复合类型
此笔记记录于Rust Course,大多数为其中的摘要,少数为笔者自己的理解
字符串与切片
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}这段代码会编译报错,因为在rust中,字符串字面量与String复合类型是无法自动转换的。
切片
字符串字面量是切片,字符串切片的类型标识是 &str
let s: &str = "Hello, world!";对于字符串而言,切片就是对 String 类型中某一部分的引用,它看起来像这样:
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];获取完整的切片
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
let s = "中国人";
let a = &s[0..2];
println!("{}",a);因此,当你需要对字符串做切片索引操作时,需要格外小心这一点, 关于该如何操作 UTF-8 字符串,参见这里。
其他切片
因为切片是对集合的部分引用,因此不仅仅字符串有切片,其它集合类型也有,例如数组:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);该数组切片的类型是 &[i32],数组切片和字符串切片的工作方式是一样的,例如持有一个引用指向原始数组的某个元素和长度。
什么是字符串
顾名思义,字符串是由字符组成的连续集合,但是在上一节中我们提到过,Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4),这样有助于大幅降低字符串所占用的内存空间。
Rust 在语言级别,只有一种字符串类型: str,它通常是以引用类型出现 &str,也就是上文提到的字符串切片。虽然语言级别只有上述的 str 类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是 String 类型。
str 类型是硬编码进可执行文件,也无法被修改,但是 String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
String与&str的转换
从 &str 类型生成 String 类型的操作:
String::from("hello,world")"hello,world".to_string()
String 类型转为 &str 类型:
fn main() {
let s = String::from("hello,world!");
say_hello(&s);
say_hello(&s[..]);
say_hello(s.as_str());
}
fn say_hello(s: &str) {
println!("{}",s);
}字符串索引
在其它语言中,使用索引的方式访问字符串的某个字符或者子串是很正常的行为,但是在 Rust 中就会报错:
let s1 = String::from("hello");
let h = s1[0];该代码会产生如下错误:
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`深入字符串内部
字符串的底层的数据存储格式实际上是[ u8 ],一个字节数组。对于 let hello = String::from("Hola"); 这行代码来说,Hola 的长度是 4 个字节,因为 "Hola" 中的每个字母在 UTF-8 编码中仅占用 1 个字节,但是对于下面的代码呢?
let hello = String::from("中国人");如果问你该字符串多长,你可能会说 3,但是实际上是 9 个字节的长度,因为大部分常用汉字在 UTF-8 中的长度是 3 个字节,因此这种情况下对 hello 进行索引,访问 &hello[0] 没有任何意义,因为你取不到 中 这个字符,而是取到了这个字符三个字节中的第一个字节,这是一个非常奇怪而且难以理解的返回值。
字符串的不同表现形式
现在看一下用梵文写的字符串 “नमस्ते”, 它底层的字节数组如下形式:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]长度是 18 个字节,这也是计算机最终存储该字符串的形式。如果从字符的形式去看,则是:
['न', 'म', 'स', '्', 'त', 'े']但是这种形式下,第四和六两个字母根本就不存在,没有任何意义,接着再从字母串的形式去看:
["न", "म", "स्", "ते"]所以,可以看出来 Rust 提供了不同的字符串展现方式,这样程序可以挑选自己想要的方式去使用,而无需去管字符串从人类语言角度看长什么样。
还有一个原因导致了 Rust 不允许去索引字符串:因为索引操作,我们总是期望它的性能表现是 O(1),然而对于 String 类型来说,无法保证这一点,因为 Rust 可能需要从 0 开始去遍历字符串来定位合法的字符。
操作字符串
push
fn main() {
let mut s = String::from("Hello ");
s.push_str("rust");
println!("追加字符串 push_str() -> {}", s);
s.push('!');
println!("追加字符 push() -> {}", s);
}insert
fn main() {
let mut s = String::from("Hello rust!");
s.insert(5, ',');
println!("插入字符 insert() -> {}", s);
s.insert_str(6, " I like");
println!("插入字符串 insert_str() -> {}", s);
}replace
- replace
fn main() {
let string_replace = String::from("I like rust. Learning rust is my favorite!");
let new_string_replace = string_replace.replace("rust", "RUST");
dbg!(new_string_replace);
}- replacen
该方法可适用于 String 和 &str 类型。replacen() 方法接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。该方法是返回一个新的字符串,而不是操作原来的字符串。
fn main() {
let string_replace = "I like rust. Learning rust is my favorite!";
let new_string_replacen = string_replace.replacen("rust", "RUST", 1);
dbg!(new_string_replacen);
}- replace_range
该方法仅适用于 String 类型。replace_range 接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用 mut 关键字修饰。
fn main() {
let mut string_replace_range = String::from("I like rust!");
string_replace_range.replace_range(7..8, "R");
dbg!(string_replace_range);
}delete
- pop -- 删除并返回字符串的最后一个字符
fn main() {
let mut string_pop = String::from("rust pop 中文!");
let p1 = string_pop.pop();
let p2 = string_pop.pop();
dbg!(p1);
dbg!(p2);
dbg!(string_pop);
}- remove -- 删除并返回字符串中指定位置的字符
fn main() {
let mut string_remove = String::from("测试remove方法");
println!(
"string_remove 占 {} 个字节",
std::mem::size_of_val(string_remove.as_str())
);
// 删除第一个汉字
string_remove.remove(0);
// 下面代码会发生错误
// string_remove.remove(1);
// 直接删除第二个汉字
// string_remove.remove(3);
dbg!(string_remove);
}- truncate -- 删除字符串中从指定位置开始到结尾的全部字符
fn main() {
let mut string_truncate = String::from("测试truncate");
string_truncate.truncate(3);
dbg!(string_truncate);
}- clear -- 清空字符串
fn main() {
let mut string_clear = String::from("string clear");
string_clear.clear();
dbg!(string_clear);
}concatenate
1、使用 + 或者 += 连接字符串
使用 + 或者 += 连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用 + 的操作符时,相当于调用了 std::string 标准库中的 add() 方法,这里 add() 方法的第二个参数是一个引用的类型。因此我们在使用 +, 必须传递切片引用类型。不能直接传递 String 类型。+ 是返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰。
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
// &string_rust会自动解引用为&str
let result = string_append + &string_rust;
let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的
result += "!!!";
println!("连接字符串 + -> {}", result);
}fn main() {
let s1 = String::from("hello,");
let s2 = String::from("world!");
// 在下句中,s1的所有权被转移走了,因此后面不能再使用s1
let s3 = s1 + &s2;
assert_eq!(s3,"hello,world!");
// 下面的语句如果去掉注释,就会报错
// println!("{}",s1);
}self 是 String 类型的字符串 s1,该函数说明,只能将 &str 类型的字符串切片添加到 String 类型的 s1 上,然后返回一个新的 String 类型,所以 let s3 = s1 + &s2; 就很好解释了,将 String 类型的 s1 与 &str 类型的 s2 进行相加,最终得到 String 类型的 s3。
由此可推,以下代码也是合法的:
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
// String = String + &str + &str + &str + &str
let s = s1 + "-" + &s2 + "-" + &s3;- 使用
format!连接字符串
fn main() {
let s1 = "hello";
let s2 = String::from("rust");
let s = format!("{} {}!", s1, s2);
println!("{}", s);
}字符串转义
略
操作UTF-8字符串
按字符遍历:
for c in "中国人".chars() {
println!("{}", c);
}按字节遍历:
for b in "中国人".bytes() {
println!("{}", b);
}获取子串:使用库utf8_slice
元组
创建
元组是由多种类型组合到一起形成的,因此它是复合类型,元组的长度是固定的,元组中元素的顺序也是固定的。
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}用模式匹配解构元组
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {}", y);
}用.来访问元组
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}元组的使用案例
元组在函数返回值场景很常用,例如下面的代码,可以使用元组返回多个值
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的长度
(s, length)
}但是这里返回的有一个缺陷:不具备任何清晰的含义,在下一章节中,会提到一种与元组类似的结构体,元组结构体,可以解决这个问题。
结构体
其它语言也有类似的数据结构,不过可能有不同的名称,例如 object、 record 等。与元组不同的是,结构体可以为内部的每个字段起一个富有含义的名称。因此结构体更加灵活更加强大,你无需依赖这些字段的顺序来访问和解析它们。
语法
定义结构体
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}创建结构体实例
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};访问结构体字段
let mut user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");简化结构体创建
fn build_user(email: String, username: String) -> User {
User {
email,
username,
active: true,
sign_in_count: 1,
}
}结构体更新语法
let user2 = User {
email: String::from("another@example.com"),
..user1
};.. 语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。需要注意的是 ..user1 必须在结构体的尾部使用。
结构体更新语法跟赋值语句
=非常相像,因此在上面代码中,user1的部分字段所有权被转移到user2中:username字段发生了所有权转移,作为结果,user1无法再被使用。
内存排列
struct File {
name: String,
data: Vec<u8>,
}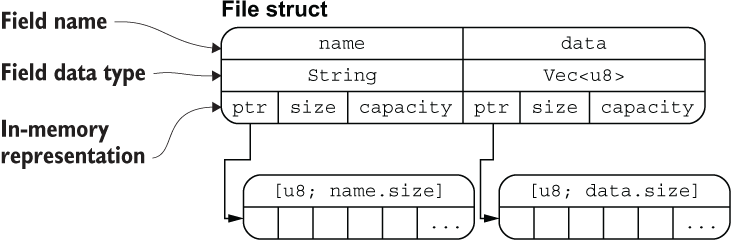
从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
元组结构体
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得很像元组,因此被称为元组结构体,例如:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);单元结构体
如果你定义一个类型,但是不关心该类型的内容, 只关心它的行为时,就可以使用 单元结构体:
struct AlwaysEqual;
let subject = AlwaysEqual;
// 我们不关心 AlwaysEqual 的字段数据,只关心它的行为,因此将它声明为单元结构体,然后再为它实现某个特征
impl SomeTrait for AlwaysEqual {
}结构体数据的所有权
使用#[derive(Debug)]来打印结构体的信息
在前面的代码中我们使用 #[derive(Debug)] 对结构体进行了标记,这样才能使用 println!("{:?}", s); 的方式对其进行打印输出,如果不加,看看会发生什么:
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {}", rect1);
}首先可以观察到,上面使用了 {} 而不是之前的 {:?},运行后报错。
提示我们结构体 Rectangle 没有实现 Display 特征,这是因为如果我们使用 {} 来格式化输出,那对应的类型就必须实现 Display 特征,以前学习的基本类型,都默认实现了该特征。
那么结构体为什么不默认实现 Display 特征呢?原因在于结构体较为复杂,例如考虑以下问题:你想要逗号对字段进行分割吗?需要括号吗?加在什么地方?所有的字段都应该显示?类似的还有很多,由于这种复杂性,Rust 不希望猜测我们想要的是什么,而是把选择权交给我们自己来实现:如果要用 {} 的方式打印结构体,那就自己实现 Display 特征。
这种格式是 Rust 自动为我们提供的实现,看上基本就跟结构体的定义形式一样。
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {:?}", rect1);
}当结构体较大时,我们可能希望能够有更好的输出表现,此时可以使用 {:#?} 来替代 {:?},输出如下:
rect1 is Rectangle {
width: 30,
height: 50,
}此时结构体的输出跟我们创建时候的代码几乎一模一样了!当然,如果大家还是不满足,那最好还是自己实现 Display 特征,以向用户更美的展示你的私藏结构体。关于格式化输出的更多内容,我们强烈推荐看看这个章节。
还有一个简单的输出 debug 信息的方法,那就是使用 dbg! 宏,它会拿走表达式的所有权,然后打印出相应的文件名、行号等 debug 信息,当然还有我们需要的表达式的求值结果。除此之外,它最终还会把表达式值的所有权返回!
dbg!输出到标准错误输出stderr,而println!输出到标准输出stdout。
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}枚举
创建:
enum PokerSuit {
Clubs,
Spades,
Diamonds,
Hearts,
}访问:
let heart = PokerSuit::Hearts;
let diamond = PokerSuit::Diamonds;更复杂一点的例子:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let m1 = Message::Quit;
let m2 = Message::Move{x:1,y:1};
let m3 = Message::ChangeColor(255,255,0);
}Option枚举用于处理空值
enum Option<T> {
Some(T),
None,
}Option<T> 枚举是如此有用以至于它被包含在了 prelude(prelude 属于 Rust 标准库,Rust 会将最常用的类型、函数等提前引入其中,省得我们再手动引入)之中,你不需要将其显式引入作用域。另外,它的成员 Some 和 None 也是如此,无需使用 Option:: 前缀就可直接使用 Some 和 None。总之,不能因为 Some(T) 和 None 中没有 Option:: 的身影,就否认它们是 Option 下的卧龙凤雏。
let some_number = Some(5);
let some_string = Some("a string");
let absent_number: Option<i32> = None;如果使用 None 而不是 Some,需要告诉 Rust Option<T> 是什么类型的,因为编译器只通过 None 值无法推断出 Some 成员保存的值的类型。
当有一个 Some 值时,我们就知道存在一个值,而这个值保存在 Some 中。当有个 None 值时,在某种意义上,它跟空值具有相同的意义:并没有一个有效的值。那么,Option<T> 为什么就比空值要好呢?
简而言之,因为 Option<T> 和 T(这里 T 可以是任何类型)是不同的类型,例如,这段代码不能编译,因为它尝试将 Option<i8>(Option<T>) 与 i8(T) 相加:
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;很好!事实上,错误信息意味着 Rust 不知道该如何将 Option<i8> 与 i8 相加,因为它们的类型不同。当在 Rust 中拥有一个像 i8 这样类型的值时,编译器确保它总是有一个有效的值,我们可以放心使用而无需做空值检查。只有当使用 Option<i8>(或者任何用到的类型)的时候才需要担心可能没有值,而编译器会确保我们在使用值之前处理了为空的情况。
数组
基本介绍
在 Rust 中,最常用的数组有两种:
- 第一种是速度很快但是长度固定的
array,存储在栈上 - 第二种是可动态增长的但是有性能损耗的
Vector,存储在堆上
这两个数组的关系跟
&str与String的关系很像,前者是长度固定的字符串切片,后者是可动态增长的字符串。其实,在 Rust 中无论是String还是Vector,它们都是 Rust 的高级类型:集合类型
数组的三要素:
- 长度固定
- 元素必须有相同的类型
- 依次线性排列
我们这里说的数组是 Rust 的基本类型,是固定长度的,这点与其他编程语言不同,其它编程语言的数组往往是可变长度的,与 Rust 中的动态数组 Vector 类似
创建数组
fn main() {
let a = [1, 2, 3, 4, 5];
}数组声明:
let a: [i32; 5] = [1, 2, 3, 4, 5];还可以使用下面的语法初始化一个某个值重复出现 N 次的数组:
let a = [3; 5];访问数组元素
fn main() {
let a = [9, 8, 7, 6, 5];
let first = a[0]; // 获取a数组第一个元素
let second = a[1]; // 获取第二个元素
}越界访问会直接抛出错误
数组元素位为非基本元素时,这么写会报错:
let array = [String::from("rust is good!"); 8];
println!("{:#?}", array);正确的写法:
let array: [String; 8] = std::array::from_fn(|_i| String::from("rust is good!"));
println!("{:#?}", array);数组切片
let a: [i32; 5] = [1, 2, 3, 4, 5];
let slice: &[i32] = &a[1..3];
assert_eq!(slice, &[2, 3]);切片的特点:
- 切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
- 创建切片的代价非常小,因为切片只是针对底层数组的一个引用
- 切片类型[T]拥有不固定的大小,而切片引用类型&[T]则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此&[T]更有用,
&str字符串切片也同理