Node模块规范及模块加载机制
这是重新阅读《深入浅出NodeJS》的相关笔记,这次阅读发现自己依旧收获很多,而第一次阅读的东西也差不多忘记完了,所以想着这次过一遍脑子,用自己的理解输出一下,方便记忆以及以后回忆...
历史原因,JavaScript以前是没有模块机制的,这对于node来说想要编写一个大型项目是很难的,所以node采用了社区提出的CommmonJS规范
认识CommonJS
这里主要介绍的是大家常见的
JavaScript文件模块,其他的将在后续章节介绍
CommonJS对模块的定义非常简单,主要分为模块引用、模块定义和模块标识三个部分:
比如我们有如下很常见的代码:
const math = require('math')- 模块引用:
const math中的math就是模块引用 - 模块标识:
require('math')中的math就是模块标识,必须是以小驼峰命名的字符串或者路径 - 模块定义:简单理解就是一个文件就是一个模块,模块中 存在一个
module对象,这个对象包含一个exports属性,我们只要将该文件上的方法挂载到exports对象,其他文件就可以引入了,而没有导出的方法/变量就会被隔离,从而避免变量污染
这里模块定义讲得比较粗糙,接下来将具体讲讲node中对于CommonJS规范的实现:
JavaScript文件模块CommonJS实现
刚才已经简单介绍了node中对于模块使用的一些语法,比如可以通过require引入,通过exports导出等等,同时,如果你不是前端领域的新手,你应该也知道我们在node环境中编写代码时,还可以使用__filename和__dirname这两个变量
但是似乎我们自己并没有定义这些对象/变量,就可以直接使用,所以这就引出了该小节将要解释的--node对于JavaScript文件模块的处理。
基础知识补充:基本上一个模块机制就是要解决作用域的问题,简单理解就是我们在编写自己的模块时,变量命名这些不会影响到其他模块。同时,要使我们编写的模块有用,我们还会导出一些出口方便其他模块使用,基本上就是一个封装的思想... 然后我们都知道函数是有自己的作用域的,函数内部的变量作用在该函数域内,所以node就基于此实现了该模块机制。
事实上,当我们执行node test.js的时候,也就是在编译的过程中,node会把获取的JavaScript文件内容封装到一个函数中,并且把解析该文件过程中的一些结果作为形参传入该函数,具体如下:
// test.js
console.log('用户写的一些代码逻辑')包装后:
(function (exports, require, module, __filename, __dirname) {
console.log('用户写的一些代码逻辑')
})所以我们平常在node环境中写的代码都会经过这样一个包装,这也就是我们刚才提到的为什么可以直接使用require、exports等属性的原因,同时也就实现了各个模块文件之间的作用域隔离。
注:对于不同的文件名,
node载入的方法也不同,.js的就是通过上述方法载入的,而其他的如.node、.json本篇文章不作详细介绍,除了上述这三个扩展名,其他扩展名的文件如果交给node执行,都会被当作.js文件载入。
接下来我将一一介绍node对我们代码进行包装处理的函数中的形参,相信认识了这几个参数,你就对node中实现的模块机制就理解的大差不差了,其中__filename、__dirname就是文件名和路径名,两个字符串就不详细介绍了,接下来主要介绍module、exports、require这三个参数的理解。
理解module参数,基本形成模块机制
我们可以自己尝试一下,新建一个test.js文件,加上console.log(module);这行代码,看看这个参数是什么:
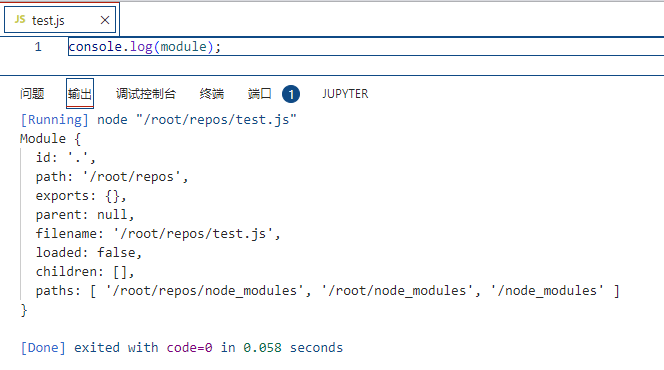
接下来详细介绍一个这个参数:module参数其实是node通过一个叫做Module的构造函数创建的一个实例,所以我们基本上认识这个构造函数就可以了,它的定义如下详细介绍:
function Module(id, parent) {
this.id = id; // 模块的标识符, 通常是完全解析后的文件名
this.exports = {};
this.parent = parent; // 最先引用该模块的模块
if (parent && parent.children) {
parent.children.push(this);
}
this.filename = null; // 模块的完全解析后的文件名
this.loaded = false; // 模块是否已经加载完成,或正在加载中
this.children = []; // 被该模块引用的模块对象
this.paths = []; // 模块的搜索路径
}node环境中每个文件都有由这个构造函数创建的唯一实例,一个文件对应一个module实例,我们可以把其理解为一个节点,这个节点有一些属性,如id、filename...等,然后这个节点的入度就是children属性,这样就可以抽象出一个模块引用图:
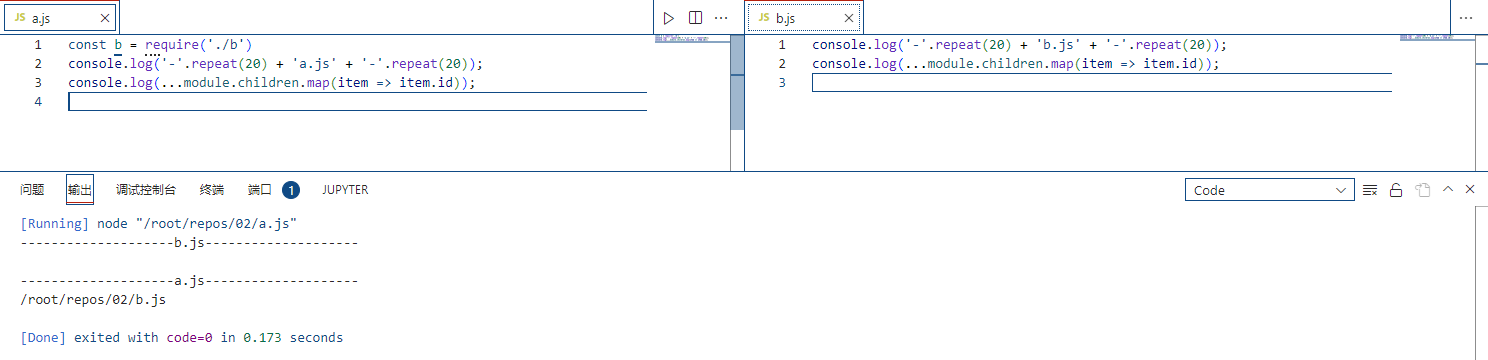
可以看到上述这两个简单的测试程序,我们执行a.js得到上述的输出,由于b.js中没有引用任何模块,所以在执行const b = require('./b.js')时不会得到输出。由此,我们其实可以得到这样一张模块引用图:

如果是大型项目,就会形成一个非常复杂的有向图了,而有了图这个数据结构,其实我们似乎就能用一些算法对模块应用进行一些分析处理,比如最简单、也是最容易想到的就是编写一个vscode插件来对一个node项目进行模块引用的分析并可视化,方便新接触项目成员快速熟悉项目,当然,要实现这个想法应该还要考虑更多,这里不深入...
继续,由此一个文件对应一个模块的机制通过module参数就实现了
理解exports参数
你可能会疑惑module实例对象中不是已经有了exports属性了吗,它与node处理文件中传入的exports形参有什么关系呢?这也是我最开始接触这个模块机制的时候产生的疑惑~
总的来说exports就是module.exports的快捷方式
一般来说,我们都是直接使用exports.hello = hello(){ console.log('hello') }导出即可,这样也是最方便并且最好辨认的。
但是你需要注意的是,exports是node包装我们编写的js文件使用的函数中的一个形参,文章开始部分也介绍过,既然exports是通过形参的方式传入的,如果我们要对其直接赋值exports = {hello: hello(){ console.log('hello')},会改变形参的引用,并不能修改作用域外的值,这是JavaScript的基础知识。
所以此时我们只能修改module.exports = {hello: hello(){ console.log('hello')}这样是可以的,但不建议这样做,多种方式的导出会使人迷惑,除非迫不得已。
最后,exports是一个对象,我们在当前函数作用域中向这个对象修改了属性,是可以反应在函数作用域外面的,因为是修改的引用对象类型。至此,我们就可以既实现作用域隔离避免变量污染,又可以暴露除该模块的功能方法,最终实现了这样一个模块机制
理解require是如何加载模块的 *
require()是我们导入别的模块需要用到的一个方法,就如本篇文章中的第一个例子const math = require('math'),它可以使我们非常方便地导入其他模块,但是它的内部实现其实相对来说比较复杂,因为require()函数除了可以加载上述中.js结尾的文件模块,还可以加载其他扩展名结尾的文件模块,以及node中内置的核心模块,甚至说传给require()的路径参数是一个目录,也需要一定的策略去解析它。
总的来说,在node中引入模块,需要经历如下三个步骤:
- 路径分析
- 文件定位
- 编译执行
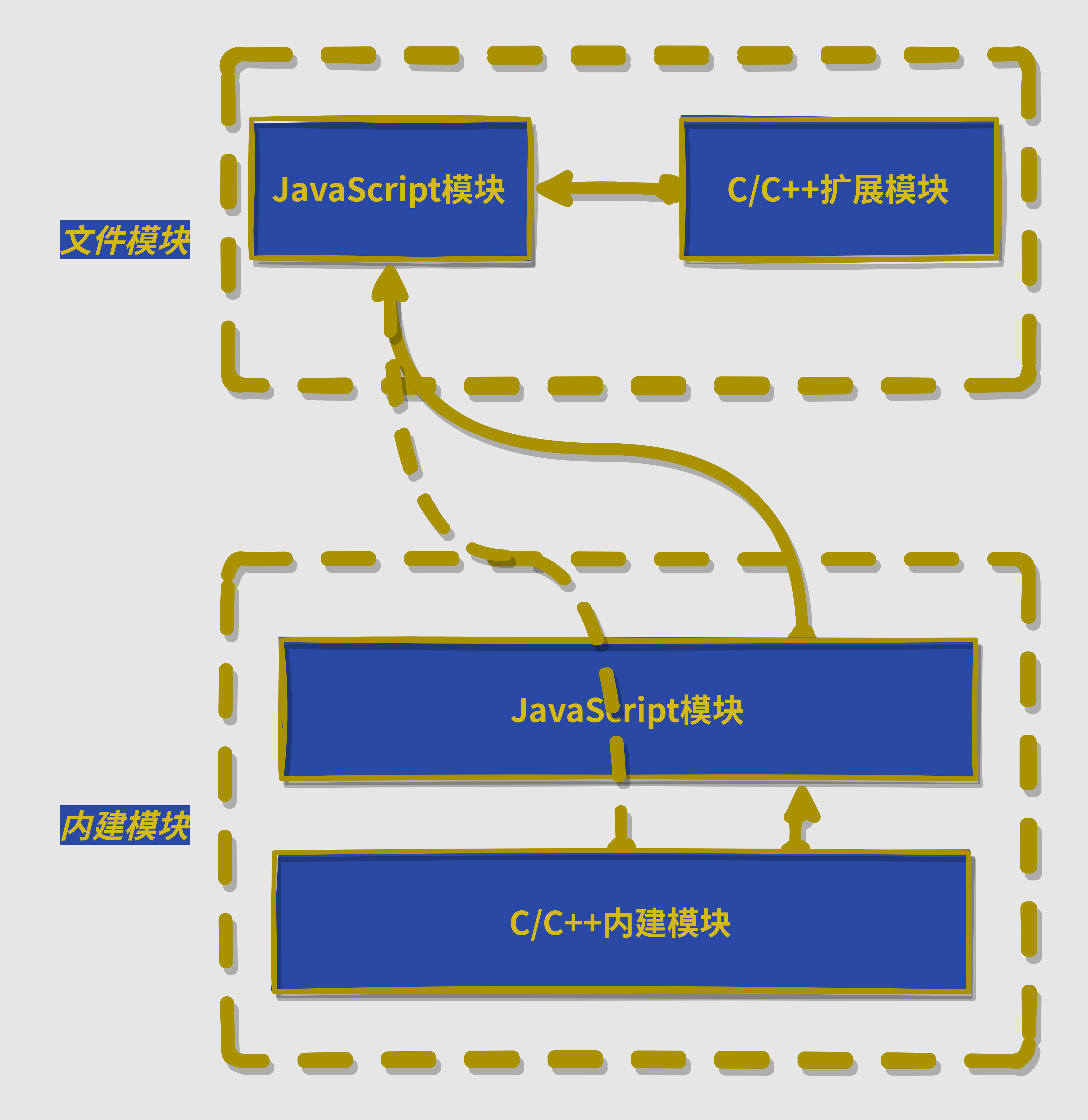
在讲解具体的模块加载过程之前,我们先了解一下上面提到的核心模块与文件模块之间的概念:
- 核心模块:在node源代码的编译过程中,就编译进了二进制执行文件。并且部分核心模块在
node启动的时候就被直接加载进了内存中,所以这部分核心模块引入时,文件定位和编译执行这两步可以省略,并且路径分析中优先判断,所以其加载速度最快 - 文件模块:之前介绍的
.js结尾的就是文件模块中的一种,文件模块在运行时动态加载,需要完整的路径分析、文件定位、编译执行过程,速度相对较慢。文件模块用可以路径形式的文件模块(用户自己编写的)和自定义文件模块(通常是第三方包)
接下来我们就用下方这个流程图来梳理一下当require引入一个模块标识的时候是如何判断的。基于此,我们可以对node的模块规范更加了解,并且可以在模块引入时做一些简单的性能优化:

模块加载流程口语描述:
- 首先
node会判断该模块之前是否加载过,在缓存中是否包含,如果包含,显然就可以直接从缓存中加载; - 然后就是根据传给
require的模块标识,判断该模块标识属于哪一类型,是模块名的字符串还是模块所在的路径 - 之后就是如果是否属于核心模块,
node自己心里清楚,内部存储相关的数组来记录,如果是自定义模块(就是平常我们经常见到的第三方包),就通过一个策略去查找该模块所在的路径,而这个策略是存储在module.paths中,你可以自行console.log观察一下,或者在之前介绍module的时候也有相关的打印信息; - 再然后我们获得了一个路径,这个路径如果有显式的文件扩展名,就按照上述方式加载,而如果没有扩展名,就按照
.js .json .node依次尝试,而有可能传递的是一个目录,此时node就会去找该目录下的packsge.json中的main属性对应的文件或者index文件名的文件 - 最后,如果都不行,就包找不到该文件的错误
上述在通过.js .json .node依次尝试是什么文件的时候,需要调用fs模块同步阻塞执行,所以如果是.node和.json最后就带上扩展名,会加快一点速度;
其他:
对于核心模块的加载,涉及到一些
c++代码,所以流程图中对其简化,这里大致讲一讲其中的流程,不感兴趣的可以略过这一部分:
对于核心模块,node中也分为两种,一种是由JavaScript编写的模块,一种是由C++/C编写的模块。一般来说,C++模块主内完成核心,JavaScript主外实现封装,Node这种静态语言结合脚本语言的复合模式在开发体验和性能之间找到平衡点。
对于由C/C++编写的模块一般也叫做内建模块,我们可以通过log如下信息打印除node中包含哪些内建模块:
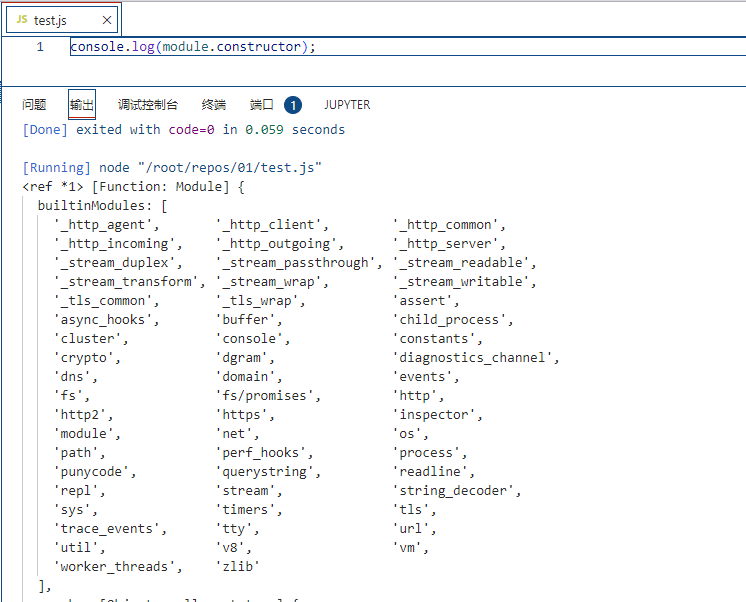
内建模块的加载:会先创建一个exports空对象,然后调用get_builtin_module()方法去除内建模块对象,通过执行register_func()填充exports对象,最后将exports对象按模块名缓存,并返回给调用方完成导出。
一般来说,node并不推荐直接加载内建模块,而是通过对应封装地JavaScript核心模块进行加载,一个完整地核心模块加载流程如下:
内建模块这块由于我缺乏实践,所以仅简单记录了一些要点,并不对其进行解释,如果你是这方面的新手,不推荐通过我这篇文章学习
一般来说,当
node性能出现瓶颈,我们是通过编写C++扩展模块进行性能优化的,下面是一个简单的模块调用图
Module对象其他的一些东西
我们在前面仅仅介绍了module实例中有哪些属性,但其实Module这个对象还挂载了一些属性:
Module._extensions:对于不同扩展名的文件的处理函数保存在这个属性上:

我们可以在此基础上自定义一些其他文件扩展名的处理函数,不过node并不建议我们这样做,官方建议先将其他语言或文件编译成为JavaScript文件后再加载,这样做的好处是在于不用将繁琐的编译加载过程引入node的执行过程中
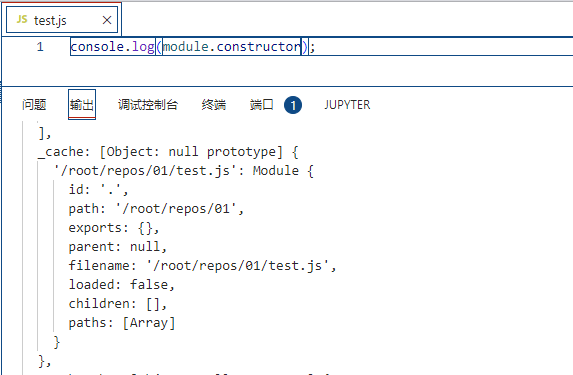
Module._cache:已经编译执行成功的文件模块会缓存到该对象上:
碎碎念
作为今年的应届生,之前跨部门转正二面问到这一方面,当时这些基础知识还有点印象,但是不多!最终挂掉了,回来也没能抓住秋招的尾巴,好好复习,all in 春招了💪