继承的优缺点
此笔记记录于《流畅的python》,大部分为其中的摘要,少部分为笔者自己的理解;笔记为jupyter转的markdown,原始版jupyter笔记在这个仓库
(我们)推出继承的初衷是让新手顺利使用只有专家才能设计出来的框架。
子类化内置类型很麻烦
class DoppelDict(dict):
def __setitem__(self, key, value):
super().__setitem__(key, [value]*2)
# 这里如果是调用的子类的方法,就会存入两个相同的值dd = DoppelDict(one=1)
dd{'one': 1}
dd['two'] = 2
dd{'one': 1, 'two': [2, 2]}
dd.update(three=3)
dd{'one': 1, 'two': [2, 2], 'three': 3}
在这里__init__和.update方法都忽略了我们设置__setitem__方法,原生类型的这种行为违背了面向对象编程的一个基本原则:始终应该从实例(self)所属的类开始搜索方法,即使在超类实现的类中调用也是如此。在这种糟糕的局面中,__missing__方法(参见3.4.2节)却能按预期方式工作,不过这只是特例。
重点:直接子类化内置类型(如dict、list或str)容易出错,因为内置类型的方法通常会忽略用户覆盖的方法。不要子类化内置类型,用户自己定义的类应该继承collections模块中的类,例如UserDict、UserList和UserString,这些类做了特殊设计,因此易于扩展。
import collections
class DoppelDict2(collections.UserDict):
def __setitem__(self, key, value):
super().__setitem__(key, [value]*2)
# 这种就能正常工作了多重继承和方法解析顺序
任何实现多重继承的语言都要处理潜在的命名冲突,这种冲突由不相关的祖先类实现同名方法引起。
class A:
def ping(self):
print('ping:', self)
class B(A):
def pong(self):
print('pong:', self)
class C(A):
def pong(self):
print('PONG:', self)
class D(B, C):
def ping(self):
super().ping()
print('post-ping:', self)
def pingpong(self):
self.ping()
super().ping()
self.pong()
super().pong()
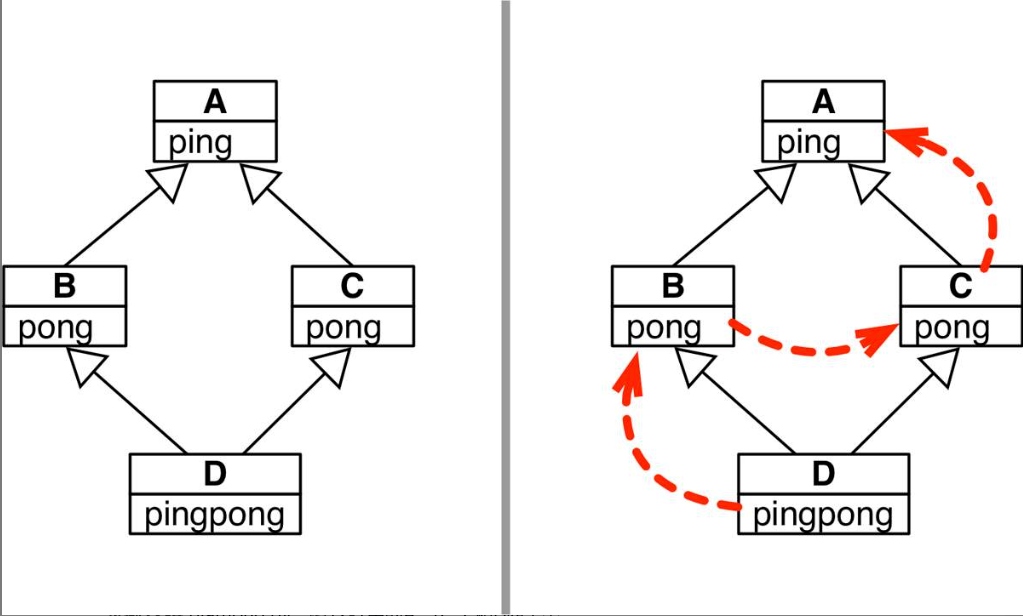
C.pong(self)在D的实例上调用d.pong( )方法的话,运行的是哪个pong方法呢?在C++中,程序员必须使用类名限定方法调用来避免这种歧义。Python也能这么做
d = D()
d.pong() # 直接调用是运行的B类中的方法pong: <__main__.D object at 0x000002AE19A3A5F0>
C.pong(d) # 超类调用是运行的C类中的方法(此时需要把实例作为显式参数传入)PONG: <__main__.D object at 0x000002AE19A3A5F0>
Python能区分d.pong( )调用的是哪个方法,是因为Python会按照特定的顺序遍历继承图。这个顺序叫方法解析顺序(Method Resolution Order,MRO)
类都有一个名为__mro__的属性,它的值是一个元组,按照方法解析顺序列出各个超类,从当前类一直向上,直到object类。D类的__mro__属性如下
D.__mro__(__main__.D, __main__.B, __main__.C, __main__.A, object)
若想把方法调用委托给超类,推荐的方式是使用内置的super( ),它会遵守方法解析顺序;
然而,有时可能需要绕过方法解析顺序,直接调用某个超类的方法——这样做有时更方便。例如,D.ping方法可以这样写:
def ping(self):
A.ping(self) #而不是super( ).ping( )
print('post-ping:', self)注意,直接在类上调用实例方法时,必须显式传入self参数,因为这样访问的是未绑定方法(unbound method)。
方法解析顺序使用C3算法计算。Michele Simionato的论文“The Python 2.3Method Resolution Order”对Python方法解析顺序使用的C3算法做了权威论述。
处理多重继承
使用多重继承容易得出令人费解和脆弱的设计。我们还没有完整的理论,下面是避免把类图搅乱的一些建议:
- 把接口继承和实现继承区分开
- 使用多重继承时,一定要明确一开始为什么创建子类。主要原因可能有:
- 继承接口,创建子类型,实现“是什么”关系
- 继承实现,通过重用避免代码重复
- 使用抽象基类显式表示接口
- 通过混入重用代码:如果一个类的作用是为多个不相关的子类提供方法实现,从而实现重用,但不体现“是什么”关系,应该把那个类明确地定义为混入类(mixin class)。
- 在名称中明确指明混入
- 抽象基类可以作为混入,反过来则不成立
- 不要子类化多个具体类:
class c(a, b, d),其中,如果a是具体类,那么b、d就不能是具体类,而应该是抽象基类或混入。 - 为用户提供聚合类
- 优先使用对象组合,而不是类继承