最近GPT帮我解决的30个问题
前言
Hello,各位朋友们大家好,好久不见了!
chatGPT已经问世快两年了,但我仍然发现我了解到的很多人都还只停留在惊叹chatGPT的能力,试用了一下,新鲜感一过,就没有再使用过了,偶尔才会想起。
但我确确实实已经离不开GPT(LLM)了,到什么程度了--无时无刻、无处不在、无微不至、无所不用其及,(好,打住),反正现在我几乎是只要打开电脑,就会有一个GPT的聊天应用一直挂在后台随时候着,甚至比微信用得还多(这似乎是一个悲伤的故事)
当然,我看到的许多文章也都谈到了大语言模型的应用场景,但是,这些文章给的应用场景都太宽泛了,太大了,就像这样:

这就导致很多人其实知道这个真的非常有用,但就是不知道在什么时候,在哪里使用。所以,这篇文章就来了,我会结合最近一段时间来的实际生活、工作、学习场景,从我以前的聊天记录中,找出一下印象深刻的案例来进行分享,这些可都是实打实的经验,希望对你有所帮助。
(声明:对大语言模型的理解比笔者好的大有人在,本文也希望抛砖引玉,能让笔者也了解到大家的使用场景,共同进步。并且笔者的背景是程序员,所以接下来的内容会以编码相关的内容为主要组成部分)
篇幅有限,为了尽可能展示多的例子,GPT的回答会省略一些(废话还是有点多,挺占篇幅的)
第一类:脚本类的代码生成
这里指的是泛脚本的内容,是一段简短的代码,通常放在一个文件中,能直接实现一项功能
1. 获取github readme生成热词词图
背景:
前段时间逛github发现一个仓库--中国独立开发者项目列表-分享大家都在做什么。挺多⭐的,但是内容挺多的,笔者被旁边的短短的滚动条给劝退了。
所以就想用Python直接获取这个readme里面的内容,提取出里面的热词并生成词图,这样就能在一张图上看到大家都在做些什么了。
- [x] GPT,启动!
对话:
问:用python对一份中文文档如https://github.com/1c7/chinese-independent-developer/blob/master/README.md做一下热词统计,并生成对应的热词图。
答:
为了完成这个任务,我们将分成几个步骤来实现:
- 获取文档内容:使用
requests库从指定的URL获取文档内容。- 提取中文文本:使用正则表达式提取中文文本。
- 分词:使用
jieba库对中文文本进行分词。- 统计词频:使用
collections.Counter来统计词频。- 生成热词图:使用
wordcloud库生成热词图。首先,确保你已经安装了
requests、jieba和wordcloud库。如果没有安装,可以通过以下命令安装:
pip install requests jieba wordcloud接下来是实现的代码:
import requests
import re
import jieba
from collections import Counter
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 1. 获取文档内容
url = "https://raw.githubusercontent.com/1c7/chinese-independent-developer/master/README.md"
response = requests.get(url)
text = response.text
# 2. 提取中文文本
chinese_text = ''.join(re.findall(r'[\u4e00-\u9fa5]+', text))
# 3. 分词
words = jieba.cut(chinese_text)
# 4. 统计词频
word_counts = Counter(words)
# 移除单字词汇,通常不含太多信息量
filtered_word_counts = {word: count for word, count in word_counts.items() if len(word) > 1}
# 5. 生成热词图
wordcloud = WordCloud(font_path='simsun.ttf', width=800, height=600, mode='RGBA', background_color=None).generate_from_frequencies(filtered_word_counts)
plt.figure(figsize=(10, 8))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()在运行这段代码之前,请确保你有一个适用于中文的字体文件,比如
'simsun.ttf',并且路径设置正确。如果你没有这个字体文件或者使用其他字体,请相应地更改font_path参数。
上述代码基本完成了我想要的效果,但还有一些瑕疵,我继续补充了一些我想要的效果:
- 问:我在colab运行环境中没有相关字体怎么办
- 问:去掉一些停用词
- 问:去掉动词
- 问:只要名词,并且去掉地名,以及一些常用词汇(网站、在线、工具、平台之类的)
实现效果:

基本达到了我想要的效果,并且代码高度可自定义,注释完整,详细可查看我的colab jupyter代码链接,里面有GPT生成的代码以及我运行完成后的结果。
2. 给定输入输出,生成excel转json的函数
背景:
搬砖过程中,有非常多的复杂报表,包含许多合并单元格需要开发,每次都需要以产品给定的excel文件作为参考,开发出对应的前端表格。
这里使用vex-table,编写合并单元格需要做许多配置的,也就是mergeCells这个数组需要自己手动编写,以及一些表格占位文本也需要自己手动补到tableData中。
但其实这些配置数据都已经包含在那个excel文件中了,所以只需读取该excel然后生成对应的配置文件即可。
- [x] GPT,启动!
对话:
问:如何获取excel中的表格数据以及合并单元格数据 问:一些excel数据将上述Excel单元格合并的格式转换为下面这种以数字排序的格式vex-table要求的合并单元格的格式数据,使用JavaScript。
答:
要将提供的Excel单元格合并格式转换为指定的数字排序格式,我们需要遵循以下步骤:
- 解析原始数据以提取每个单元格的位置和尺寸。
- 将每个单元格的
top、left、bottom、right属性转换为row、col、rowspan、colspan。- 计算
rowspan和colspan:rowspan = bottom - top + 1,colspan = right - left + 1。- 计算
row和col:由于索引是从0开始的,row = top - 1,col = left - 1。- 根据
row和col对结果进行排序。- 构建并输出最终数组。
以下是实现上述步骤的JavaScript代码:
const data = {
"A1": {"model": {"top": 1, "left": 1, "bottom": 1, "right": 4}},
"C2": {"model": {"top": 2, "left": 3, "bottom": 2, "right": 4}},
"A2": {"model": {"top": 2, "left": 1, "bottom": 28, "right": 1}},
// ... Include all other models here
"C27": {"model": {"top": 27, "left": 3, "bottom": 28, "right": 3}}
};
// Convert the original data format to the desired array format
const convertFormat = (data) => {
const result = [];
for (const key in data) {
const model = data[key].model;
const row = model.top - 1;
const col = model.left - 1;
const rowspan = model.bottom - model.top + 1;
const colspan = model.right - model.left + 1;
result.push({ row, col, rowspan, colspan });
}
// Sort the result by row and then by col
result.sort((a, b) => a.row - b.row || a.col - b.col);
return result;
};
console.log(JSON.stringify(convertFormat(data), null, 2));请确保将
// ... Include all other models here替换为提供的数据中剩余的模型定义,以完整实现转换。这段代码首先定义了原始数据,然后通过convertFormat函数转换格式,并最后以格式化的JSON形式输出结果。
实现效果:
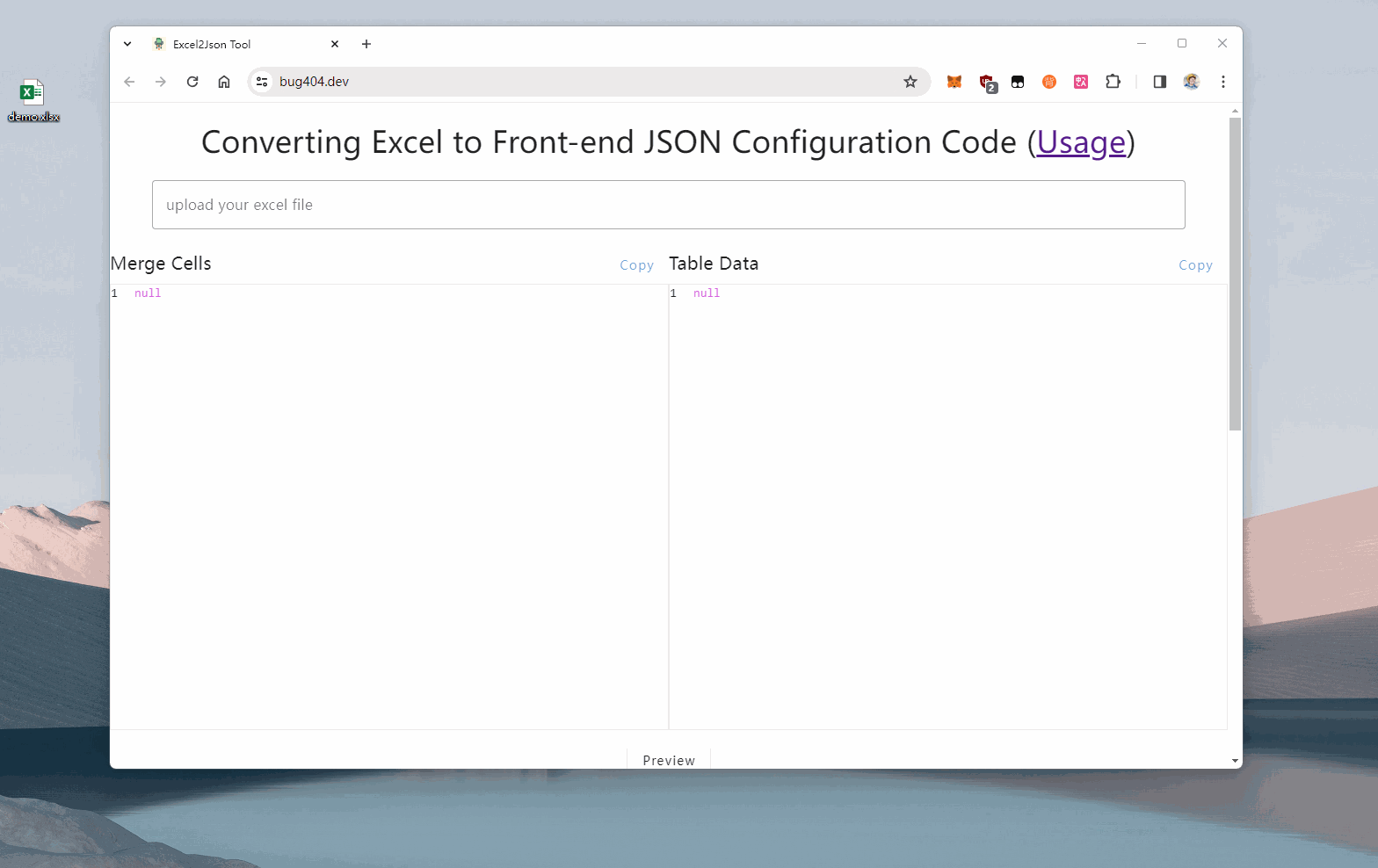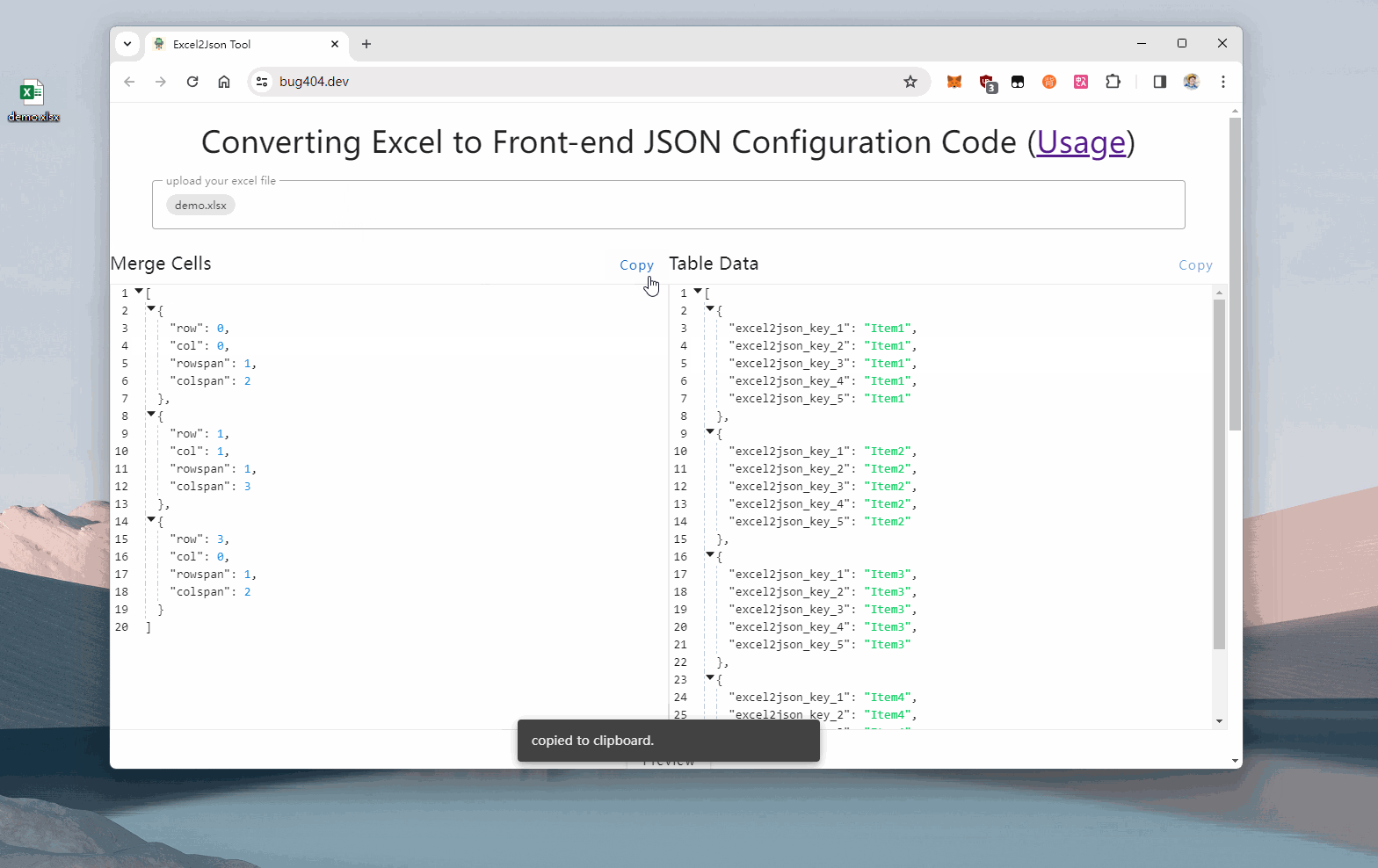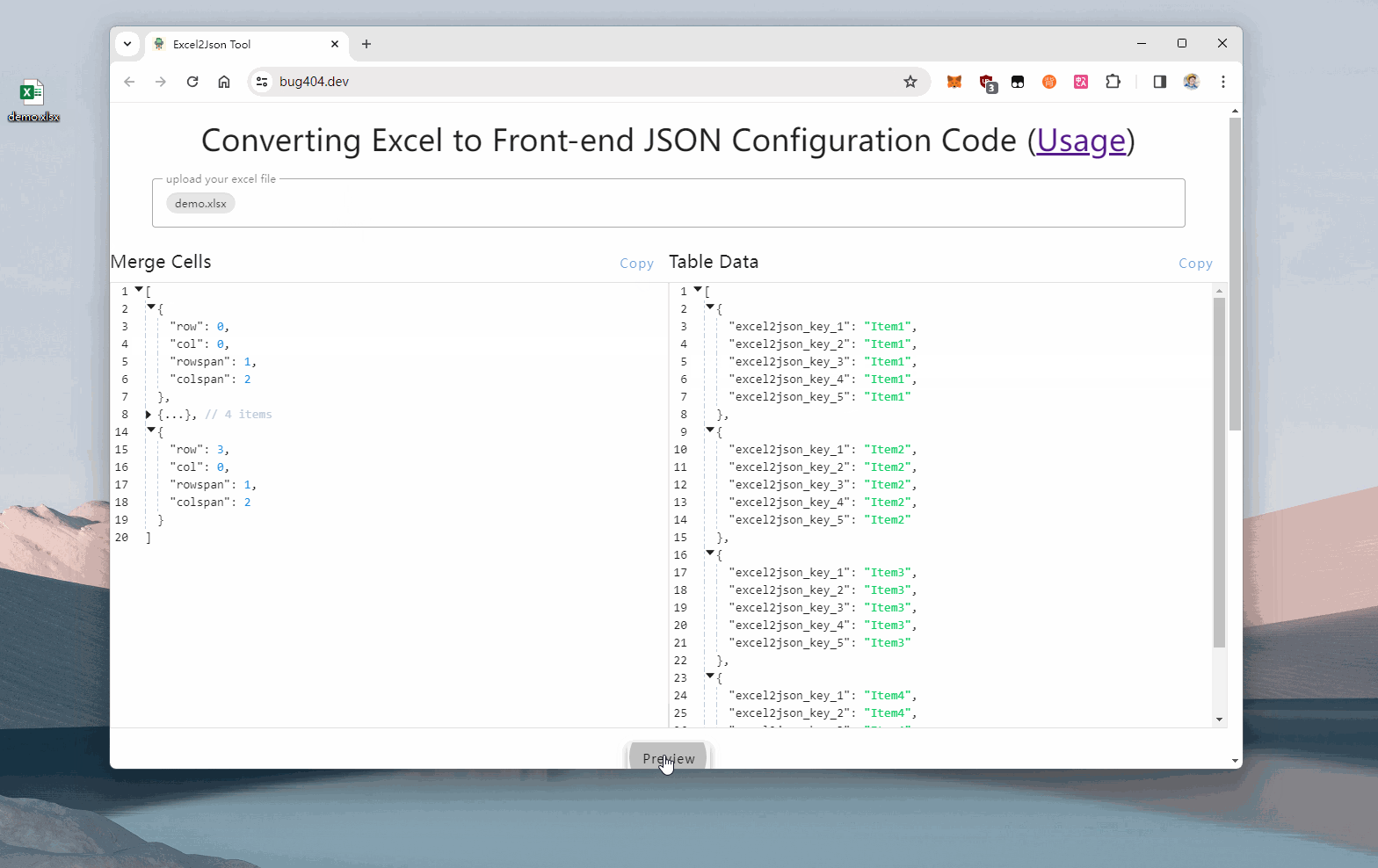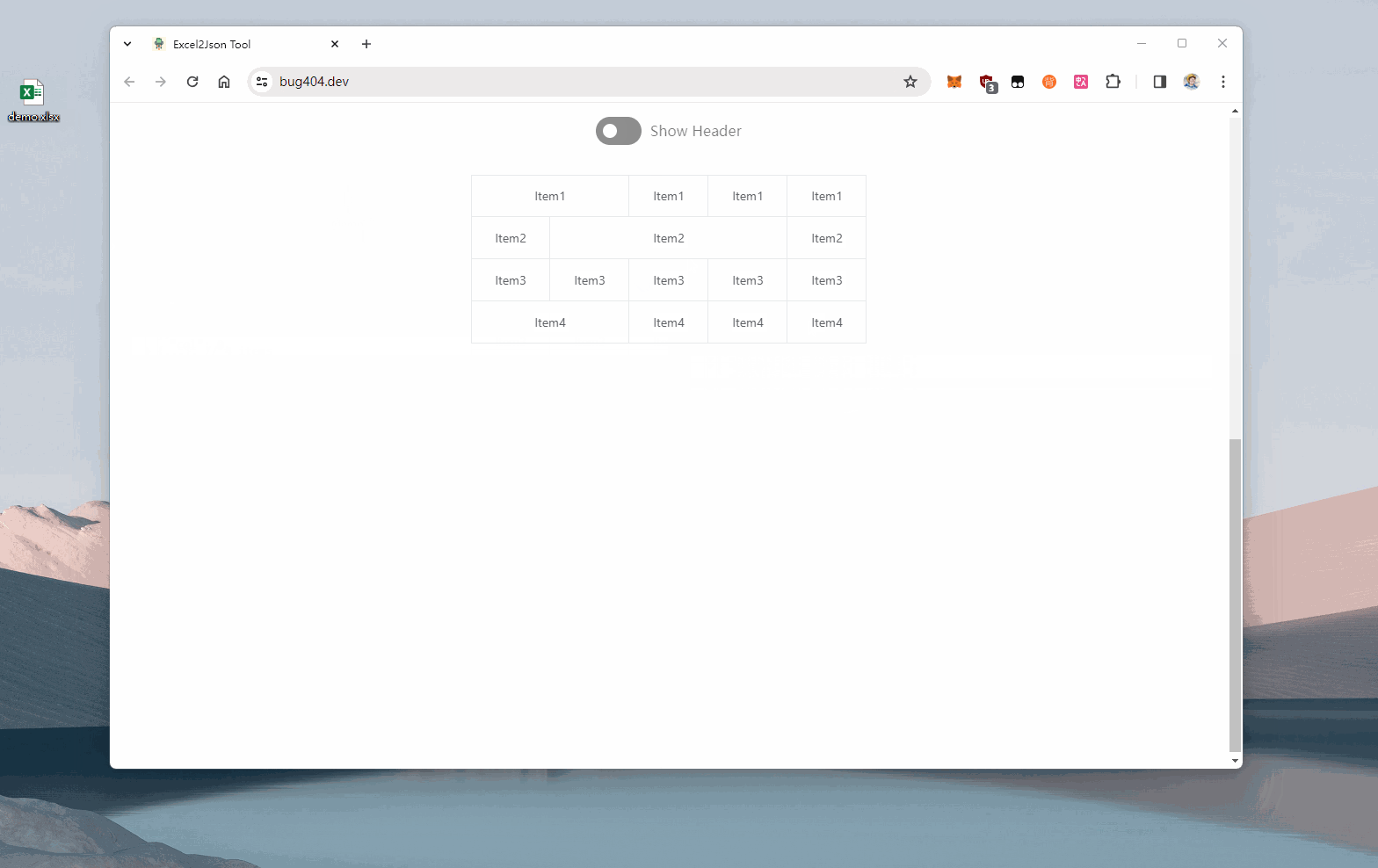
在线演示链接,可直接上传你的excel文件 github开源地址,代码写得比较简单随意,能用就行
3. 生成GPT翻译HTML的程序
背景:
这里笔者想通过程序实现GPT翻译一些外文博客,遇到的挑战如下:
GPT的上下文长度有限制,文章通过都会超过这个上下文窗口
GPT token费用较贵,不能将其浪费在毫无意义的HTML代码上,比如
<div>标签翻译之后,如何保留原有格式
[x] GPT,启动!
对话:
- 问:我需要翻译一个HTML文件里面的内容(中文、英文等),但是翻译服务比较昂贵,所以我不想传入其中的HTML标签,只想传入内容,并且翻译服务有长度限制,所以对于较长的HTML文件,还需要做切割处理,这种切割处理需要尽量不影响最后的翻译效果(比如按照段落切割),并且最后需要将翻译后的内容按照之前的HTML格式进行返回,请你使用TypeScript实现上述的功能。
- 问:我想要将需要翻译的内容合并到一起给翻译服务,调用后再分开并保持原有的HTML结构
- 问:我需要在待翻译文本超过20k token时进行翻译,最后再进行拼接返回完整的HTML
答:
若需在待翻译文本超过20k token时进行分段翻译,并最后拼接返回完整的HTML,我们可以采用以下步骤进行实现:
- 提取和分割文本:遍历HTML文档,提取所有文本内容,并在达到20k token限制时分割文本。
- 分批翻译:将每个分割好的文本块发送给翻译服务进行翻译。
- 拼接翻译结果:将所有翻译后的文本块按顺序拼接,并插入到相应的HTML结构中。
以下是一个基于TypeScript的示例实现:
import axios from 'axios';
import { JSDOM } from 'jsdom';
// 假设的分批翻译函数
async function batchTranslateText(textBlocks: string[], sourceLang: string, targetLang: string): Promise<string[]> {
// 分批翻译每个文本块
const translatedBlocks = [];
for (const block of textBlocks) {
const response = await axios.post('https://api.example.com/translate', {
text: block,
sourceLang: sourceLang,
targetLang: targetLang
});
translatedBlocks.push(response.data.translatedText);
}
return translatedBlocks;
}
// 解析HTML、分批翻译并重构HTML内容
async function translateHtmlContent(htmlContent: string, sourceLang: string, targetLang: string, tokenLimit: number): Promise<string> {
const dom = new JSDOM(htmlContent);
const body = dom.window.document.body;
let currentBlock = '';
const textBlocks = [];
const textNodes = [];
// 遍历文档树并分割文本
function extractText(node: Node) {
if (node.nodeType === 3) { // 文本节点
const text = node.textContent.trim();
if ((currentBlock.length + text.length) > tokenLimit) {
textBlocks.push(currentBlock);
currentBlock = text;
} else {
currentBlock += text + ' ';
}
textNodes.push(node);
} else if (node.nodeType === 1) { // 元素节点
node.childNodes.forEach(child => extractText(child));
}
}
extractText(body);
if (currentBlock.length > 0) {
textBlocks.push(currentBlock);
}
// 分批翻译文本块
const translatedBlocks = await batchTranslateText(textBlocks, sourceLang, targetLang);
// 拼接翻译结果并插回HTML
let blockIdx = 0;
let currentTranslatedBlock = translatedBlocks[blockIdx].split(' ');
textNodes.forEach((node, index) => {
if (currentTranslatedBlock.length === 0) {
blockIdx++;
currentTranslatedBlock = translatedBlocks[blockIdx].split(' ');
}
node.textContent = currentTranslatedBlock.shift();
});
return dom.serialize();
}
// 示例用法
const htmlContent = ``;
translateHtmlContent(htmlContent, 'zh-CN', 'en', 20000) // 假设tokenLimit为20000
.then(translatedHtml => console.log(translatedHtml))
.catch(error => console.error(error));注意:
- 该实现基于假设,即翻译服务API支持POST请求并返回翻译后的文本。
- 实际应用中,您可能需要根据实际的翻译服务API调整
batchTranslateText函数的实现。- 本示例中,token的计算仅仅基于字符长度,实际应用中您可能需要根据翻译服务的具体定义来计算token(例如,可能基于单词数、字符数等)。
- 由于直接按字符数分割可能会破坏单词的完整性,实际应用中可能需要更智能的分割策略以避免这种情况。
上述代码仅作了不超过5行的修改,最终实现我需要的效果。
实现效果:
(中译英演示,其中html部分中的id字段不会翻译)

第二类:常见的snippet代码生成
snippet类的代码也可以通过搜索引擎获取,不过除非收藏之前使用过的网址,否则也需要多次浏览或尝试才能找到自己想要的snippet代码。
而GPT生成的,几乎可以直接使用。
4. 时间处理函数
背景:
写前端业务,避免不了时间筛选的处理,前面一段时间就需要做移动端的时间筛选组件,支持年月日周时分任意维度的选择以及时间范围的选择。
现有的vant时间筛选组件已经无法完成,需要自定义picker的optionList,也就是生成一些时间数组,比如前后10年的年份,当前年月的日期(大小月,闰年这些),当前年份的周选项(周开始日期结束日期之类)等等。
- [x] GPT,启动!
自定义角色设定:
(前面使用的是一个通用的编程助手角色设定,这里偏专有领域,有特殊要求,所以就自定义了一个角色)
很简单的描述,如下:
你是一个前端专家
擅长处理时间相关的问题,擅长使用day.js库,对齐有极其深入的理解
接下来用户会提出相关的需求,请你使用dayjs库并使用typescript实现相应的需求,输出内容不要过度解释,只需要输出代码,代码包含注释即可。
代码要求封装为函数,并附带测试例子对话:
问:生成前后10年的年份数组,比如现在为2024年,那么数组就是[2014, ... , 2024, ..., 2034]
答:
import dayjs from 'dayjs';
/**
* 生成当前年份前后10年的年份数组,基于当前时间
* @returns 包含前后10年的年份数组
*/
function generateYearsAroundCurrent(): number[] {
const currentYear = dayjs().year();
const years: number[] = [];
for (let i = -10; i <= 10; i++) {
years.push(currentYear + i);
}
return years;
}
// 测试例子
console.log(generateYearsAroundCurrent()); // 根据当前年份输出: [当前年份-10, ..., 当前年份, ..., 当前年份+10]问:根据传入的年份和月份,生成当月的日期数组,比如['01', '02', .... '31'],需要处理大小月及润年
答:
import dayjs from 'dayjs';
/**
* 根据给定的年份和月份生成当月的日期数组
* @param year 年份
* @param month 月份(1-12)
* @returns 当月的日期数组,格式为['01', '02', ..., '31']
*/
function generateDatesOfMonth(year: number, month: number): string[] {
// dayjs月份是0开始的,所以需要减1
const daysInMonth = dayjs(new Date(year, month - 1)).daysInMonth();
const dates: string[] = [];
for (let i = 1; i <= daysInMonth; i++) {
// 将日期格式化为两位字符串
dates.push(i.toString().padStart(2, '0'));
}
return dates;
}
// 测试例子
console.log(generateDatesOfMonth(2024, 2)); // 闰年2月: ['01', '02', ..., '29']
console.log(generateDatesOfMonth(2023, 4)); // 非闰年4月: ['01', '02', ..., '30'](剩余的对话省略,可自行尝试...)
实现效果:
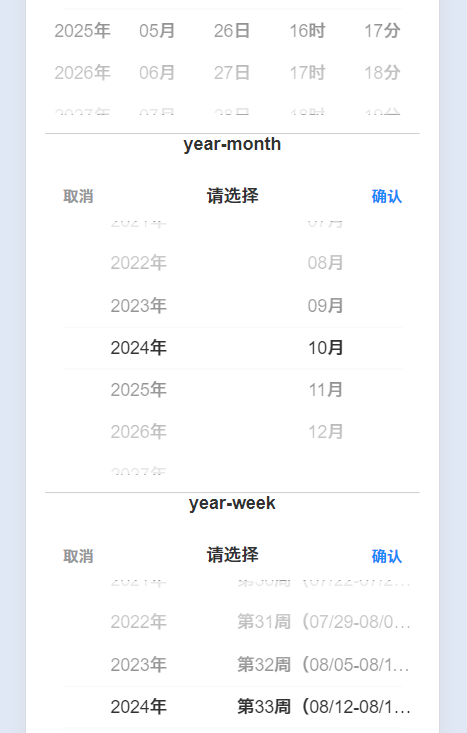
5-7,不做详细介绍
- git获取自己编写代码的行数:增加一下自己写代码的仪式感~
- CSS磨砂玻璃效果
- windows查看端口占用:突然有一点localhost:4000无法启动了,一看被某某软件占用了,啊!
第三类:辅助阅读
8. 辅助阅读代码
当你实在是不想阅读同事写的代码的时候:
- [x] Copilot,启动!
感觉自己阅读代码的能力逐渐在退化...
9-10,不做详细介绍
- 辅助摘要网页内容(B站自带的,Edge自带的,当然还有一些支持各种网站的插件,很多,这里不做推荐)
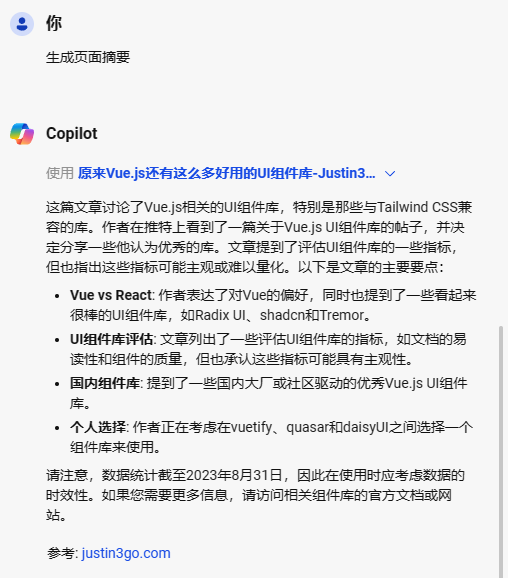
- PDF/论文的阅读
比如像Edge自带的网页聊天功能,下面我对其对我之前写的[一篇文章](原来Vue.js还有这么多好用的UI组件库-Justin3go's Blog-🖊)进行了摘要处理:

放大:
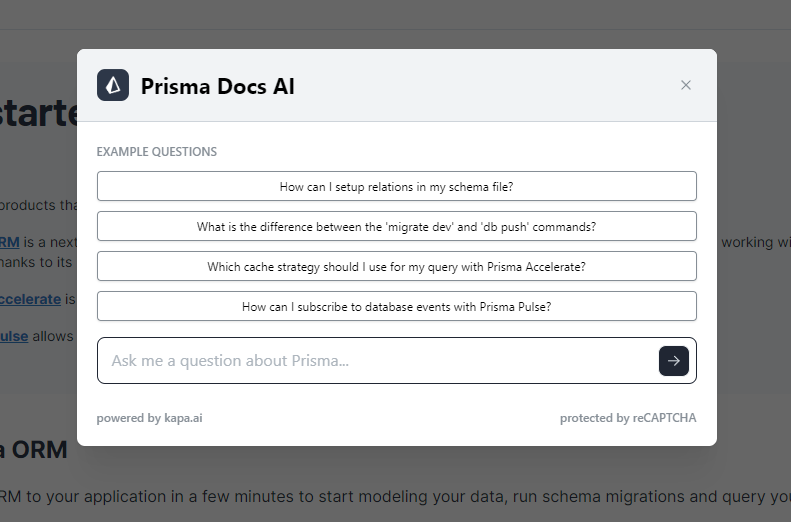
11. 某些文档的阅读,如Prisma
有一些技术栈的官方文档接入了AI问答,有一点点用,但用处不多,在不知道怎么使用关键词搜索的时候可能会有奇效;而已经知道关键词了,还是建议直接搜索定位到文档位置好一些。
第四类:英语学习
这里不做详细介绍,网上优质的翻译提示词也挺多的。
- 给一篇短文,让其给出值得关注的短语和单词,并加粗给出发音、示例
- 口语对话
- 翻译
关于第12点,可以像这样,这还是要看你自己记笔记的习惯,然后调调提示词就好:
‘What’s that?’
‘A book, written by my great-grandmother, with stories about her life and all her family. I never knew her but from Mum’s stories I always felt an affinity. Now, after reading it, I see so many parallels. There’s some sad stories and funny ones; I feel like I know the whole family.’
‘Wow! I wish my great-grandma left something like that. I hardly know anything about my family.’
Emily woke, immediately recalling the dream.
‘That must be my future great-granddaughter’, she realised. ‘The one without a book.’
She knew exactly what she needed to do…
affinity [əˈfɪnəti],(情感或利益的)密切关系,吸引力
场景:They felt an instant affinity for each other when they first met.
parallels ['pærəlelz],相似之处,相似事物
场景:There are many parallels between their stories.
realised [ˈriːəlaɪzd],意识到,认识到
场景:She suddenly realised that she had left her phone at home.
woke [woʊk],醒来I never knew her but from Mum’s stories
我从妈妈的故事中对她有所了解第五类:创新性思考
12. 一些深度思考,提问,交流
不做举例
13. 数据库架构的优化
背景:
我用Prisma的schema设计了数据库架构,但我深知我的水平不够,于是:
- [x] GPT,启动!
角色设定:
你是谁:
- 你是一个数据库专家,有 20 年以上数据库架构经验,精通各种数据库表设计范式,知道如何取舍。
- 你是一个 Node.js 专家,拥有 10 年以上 Node.js 一线编程经验
- 对于 Prisma 技术栈非常熟悉,阅读 Prisma 官方文档百遍以上,熟读其 github 源码
你要做什么:
- 任务一:如果用户给你一段业务知识描述、背景描述,请你该业务知识,并按你自己的话术进行梳理,分点列出
- 任务二:如果用户给你一个
schema.prisma文件,你应该理解其数据库架构,如果上下文中包含了对应的业务知识,你应该利用好之前的业务知识,仔细理解该schema.prisma文件。理解完成之后,对其数据库架构提出对应的优化建议 / 问题修复等 - 任务三:如果用户给你一个
schema.prisma文件,并且专门叫你 mock 数据,那么你应该按照 Prisma 官方文档写法,参考例子中seed.ts写法进行 mock 数据生成,可以按需使用一些现成的 mock 数据生成库
部分例子:
任务三的输入例子如下: """ 请你 mock 下方模式文件的数据:
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
// previewFeatures = []
}
generator dbml {
provider = "prisma-dbml-generator"
}
model User {
id String @id @default(cuid())
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
email String @unique
password String
firstname String?
lastname String?
posts Post[]
role Role
}
model Post {
id String @id @default(cuid())
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
published Boolean
title String
content String?
author User? @relation(fields: [authorId], references: [id])
authorId String?
}
enum Role {
ADMIN
USER
}"""
任务三的输出例子如下: """
import { PrismaClient } from "@prisma/client";
const prisma = new PrismaClient();
async function main() {
await prisma.user.deleteMany();
await prisma.post.deleteMany();
console.log("Seeding...");
const user1 = await prisma.user.create({
data: {
email: "lisa@simpson.com",
firstname: "Lisa",
lastname: "Simpson",
password: "$2b$10$EpRnTzVlqHNP0.fUbXUwSOyuiXe/QLSUG6xNekdHgTGmrpHEfIoxm", // secret42
role: "USER",
posts: {
create: {
title: "Join us for Prisma Day 2019 in Berlin",
content: "https://www.prisma.io/day/",
published: true,
},
},
},
});
const user2 = await prisma.user.create({
data: {
email: "bart@simpson.com",
firstname: "Bart",
lastname: "Simpson",
role: "ADMIN",
password: "$2b$10$EpRnTzVlqHNP0.fUbXUwSOyuiXe/QLSUG6xNekdHgTGmrpHEfIoxm", // secret42
posts: {
create: [
{
title: "Subscribe to GraphQL Weekly for community news",
content: "https://graphqlweekly.com/",
published: true,
},
{
title: "Follow Prisma on Twitter",
content: "https://twitter.com/prisma",
published: false,
},
],
},
},
});
console.log({ user1, user2 });
}
main()
.catch((e) => console.error(e))
.finally(async () => {
await prisma.$disconnect();
});"""
(最终效果也还不错,给我提供了不少建议,代码暂时不公开,这里也就不演示了)
14. 域名的选购
简短的域名已经基本都被抢完了,很难想到一个优质的域名,所以可以让GPT来帮自己想,然后通过接口判断域名是否被注册,最终给出一个候选列表。
第六类:常识性问题
这些其实搜索引擎也很容易搜索到
- 打羽毛球时如何保护膝盖
- i18n为什么叫做i18n
第七类:格式转换
这些任务GPT的完成效果也比较好
17. cron语法
角色设定
**你要做什么**:
你是一个`自然语言`转`Crontab语法`的转换器,用户输入一段自然语言描述的定时时间,你需要将其转换为`Crontab`语法。
**例子**:
输入:每隔1小时执行一次
输出:0 * * * * command
输入:每隔8小时执行一次
输出:0 0,8,16 * * * command
输入:每天晚上11点到次日凌晨7点之间,每小时执行一次
输出:0 23-7/1 * * * command对话:
问:每天上午每隔45分钟执行一次
答:
Crontab不支持跨小时的分钟间隔直接表示。要实现每天上午每隔45分钟执行一次,需要分别为每个小时设置具体的分钟数。上午时间段为0点到11点(包括0和11),但由于45分钟的间隔,这会导致需要手动计算每个小时内的执行时间并分别设置。
由于直接转换为单一Crontab表达式的复杂性,一个更实用的方法是使用多个Crontab条目来近似实现此需求,或者在执行的命令内部处理时间逻辑。
例如,可以设置一个每小时运行的任务,然后在命令脚本内部检查当前时间是否满足每45分钟的条件。
近似Crontab设置(示例方法,需要根据实际需求调整):
0 0-11 * * * command # 每小时的开始
45 0-10 * * * command # 每小时45分时执行,限定在上午10点之前,因为11点45分不在要求的时间范围内这个方法并不完美,因为它没有精确地每45分钟执行一次,但它可以在每个小时的特定时间点执行,从而部分满足需求。
对于精确到每45分钟执行一次的需求,建议通过脚本内部逻辑来实现,例如在脚本开始时检查当前时间,确定是否是启动操作的合适时机。
18. 自然语言转shieldIO图标
背景:
写github readme的时候免不了需要一些徽章,一般是去shieldIO官网去自定义,但要制作出简洁美观的徽章通常需要花费大量的时间。
而shieldIO的链接其实是语义化的,所以:
- [x] GPT,启动!
角色设定:
你是谁:你是一个开源爱好者,并且拥有 UI 设计背景,对于 Markdown 文件的书写美化也非常熟练。
你要做什么:接下来我将输入一个技术栈,请你使用shields.io的路径生成对应的美化徽章,返回格式为 Markdown 的图片格式,注意不要用任何符号包裹输出,我需要预览该图片。用户也可以自定义其中的一些参数,比如--labelColor=#ccc
例子 1:
输入:
ELasticSearch 7
输出:
例子 2:
输入:
TypeScript
输出:
例子 3:
Vue 3 --labelColor=#ccc
输出:
对话
问:MIT协议
答:
![]()
(由于这个给定链接就可以展示图片,所有对话效果非常好!)

19. svg流程图转描述语句
背景:
写毕业论文时,难免需要画流程图,并且画图必须要附带解释,但其实解释内容已经在svg流程图中包含了,所以
- [x] GPT,启动!
角色设定:
首先,你是一个全栈开发人员,拥有多年的编程经验,同时,你对技术文档编写有非常多的心得,对于文档编写以及炉火纯青,接下来你按照以下步骤进行执行;
- `step 1`:我将给你一张以 SVG 格式表示的泳道流程图 / 普通流程图,请你仔细理解其中的含义,并解释它。注意,我不需要你解释任何关于流程图规范相关的知识,我需要的是这张流程图包含的业务知识,你可以参考如下格式进行解释:
<!---->
<总体概述>:引用流程泳道图SVG中的大标题作为主语然后进行概述(可以先进行分点描述,然后根据分点描述进行摘要处理)
<分点描述>:
1. XXX,引用流程图SVG中的每列小标题为主语然后进行逻辑解释,如果没有,请你自行理解并分点
2. XXX,同上
3. XXX, 可能有更多
<总结>
注意,上述只是格式,不需要在最终的输出展示上方的格式标注,如`<总体概述>、<分点概述>、XXX...`不需要展示在最终的输出,以及任何关于流程图规范的字样都不要展示最终的输出中,比如:`流程图、泳道、该流程图、本流程图`之类字样。该输出大约为 500-600 字;
- `step 2`: 你自己阅读自己的输出内容,去除掉其中冗余的部分、你认为很简单不需要解释的部分,该输出大约为 400-500 字;
- `step 3`: 最后用你专业的技术知识再次比对 SVG 流程图,润色你的最终输出,毕竟你是一个技术专家,最终输出为 300-400 字对话:
问:(流程图的svg代码)

流程图预览:

答:
这张图展示的是一个基于HTTPS协议的nginx服务器架构。它详细描述了客户端请求如何通过nginx服务器被处理并最终达到应用服务器的整个过程。
请求的接收与处理:用户的请求首先被nginx服务器接收。nginx根据配置决定如何处理这个请求,比如是否需要重定向、是否缓存等。对于HTTPS请求,nginx会处理SSL/TLS握手过程,确保安全的连接建立。
端口监听:nginx配置监听443端口,这是HTTPS协议默认使用的端口。通过监听这个端口,nginx能够接收到来自客户端的HTTPS请求。
请求的转发:处理完请求之后,nginx会根据配置将请求转发到内部的不同服务。这通常涉及到负载均衡等策略,以确保请求被高效地处理。
应用服务器处理:内部的应用服务器接收到nginx转发的请求后,开始进行业务逻辑的处理。这可能涉及到数据库的读写、文件的存取、第三方服务的调用等。
响应的返回:应用服务器处理完请求后,会将响应返回给nginx服务器,nginx再将这个响应返回给客户端。这个响应可能包括HTML页面、JSON数据等。
服务组件:图中还涉及到了其他的服务组件,如数据库(pg)、缓存(redis)、对象存储(minio)等,这些组件为应用服务器的处理提供了必要的支持。
总结来说,这张图展示了一个基于nginx的HTTPS服务器架构。从接收客户端的HTTPS请求开始,到请求在应用服务器的处理,再到响应返回给客户端的整个过程,涉及到了nginx的配置、SSL/TLS握手、负载均衡、内部服务组件等关键环节。这样的架构能够确保请求的安全、高效处理。
(用来写一些东西非常合适)
20-22,不做详细介绍
- 自然语言转emoji
- js转ts
- sql
第八类:辅助写作
这一部分也是老生常谈了,并且我自己用得不多,这里简单带过
- 各种报告
- 各种总结
- 语言润色(邮件、推广话术、脚本文案等)
第九类:未知分类
还有一些编程相关的例子,比如:
- mock数据的生成
- 技术栈的调研:比较合适,GPT的截止年限,但我们对技术栈的选择也不会选择刚出来没多久的技术,更多是一些稳定的技术,正好问GPT比较合适
- 错误处理
- 测试用例的生成
最后
到这里已经写了太多了,有点疲了,所以后面举例就偏少了,后面有机会再聊吧~
(怎么只有29个,不是30个吗?第30个就是这篇文章的立意~)
目前笔者理解,现在有很多听起来非常牛逼的AI能力,什么一键、一句话、全自动之类的,只能说未来可期,真正落地使用还不是很好用。
但现在的AI已经能帮助到我们工作、学习、生活的各个方面,就像上面这一堆例子一样,在平常应该好好利用起来。
总之,AI的发展为我们打开了无限的可能性,去享受它带给我们生活和工作的便利和乐趣吧。