset books = self.get_queryset() #2,将对象列表转成字典列表 # serializr = BookInfoModelSerializer(instance=books,many=True) # serializr = self.serializer_class(instance=books,many=True) # serializr = self.get_serializer_class()(instance=books,many=True) serializr = self.get_serializer(instance=books,many=True) #3,返回响应 return Response(serializr.data) def post(self,request): #1,获取参数 data_dict = request.data #2,创建序列化器 # serializer = BookInfoModelSerializer(data=data_dict) serializer = self.get_serializer(data=data_dict) #3,校验,入库 serializer.is_valid(raise_exception=True) serializer.save() #4,返回响应 return Response(serializer.data,status=status.HTTP_201_CREATED)
10,二级视图,实现详情视图
这里用到了get_object()方法,下面会讲;需要注意的是,因为源码已经写死了,所以这里需要固定把传进来的参数写成pk;
目的: 可以使用GenericAPIView改写详情视图
操作流程:
1, 子路由
- python
url(r'^generic_apiview_books/(?P<pk>\d+)/$',views.BookDetailGenericAPIView.as_view()),
2, 类视图
- python
#6,使用二级视图GenericAPIView实现, 详情视图 class BookDetailGenericAPIView(GenericAPIView): #1,提供通用属性 queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer def get(self,request,pk): #1,获取书籍 # book = BookInfo.objects.get(id=book_id) book = self.get_object() #根据book_id到queryset中取出书籍对象 #2,创建序列化器对象 serializer = self.get_serializer(instance=book) #4,返回响应 return Response(serializer.data,status=status.HTTP_200_OK) def put(self,request,pk): #1,获取数据,获取对象 data_dict = request.data book = self.get_object() #2,创建序列化器对象 serializer = self.get_serializer(instance=book,data=data_dict) #3,校验,入库 serializer.is_valid(raise_exception=True) serializer.save() #4,返回响应 return Response(serializer.data,status=status.HTTP_201_CREATED) def delete(self,request,pk): #1,删除书籍 self.get_object().delete() #2,返回响应 return Response(status=status.HTTP_204_NO_CONTENT)
11,get_object方法
目的: 理解get_object如何根据pk在queryset获取的单个对象
二级视图GenericAPIView属性方法总结
- python
""" 特点: 1, GenericAPIView,继承自APIView类,为列表视图, 和详情视图,添加了常用的行为和属性。 行为(方法) get_queryset: 获取queryset的数据集 get_serializer: 获取serializer_class序列化器对象 get_object: 根据lookup_field获取单个对象 属性 queryset: 通用的数据集 serializer_class: 通用的序列化器 lookup_field: 默认是pk,可以手动修改id 2, 可以和一个或多个mixin类配合使用。 """
操作流程:
1, 类视图
- python
class BookDetailGenericAPIView(GenericAPIView): #1,提供通用属性 ... lookup_field = "id" def get(self,request,id): #1,获取书籍 book = self.get_object() #根据id到queryset中取出书籍对象 ... def put(self,request,id): #1,获取数据,获取对象 ... book = self.get_object() ... def delete(self,request,id): #1,删除书籍 self.get_object().delete() ...
12,MiXin
目的: 知道mixin的作用, 常见的mixin类
操作流程:
- python
""" Mixin,特点: 1, mixin类提供用于提供基本视图行为(列表视图, 详情视图)的操作--增删改查 2, 配合二级视图GenericAPIView使用的 类名称 提供方法 功能 ListModelMixin list 查询所有的数据 CreateModelMixin create 创建单个对象 RetrieveModelMixin retrieve 获取单个对象 UpdateModelMixin update 更新单个对象 DestroyModelMixin destroy 删除单个对象 """
13,二级视图,MiXin配合使用
目的: 可以使用mixin和二级视图GenericAPIView对列表视图和详情视图做改写
操作流程:
1, 子路由
- python
url(r'^mixin_generic_apiview_books/$', views.BookListMixinGenericAPIView.as_view()), url(r'^mixin_generic_apiview_books/(?P<book_id>\d+)/$', views.BookDetailMixinGenericAPIView.as_view()),
2,类视图
- python
from rest_framework.mixins import ListModelMixin,CreateModelMixin,RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin #8,mixin和二级视图GenericAPIView, 实现列表视图, 详情视图 class BookListMixinGenericAPIView(GenericAPIView,ListModelMixin,CreateModelMixin): #1,提供公共的属性 queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer def get(self,request): return self.list(request) def post(self,request): return self.create(request) class BookDetailMixinGenericAPIView(GenericAPIView,RetrieveModelMixin,UpdateModelMixin,DestroyModelMixin): #1,提供通用属性 queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer # lookup_field = "id" lookup_url_kwarg = "book_id" def get(self,request,book_id): return self.retrieve(request) def put(self,request,book_id): return self.update(request) def delete(self,request,book_id): return self.destroy(request)
三级视图与视图集
14,三级视图
目的: 知道三级视图的作用, 以及常见的三级视图
操作流程:
- python
""" 特点: 如果没有大量自定义的行为, 可以使用通用视图(三级视图)解决 常见的三级视图: 类名称 父类 提供方法 作用 CreateAPIView GenericAPIView, post 创建单个对象 CreateModelMixin ListAPIView GenericAPIView, get 查询所有的数据 ListModelMixin RetrieveAPIView GenericAPIView, get 获取单个对象 RetrieveModelMixin DestroyAPIView GenericAPIView, delete 删除单个对象 DestroyModelMixin UpdateAPIView GenericAPIView, put 更新单个对象 UpdateModelMixin """
15,三级视图,实现列表,详情视图
目的: 可以使用三级视图实现列表视图,详情视图功能
操作流程:
1,子路由
- python
url(r'^third_view/$',views.BookListThirdView.as_view()), url(r'^third_view/(?P<pk>\d+)/$', views.BookDetailThirdView.as_view()),
2,类视图
- python
#10,三级视图,实现列表,详情视图 from rest_framework.generics import ListAPIView,CreateAPIView class BookListThirdView(ListAPIView,CreateAPIView): #1,提供公共的属性 queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer from rest_framework.generics import RetrieveAPIView,UpdateAPIView,DestroyAPIView class BookDetailThirdView(RetrieveAPIView,UpdateAPIView,DestroyAPIView): #1,提供通用属性 queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer
16,视图集
就是比如你获取单个,以及获取所有使用的都是get()方法,这时候就不能把这两个方法写在一个类之中,所以这就是viewset需要解决的问题;
目的: 知道视图集的作用, 以及常见的视图集
操作流程:
- python
""" 视图集 特点: 1,可以将一组相关的操作, 放在一个类中进行完成 2,不提供get,post方法, 使用retrieve, create方法来替代 3,可以将标准的请求方式(get,post,put,delete), 和mixin中的方法做映射 常见的视图集: 类名称 父类 作用 ViewSet APIView 可以做路由映射(没有其他什么用) ViewSetMixin(提供路由映射) GenericViewSet GenericAPIView 可以做路由映射,可以使用三个属性,三个方法 ViewSetMixin ModelViewSet GenericAPIView 所有的增删改查功能,可以使用三个属性,三个方法 5个mixin类 ReadOnlyModelViewSet GenericAPIView 获取单个,所有数据,可以使用三个属性,三个方法 RetrieveModelMixin ListModelMixin """
17,ViewSet
需要注意这里路由的映射;
目的: 可以使用ViewSet实现获取所有,单个数据
如果不用viewset,一个视图类里面是无法使用两个get方法的
操作流程:
1,子路由
- python
url(r'^viewset/$',views.BooksViewSet.as_view({'get': 'list'})), url(r'^viewset/(?P<pk>\d+)/$',views.BooksViewSet.as_view({'get': 'retrieve'}))
2,类视图
- python
#12, 使用viewset实现获取所有和单个 from django.shortcuts import get_object_or_404 from booktest.serializer import BookInfoModelSerializer from rest_framework import viewsets class BooksViewSet(viewsets.ViewSet): """ A simple ViewSet for listing or retrieving books. """ def list(self, request): queryset = BookInfo.objects.all() serializer = BookInfoModelSerializer(instance=queryset, many=True) return Response(serializer.data) def retrieve(self, request, pk=None): queryset = BookInfo.objects.all() book = get_object_or_404(queryset, pk=pk) serializer = BookInfoModelSerializer(instance=book) return Response(serializer.data)
18,ReadOnlyModelViewSet
目的: 可以使用ReadOnlyModelViewSet获取所有, 和单个数据
操作流程:
1, 子路由
- python
url(r'^readonly_viewset/$', views.BooksReadOnlyModelViewSet.as_view({'get': 'list'})), url(r'^readonly_viewset/(?P<pk>\d+)/$', views.BooksReadOnlyModelViewSet.as_view({'get': 'retrieve'})),
2, 类视图
- python
#13,使用ReadOnlyModelViewSet实现获取单个和所有 from rest_framework.viewsets import ReadOnlyModelViewSet class BooksReadOnlyModelViewSet(ReadOnlyModelViewSet): queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer
19,ModelViewSet
目的: 使用ModelViewSet实现列表视图,详情视图功能
操作流程:
1, 子路由
- python
url(r'^model_viewset/$', views.BookModelViewSet.as_view({'get': 'list',"post":"create"})), url(r'^model_viewset/(?P<pk>\d+)/$', views.BookModelViewSet.as_view({'get': 'retrieve','put':'update','delete':'destroy'})),
2, 类视图
- python
#14,ModelViewSet实现列表视图,详情视图功能 from rest_framework.viewsets import ModelViewSet class BookModelViewSet(ModelViewSet): queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer
视图集额外动作
1,视图集额外动作
目的: 可以给视图集添加额外的动作(方法)
不修改原有的方法,但需要自定义自己的方法:比如查出阅读量大于20的书籍
原理:就是把自己自定义的方法与get或其他做一个映射就可以了
操作流程:
1, 子路由
- python
from django.conf.urls import url from . import views urlpatterns = [ url(r'^books/$',views.BookInfoModelViewSet.as_view({"get":"list","post":"create"})), url(r'^books/(?P<pk>\d+)/$',views.BookInfoModelViewSet.as_view({"get":"retrieve","put":"update","delete":"destory"})), url(r'^books/bread/$',views.BookInfoModelViewSet.as_view({"get":"bread_book"})), ]
2, 类视图
- python
from django.shortcuts import render from rest_framework.viewsets import ModelViewSet from booktest.models import BookInfo from booktest.serializers import BookInfoModelSerializer from rest_framework.response import Response #1,视图集 class BookInfoModelViewSet(ModelViewSet): queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer #1,获取阅读量大于20的书籍 def bread_book(self,request): #1,获取指定书籍 books = BookInfo.objects.filter(bread__gt=20) #2,创建序列化器对象 serializer = self.get_serializer(instance=books,many=True) #3,返回响应 return Response(serializer.data) #2,修改书籍编号为1的, 阅读量为99
3, 序列化器
- python
from rest_framework import serializers from booktest.models import BookInfo #1,模型类序列化器 class BookInfoModelSerializer(serializers.ModelSerializer): class Meta: model = BookInfo fields = "__all__"
2,视图集额外动作,partial
目的: 可以编写额外动作添加参数, 并且更新局部信息
比如只传bread:99去修改就会报错,加上这个字段就不会报错
操作流程:
1, 子路由
- python
url(r'^books/bread/(?P<pk>\d+)/$', views.BookInfoModelViewSet.as_view({"put":"update_book_bread"})),
2, 类视图
- python
class BookInfoModelViewSet(ModelViewSet): ... #2,修改书籍编号为1的, 阅读量为99 def update_book_bread(self,request,pk): #1,获取参数 book = self.get_object() data = request.data #2,创建序列化器,partial=True可以局部更新 serializer = self.get_serializer(instance=book,data=data,partial=True) #3,校验,入库 serializer.is_valid(raise_exception=True) serializer.save() #4,返回响应 return Response(serializer.data,status=201)
router
3,路由router
目的: 可以通过DefaultRouter和SimpleRouter两个类来自动生成路由
DefautRouter生成路由格式:
特点: 共有三对路由
- 1, 列表路由
- 2, 详情路由
- 3, 根路由
- python
[ <RegexURLPattern haha-list ^books/$>, <RegexURLPattern haha-list ^books\.(?P<format>[a-z0-9]+)/?$>, <RegexURLPattern haha-detail ^books/(?P<pk>[^/.]+)/$>, <RegexURLPattern haha-detail ^books/(?P<pk>[^/.]+)\.(?P<format>[a-z0-9]+)/?$>, <RegexURLPattern api-root ^$>, <RegexURLPattern api-root ^\.(?P<format>[a-z0-9]+)/?$> ] SimpleRouter生成路由格式:
特点: 生成两个路由
- 1, 列表路由
- 2, 详情路由
- python
[ <RegexURLPattern haha-list ^books/$>, <RegexURLPattern haha-detail ^books/(?P<pk>[^/.]+)/$> ]
操作流程:
1, 子路由
- python
from rest_framework.routers import SimpleRouter,DefaultRouter #1,创建路由对象 router = SimpleRouter() #2,注册视图集 router.register('books',views.BookInfoModelViewSet,base_name="haha") urlpatterns += router.urls #3,输出结果 print(urlpatterns)
注意点:
- 1, 使用DRF可以自动根据前端需要的类型, 返回对应格式的数据
- 2, 请求的时候在请求头中标记, Accept即可
- 3, 只有视图集,才能自动生成路由
4,装饰action
目的: 可以通过action装饰方法, 自动生成路由
操作流程:
1, 类视图
- python
from rest_framework.decorators import action #1,视图集 class BookInfoModelViewSet(ModelViewSet): ... #1,获取阅读量大于20的书籍 @action(methods=['GET'],detail=False) #生成路由规则: 前缀/方法名/ def bread_book(self,request): ... #2,修改书籍编号为1的, 阅读量为99 @action(methods=["PUT"],detail=True) #生成路由规则: 前缀/{pk}/方法名/ def update_book_bread(self,request,pk): ...
权限设置
5,认证Authentication
目的: 可以参考官方文档, 配置认证内容
操作流程:
1, 全局配置(setteings.py)
- python
# DRF配置信息 REST_FRAMEWORK = { #1,全局认证 'DEFAULT_AUTHENTICATION_CLASSES': [ 'rest_framework.authentication.BasicAuthentication', #此身份验证方案使用HTTP基本身份验证,用于测试使用 'rest_framework.authentication.SessionAuthentication', #自己服务器认证用户 ] }
2, 局部配置(views.py)
- python
#1,视图集 class BookInfoModelViewSet(ModelViewSet): ... #1,局部认证 authentication_classes = [SessionAuthentication]
注意点:
- 如果配置了全局和局部, 默认使用局部
6,权限Permissions
目的: 可以参考官方文档, 配置权限内容
操作流程:
1, 全局权限配置(settings.py)
- python
REST_FRAMEWORK = { #1,全局认证 ... #2,全局权限 'DEFAULT_PERMISSION_CLASSES': [ # 'rest_framework.permissions.IsAuthenticated', #普通用户 # 'rest_framework.permissions.AllowAny', #所有用户 'rest_framework.permissions.IsAdminUser', #管理员户 ] }
2, 局部权限配置(views.py)
- python
#1,视图集 class BookInfoModelViewSet(ModelViewSet): ... #1,局部认证 ... #2,局部权限 # permission_classes = [AllowAny]
7,限流Throttling
目的: 可以通过配置, 限制不同用户的访问次数
操作流程:
1, 全局配置
- python
# DRF配置信息 REST_FRAMEWORK = { #1,全局认证 'DEFAULT_AUTHENTICATION_CLASSES': [ 'rest_framework.authentication.BasicAuthentication', #此身份验证方案使用HTTP基本身份验证,用于测试使用 'rest_framework.authentication.SessionAuthentication', #自己服务器认证用户 ], #2,全局权限 # 'DEFAULT_PERMISSION_CLASSES': [ # # 'rest_framework.permissions.IsAuthenticated', #普通用户 # # 'rest_framework.permissions.AllowAny', #所有用户 # 'rest_framework.permissions.IsAdminUser', #管理员户 # ], #3,全局限流 'DEFAULT_THROTTLE_CLASSES': [ 'rest_framework.throttling.AnonRateThrottle', #匿名用户 'rest_framework.throttling.UserRateThrottle' # 认证用户 ], 'DEFAULT_THROTTLE_RATES': { 'anon': '2/minute', 'user': '3/minute' } }
2, 局部配置
- python
#1,视图集 class BookInfoModelViewSet(ModelViewSet): queryset = BookInfo.objects.all() serializer_class = BookInfoModelSerializer #1,局部认证 # authentication_classes = [SessionAuthentication] #2,局部权限 # permission_classes = [AllowAny] #3,局部限流 throttle_classes = [AnonRateThrottle]
8, 可选限流
目的: 可以定义可选限流, 用在不同的类视图中
操作流程:
1, 全局定义
- python
# DRF配置信息 REST_FRAMEWORK = { ... #4,可选限流 'DEFAULT_THROTTLE_CLASSES': [ 'rest_framework.throttling.ScopedRateThrottle', ], 'DEFAULT_THROTTLE_RATES': { 'downloads': '3/minute', 'uploads': '5/minute' } }
2, 局部使用
- python
class TestView(APIView): throttle_scope = "uploads" def get(self,request): return Response("testing....")
url可选参数设置
9,分页Pagination
目的: 可以参考文档, 设置分页返回
操作流程:
1, 全局配置
- python
REST_FRAMEWORK = { ... #5,全局分页 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination', 'PAGE_SIZE': 2 }
2, 局部配置
- python
class BookInfoModelViewSet(ModelViewSet): ... #5,局部分页 # pagination_class = LimitOffsetPagination # ?limit=100 或者 ?offset=400&limit=100 pagination_class = PageNumberPagination # ?page=4
10, 自定义分页类
目的: 可以自定义类, 实现指定分页大小效果
操作流程:
1, 类视图
- python
#自定义分页对象 class MyPageNumberPagination(PageNumberPagination): #1,默认的大小 page_size = 3 #2,前端可以指定页面大小 page_size_query_param = 'page_size' #3,页面的最大大小 max_page_size = 5 #1,视图集 class BookInfoModelViewSet(ModelViewSet): ... #6,自定义分页对象 pagination_class = MyPageNumberPagination # ?page=4 或者 ?page=4&page_size=100
11,过滤Filtering
目的: 可以根据文档配置,进行过滤数据获取
操作流程:
1, 安装扩展django-filters
- pip install django-filter
2, 注册子应用
INSTALLED_APPS = [ ... 'django_filters', ]
3, 全局配置
- python
REST_FRAMEWORK = { ... 'DEFAULT_FILTER_BACKENDS': ['django_filters.rest_framework.DjangoFilterBackend'] }
4, 全局配置(views.py)
class BookInfoModelViewSet(ModelViewSet): .... #7,局部过滤 filter_backends = [DjangoFilterBackend] filterset_fields = ['id', 'btitle',"is_delete"]
12,排序OrderingFilter
目的: 可以参考文档, 使用指定的字段进行排序
操作流程:
1, 类视图
- python
class BookInfoModelViewSet(ModelViewSet): .... #8,局部排序 filter_backends = [filters.OrderingFilter] # 导包路径: from rest_framework import filters ordering_fields = ['id', 'btitle','bread'] #查询格式: ?ordering=-bread,id
其他
13,异常处理Exceptions
目的: 可以参考文档, 处理程序中的异常信息
操作流程:
1, 定义自定义处理方法(booktest/my_exception.py)
- python
from rest_framework.views import exception_handler from rest_framework.response import Response from django.db import DatabaseError def custom_exception_handler(exc, context): #1,调用系统方法,处理了APIException的异常,或者其子类异常 response = exception_handler(exc, context) #2,判断response是否有值 if response is not None: response.data['status_code'] = response.status_code else: if isinstance(exc, DatabaseError): response = Response("数据库大出血") else: response = Response("其他异常!") return response
2, 全局配置(settings.py)
- python
REST_FRAMEWORK = { ... 'EXCEPTION_HANDLER': 'booktest.my_exception.custom_exception_handler' }
3, 测试(views.py)
- python
class TestView(APIView): # throttle_scope = "uploads" def get(self,request): # raise DatabaseError("DatabaseError!!!") raise Exception("报错了!!!") # raise APIException("APIException!!!") # raise ValidationError("ValidationError!!!") return Response("testing....")
14,接口文档(了解)
目的: 可以参考文档, 配置后端数据的入口文档
操作流程:
1,安装扩展
- pip install coreapi
2, 根路由
- url(r'^docs/', include_docs_urls(title='我的API文档'))
3, 修改字段说明信息
模型类
- btitle = models.CharField(max_length=20, verbose_name='名称',help_text="书籍标题")
序列化器
- python
#1,模型类序列化器 class BookInfoModelSerializer(serializers.ModelSerializer): class Meta: ... extra_kwargs = { 'bread':{ 'help_text':"书籍阅读量" } }