字典与集合
此笔记记录于《流畅的python》,大部分为其中的摘要,少部分为笔者自己的理解;笔记为jupyter转的markdown,原始版jupyter笔记在这个仓库
泛映射类型
collections.abc模块中有Mapping和MutableMapping这两个抽象基类,它们的作用是为dict和其他类似的类型定义形式接口
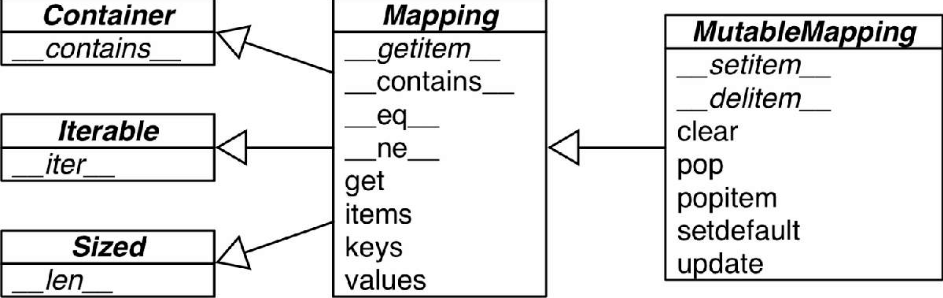
标准库里的所有映射类型都是利用dict来实现的,因此它们有个共同的限制,即只有可散列的数据类型才能用作这些映射里的键(只有键有这个要求,值并不需要是可散列的数据类型)
如果一个对象是可散列的,那么在这个对象的生命周期中,它的散列值是不变的,而且这个对象需要实现__hash__( )方法。另外可散列对象还要有__eq__( )方法,这样才能跟其他键做比较。如果两个可散列对象是相等的,那么它们的散列值一定是一样的
- 原子不可变数据类型(str、bytes和数值类型)都是可散列类型,frozenset也是可散列的,因为根据其定义,frozenset里只能容纳可散列类型。
- 元组的话,只有当一个元组包含的所有元素都是可散列类型的情况下,它才是可散列的。
一般来讲用户自定义的类型的对象都是可散列的,散列值就是它们的id( )函数的返回值,所以所有这些对象在比较的时候都是不相等的。如果一个对象实现了__eq__方法,并且在方法中用到了这个对象的内部状态的话,那么只有当所有这些内部状态都是不可变的情况下,这个对象才是可散列的。
tt = (1, 2, (30, 40))
hash(tt)-3907003130834322577
tl = (1, 2, [30, 40])
hash(tl)---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[4], line 2
1 tl = (1, 2, [30, 40])
----> 2 hash(tl)
TypeError: unhashable type: 'list'
tf = (1, 2, frozenset([30, 40]))
hash(tf)5149391500123939311
字典提供了多种构造方法
a = dict(one=1, two=2, three=3)
b = {'one': 1, 'two': 2, 'three': 3}
c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
d = dict({'three': 3, 'one': 1, 'two': 2})
e = dict([('two', 2), ('one', 1), ('three', 3)])
a == b == c == d == eTrue
# 字典推导(dict comprehension)也可以用来建造新dict
DIAL_CODES = [
(86, 'China'),
(91, 'India'),
(1, 'United States'),
(62, 'Indonesia'),
(55, 'Brazil'),
(92, 'Pakistan'),
(880, 'Bangladesh'),
(234, 'Nigeria'),
(7, 'Russia'),
(81, 'Japan'),
]
country_code = {country: code for code, country in DIAL_CODES}
country_code{'China': 86,
'India': 91,
'United States': 1,
'Indonesia': 62,
'Brazil': 55,
'Pakistan': 92,
'Bangladesh': 880,
'Nigeria': 234,
'Russia': 7,
'Japan': 81}
{code: country.upper() for country, code in country_code.items() if code < 66 }{1: 'UNITED STATES', 62: 'INDONESIA', 55: 'BRAZIL', 7: 'RUSSIA'}
| 方法名称 | 描述 |
|---|---|
| dict.clear() | 移除字典中所有元素 |
| dict.copy() | 返回字典的浅复制 |
| dict.fromkeys(seq[, val]) | 返回一个新字典,其中包含seq中的元素作为键,val作为所有键的值 |
| dict.get(key[, default]) | 返回字典中键的值,如果键不存在于字典中,则返回默认值 |
| dict.items() | 返回包含字典所有键值对的新视图 |
| dict.keys() | 返回包含字典所有键的新视图 |
| dict.pop(key[, default]) | 如果键存在于字典中,则删除并返回其值,否则返回默认值 |
| dict.popitem() | 删除并返回字典中的一个键值对(为了兼容性,返回最后一个键值对) |
| dict.setdefault(key[, default]) | 如果键存在于字典中,则返回其值。如果不在,则插入键,值为默认值,并返回默认值 |
| dict.update([other]) | 从其他字典或迭代器更新字典 |
| dict.values() | 返回包含字典所有值的新视图 |
可以用setdefault处理找不到的键
有时候为了方便起见,就算某个键在映射里不存在,我们也希望在通过这个键读取值的时候能得到一个默认值。有两个途径能帮我们达到这个目的:
- 一个是通过defaultdict这个类型而不是普通的dict
- 另一个是给自己定义一个dict的子类,然后在子类中实现__missing__方法。
import collections
index = collections.defaultdict(list)
index['unknown word'][]
如果有一个类继承了dict,然后这个继承类提供了__missing__方法,那么在__getitem__碰到找不到的键的时候,Python就会自动调用它,而不是抛出一个KeyError异常。
class StrKeyDict0(dict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys([]) or str(key) in self.keys([])字典的变种
collections.OrderedDict: 这个类型在添加键的时候会保持顺序,因此键的迭代次序总是一致的。collections.ChainMap: 这个类型可以容纳数个不同的映射对象,然后在进行键查找的时候,这些对象会被当作一个整体被逐个查找,直到键被找到为止。collections.Counter: 这个映射类型会给键准备一个整数计数器。每次更新一个键的时候都会增加这个计数器。所以这个类型可以用来给可散列对象计数,它在其他语言中也被称为bag或multiset。collections.UserDict: 这个类型其实就是把标准dict用纯Python又实现了一遍。这是通过继承collections.MutableMapping来实现的,这是一个抽象基类,它提供了全部需要的方法来让UserDict的子类表现得像一个字典。
就创造自定义映射类型来说,以UserDict为基类,总比以普通的dict为基类要来得方便。而更倾向于从UserDict而不是从dict继承的主要原因是,后者有时会在某些方法的实现上走一些捷径,导致我们不得不在它的子类中重写这些方法,但是UserDict就不会带来这些问题
# 无论是添加、更新还是查询操作,都会把值转换成字符串
import collections
class StrKeyDict(collections.UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item因为UserDict继承的是MutableMapping,所以StrKeyDict里剩下的那些映射类型的方法都是从UserDict、MutableMapping和Mapping这些超类继承而来的。特别是最后的Mapping类,它虽然是一个抽象基类(ABC),但它却提供了好几个实用的方法。以下两个方法值得关注:
MutableMapping.update:这个方法不但可以为我们所直接利用,它还用在__init__里,让构造方法可以利用传入的各种参数(其他映射类型、元素是(key, value)对的可迭代对象和键值参数)来新建实例。因为这个方法在背后是用self[key]=value来添加新值的,所以它其实是在使用我们的__setitem__方法。
所以这就是为什么要继承UserDict而不是dict的原因:后者调用时可能会偷懒
Mapping.get:这个在__getitem__里被调用,为的是使用一个默认值来返回那些找不到对应键的情况。而且,这个方法在背后其实是用self[key] if key in self else default这样的形式来实现的,所以它其实是在使用我们的__getitem__方法。
不可变映射类型
从Python 3.3开始,types模块中引入了一个封装类名叫MappingProxyType。如果给这个类一个映射,它会返回一个只读的映射视图。虽然是个只读视图,但是它是动态的。这意味着如果对原映射做出了改动,我们通过这个视图可以观察到,但是无法通过这个视图对原映射做出修改。
from types import MappingProxyType
d = {1: 'A'}
d_proxy = MappingProxyType(d)
d_proxymappingproxy({1: 'A'})
d_proxy[1]'A'
d_proxy[2] = 'X'---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[14], line 1
----> 1 d_proxy[2] = 'X'
TypeError: 'mappingproxy' object does not support item assignment
# 但是可以直接修改源
d[2] = 'B'
d_proxymappingproxy({1: 'A', 2: 'B'})
集合论
集合的本质是许多唯一对象的聚集。因此,集合可以用于去重
集合中的元素必须是可散列的,set类型本身是不可散列的,但是frozenset可以。因此可以创建一个包含不同frozenset的set。
l = ['spam', 'spam', 'eggs', 'spam']
set(l){'eggs', 'spam'}
list(set(l))['eggs', 'spam']
除了保证唯一性,集合还实现了很多基础的中缀运算符。给定两个集合a和b,a | b返回的是它们的合集,a & b得到的是交集,而a-b得到的是差集。
空集之外,集合的字面量——{1}、{1, 2},等等——看起来跟它的数学形式一模一样。如果是空集,那么必须写成set( )的形式
像{1, 2, 3}这种字面量句法相比于构造方法(set([1, 2, 3]))要更快且更易读。后者的速度要慢一些,因为Python必须先从set这个名字来查询构造方法,然后新建一个列表,最后再把这个列表传入到构造方法里。
# 用dis.dis(反汇编函数)来看看两个方法的字节码的不同
from dis import dis
dis('{1}') 1 0 LOAD_CONST 0 (1)
2 BUILD_SET 1
4 RETURN_VALUE
dis('set([1])') 1 0 LOAD_NAME 0 (set)
2 LOAD_CONST 0 (1)
4 BUILD_LIST 1
6 CALL_FUNCTION 1
8 RETURN_VALUE
集合推导
from unicodedata import name
{chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i), '')}{'#',
'$',
'%',
'+',
'<',
'=',
'>',
'¢',
'£',
'¤',
'¥',
'§',
'©',
'¬',
'®',
'°',
'±',
'µ',
'¶',
'×',
'÷'}
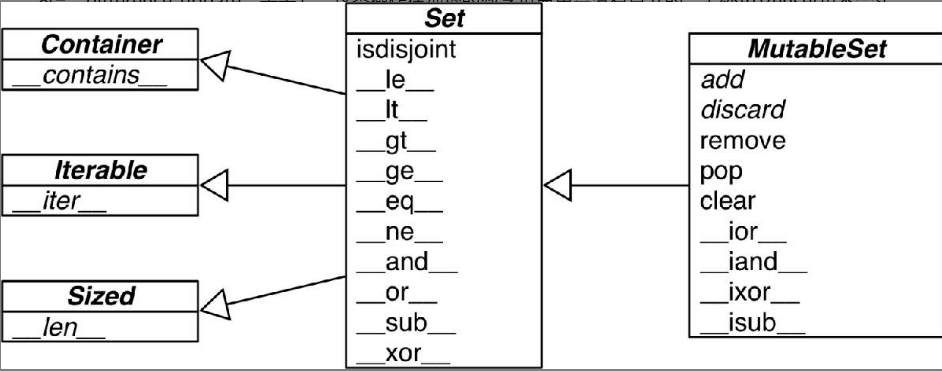
集合相关的操作:
| 操作 | 描述 |
|---|---|
set1.union(set2) | 返回一个新的集合,包含set1和set2中所有的元素 |
set1.intersection(set2) | 返回一个新的集合,包含set1和set2中的公共元素 |
set1.difference(set2) | 返回一个新的集合,包含set1中存在但set2中不存在的元素 |
set1.symmetric_difference(set2) | 返回一个新的集合,包含set1和set2中不重叠的元素 |
set1.issubset(set2) | 如果set1是set2的子集,则返回True,否则返回False |
set1.issuperset(set2) | 如果set1是set2的超集,则返回True,否则返回False |
set1.isdisjoint(set2) | 如果set1和set2没有共同的元素,则返回True,否则返回False |
set1.add(elem) | 在set1中添加元素elem |
set1.remove(elem) | 从set1中删除元素elem,如果elem不存在,则会报错 |
set1.discard(elem) | 从set1中删除元素elem,如果elem不存在,不会报错 |
set1.pop() | 移除并返回set1中的一个元素,如果set1为空,会报错 |
set1.clear() | 移除set1中的所有元素 |
dict与set的背后
一个基准测试,用in运算符在5个不同大小的haystack字典里搜索1000个元素所需要的时间:
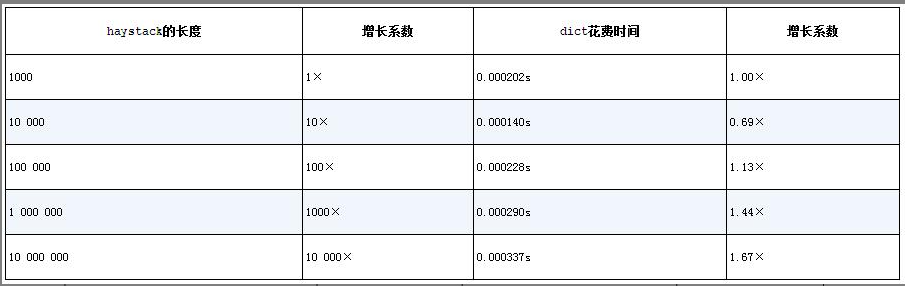
也就是说,在我的笔记本上从1000个字典键里搜索1000个浮点数所需的时间是0.000202秒,把同样的搜索在含有10000000个元素的字典里进行一遍,只需要0.000337秒。
增加列表进行测试对比:
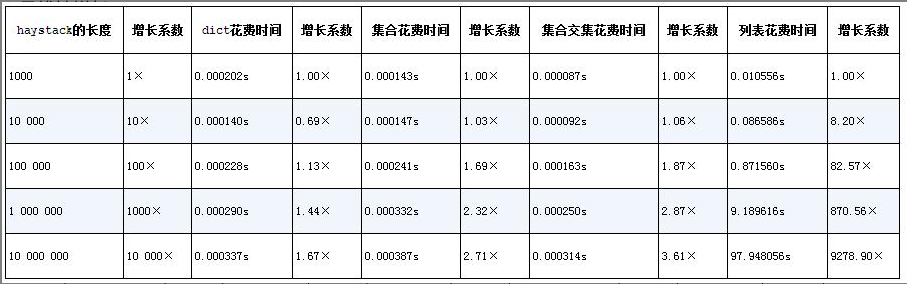
散列表的内部结构:散列表其实是一个稀疏数组(总是有空白元素的数组称为稀疏数组)。在一般的数据结构教材中,散列表里的单元通常叫作表元(bucket)。在dict的散列表当中,每个键值对都占用一个表元,每个表元都有两个部分,一个是对键的引用,另一个是对值的引用。因为所有表元的大小一致,所以可以通过偏移量来读取某个表元。
因为Python会设法保证大概还有三分之一的表元是空的,所以在快要达到这个阈值的时候,原有的散列表会被复制到一个更大的空间里面。
如果要把一个对象放入散列表,那么首先要计算这个元素键的散列值。Python中可以用hash( )方法来做这件事情
散列值和相等性:
内置的hash( )方法可以用于所有的内置类型对象。如果是自定义对象调用hash( )的话,实际上运行的是自定义的__hash__。如果两个对象在比较的时候是相等的,那它们的散列值必须相等,否则散列表就不能正常运行了。例如,如果1==1.0为真,那么hash(1)==hash(1.0)也必须为真,但其实这两个数字(整型和浮点)的内部结构是完全不一样的
为了让散列值能够胜任散列表索引这一角色,它们必须在索引空间中尽量分散开来。这意味着在最理想的状况下,越是相似但不相等的对象,它们散列值的差别应该越大。
从
Python 3.3开始,str、bytes和datetime对象的散列值计算过程中多了随机的“加盐”这一步。所加盐值是Python进程内的一个常量,但是每次启动Python解释器都会生成一个不同的盐值。随机盐值的加入是为了防止DOS攻击而采取的一种安全措施。
散列表算法:
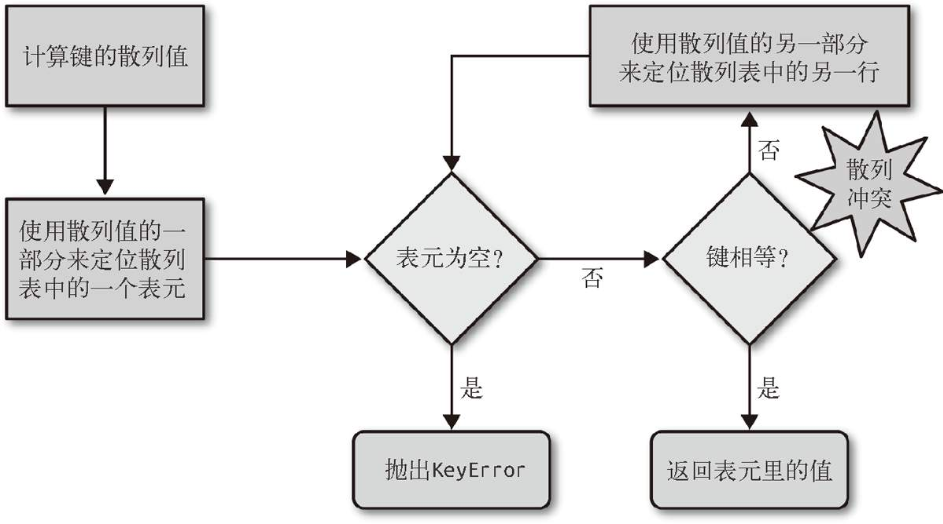
- 为了获取
my_dict[search_key]背后的值,Python首先会调用hash(search_key)来计算search_key的散列值,把这个值最低的几位数字当作偏移量,在散列表里查找表元(具体取几位,得看当前散列表的大小)。 - 如果找到的表元是空的,那么抛出一个
KeyError异常。 - 如果表元里不是空的,就会有一对
found_key:found_value。这时候Python会检查search_key==found_key是否为真,如果为真,就会返回found_value。 - 如果
search_key和found_key不相等,这种情况就叫作散列冲突,这时候Python会在散列表里的其他位置继续寻找,直到找到一个空表元。如果找到了一个空表元,那么就把search_key:search_value插入其中。 - 另外在插入新值时,Python可能会按照散列表的拥挤程度来决定是否要重新分配内存为它扩容。如果增加了散列表的大小,那散列值所占的位数和用作索引的位数都会随之增加,这样做的目的是为了减少发生散列冲突的概率。
表面上看,这个算法似乎很费事,而实际上就算dict里有数百万个元素,多数的搜索过程中并不会有冲突发生,平均下来每次搜索可能会有一到两次冲突。在正常情况下,就算是最不走运的键所遇到的冲突的次数用一只手也能数过来
dict/set的优势和限制:
1.键必须是可散列的
一个可散列的对象必须满足以下要求:
- 支持
hash()函数,并且通过__hash__()方法所得到的散列值是不变的 - 支持通过
__eq__()方法来检测相等性 - 若
a == b为真,则hash(a) == hash(b)也为真
所有由用户自定义的对象默认都是可散列的,因为它们的散列值由id( )来获取,而且它们都是不相等的。
2.字典在内存上的开销巨大:由于字典使用了散列表,而散列表又必须是稀疏的,这导致它在空间上的效率低下。
如果你需要存放数量巨大的记录,那么放在由元组或是具名元组构成的列表中会是比较好的选择;最好不要根据JSON的风格,用由字典组成的列表来存放这些记录。用元组取代字典就能节省空间的原因有两个:其一是避免了散列表所耗费的空间,其二是无需把记录中字段的名字在每个元素里都存一遍。
3.键查询很快:dict的实现是典型的空间换时间:字典类型有着巨大的内存开销,但它们提供了无视数据量大小的快速访问——只要字典能被装在内存里
4.键的次序取决于添加顺序:
当往dict里添加新键而又发生散列冲突的时候,新键可能会被安排存放到另一个位置。于是下面这种情况就会发生:由dict([(key1, value1), (key2, value2)])和dict([(key2,value2), (key1, value1)])得到的两个字典,在进行比较的时候,它们是相等的;但是如果在key1和key2被添加到字典里的过程中有冲突发生的话,这两个键出现在字典里的顺序是不一样的
与之形成鲜明对比的是PHP。在PHP手册中,数组的描述如下:PHP中的数组实际上是一个有序的映射——映射类型存放的是键值对。这个映射类型被优化为可充当不同的角色。它可以当作数组、列表(向量)、散列表(映射类型的一种实现)、字典、集合类型、栈、队列或其他可能的数据类型。
单凭这段话,我无法想象PHP把list和OrderedDict混合实现的成本有多大。
PHP和Ruby的散列语法借鉴了Perl,它们都用=>作为键和值的连接。JavaScript则从Python那儿偷师,使用了:。而JSON又从JavaScript发展而来,它的语法正好是Python句法的子集。因此,除了在true、false和null这几个值的拼写上有出入之外,JSON和Python是完全兼容的。