SQL
基本介绍
特点:
- 一体化
- 高度非过程化
- 语言简洁
- 多种使用方式
SQL 功能:
| SQL 功能 | 对应命令 |
|---|---|
| 数据定义 | CREATE、DROP、ALTER |
| 数据查询 | SELECT |
| 数据操纵 | INSERT、UPDATE、DELETE |
| 数据控制 | GRANT、REMOVE、DENY |
数据库定义
- 数据库中的所有数据、对象、事物日志均以文件的形式保存
- 根据作用不同,这些文件可分为:
- 数据文件:
- 主数据文件用于存储数据库的系统表,文件扩展名为 mdf
- 次数据文件用于存储主数据文件中未存储的数据和数据对象,文件扩展名为 ndf
- 事务日志文件:用于记录对数据库的操作情况,文件扩展名为 ldf
- 数据文件:
相关操作CREATE DATABASE
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name
[create_option] ...
create_option: [DEFAULT] {
CHARACTER SET [=] charset_name
| COLLATE [=] collation_name
| ENCRYPTION [=] {'Y' | 'N'}
}例:创建一个只设置名称的数据库,数据库名称为 dbtest
CREATE DATABASE dbtest数据库维护
相关操作ALTER DATABASE
ALTER {DATABASE | SCHEMA} [db_name]
alter_option ...
alter_option: {
[DEFAULT] CHARACTER SET [=] charset_name
| [DEFAULT] COLLATE [=] collation_name
| [DEFAULT] ENCRYPTION [=] {'Y' | 'N'}
| READ ONLY [=] {DEFAULT | 0 | 1}
}例 1:修改数据库 sjkDB 中数据文件的初始大小,将其初始化改为 9MB,最大为 120MB
ALTER DATABASE sjkDB
MODIFY FILE
(
NAME=sjkDB_data,
SIZE=9,
MAXSUZE=120
)例 2:为数据库 sjkDB 添加新的日志文件,逻辑名称为 sjkDBlog1,存储路径为E:\teaching,物理文件名为 sjkDBlog1.ldf,初始大小为 3MB,增量 1MB,最大 20MB
ALTER DATABASE sjkDB
ADD LOG FILE
(
NAME=sjkDBlog1,
FILENAME='E:\teaching\sjkDBlog1.ldf',
SIZE=3,
MAXSIZE=20,
FILEGROWTH=1
)例 3:将数据库 test 更名为 test_1
ALTER DATABASE test
modify name=test_1例 4:使用DROP DATABASE语句删除数据库dbtest
DROP DATABASE dbtest表的定义
相关操作CREATE TABLE
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] tbl_name
(create_definition,...)
[table_options]
[partition_options]
[略]例 1:建立“学生”表 Student。学号是主码,姓名取值唯一。
CREATE TABLE Student
(
SNO CHAR(9) PRIMARY, /* 列级完整性约束条件,Sno 是主码 */
SName CHAR(20) UNIQUE, /* Sname 取唯一值 */
Ssex CHAR(2),
Sage INT,
Sdept CHAR(20),
)注:我们还可以通过constraint命名约束名
表的维护
修改表
ALERT TABLE <table_name>
[ADD <col_name><data_type>[constaint]] /* 增加列 */
[DROP COLUMN <column_name>] /* 删除列 */
[ALTER OLUMN <column_name><data_type>[constaint]] /* 修改列 */删除表
DROP TABLE <表名> [RESTRICT|CASCADE]- RESTRICT:删除表是有限制的
- CASCADE:删除该表没有限制
完整性约束
完整性约束的作用范围可以分为:
- 列级约束:某列的约束;比如
年龄 > 0 - 元组约束:元组中各字段的约束;比如
结束日期 >= 开始日期 - 关系约束:关系之间联系的约束;比如:供货商表里没有的商家不能提供商品
相关操作constraint
例 1:为员工表添加主码
ALTER TABLE 员工表
ADD CONSTRAINT pk_yg PRIMARY KEY(员工编码) /* pk_yg 约束名 */例 2:为薪资表的薪级名称添加 UNIQUE 约束
ALTER TABLE 薪资表
ADD CONSTRAINT U_xinzname UNIQUE(薪级名称) /* U_xinzname 约束名 */例 3:薪资表的基础薪资定义 DEFAULT 约束
ALTER TABLE 薪资表
ADD CONSTRAINT DF_jichu DEFAULT 2000 FOR 基础薪资例 4:薪资表的实发薪资列添加 CHECK 约束,使其值小于应发薪资列
ALTER TABLE 薪资表
WITH NOCHECK /* 表示该约束对旧数据不作用,对新数据约束 */
ADD CONSTRAINT CK_shifa CHECK (实发薪资<应发薪资)参照完整性约束:
- 参照完整性约束属于表间规则,是指一个表中的主码与另一个表外码之间的关系,保证两个表的相容性
- 若主码与外码来自同一个表,则称自参照完整性
- 只要外码值存在,主码表中的数据就不能任意修改与删除,除非设置了级联删除与修改
相关操作FOREIGN KEY
例 5:员工表的薪资级别编码列添加外码约束,引用薪资表的薪级编号
ALTER TABLE 员工表
ADD CONSTRAINT FK_xinji
FOREIGN KEY(薪级编号) REFERENCES 薪资表(薪级编号)- 对参照表(外码表)添加元组或修改外码属性列时,都有可能破坏完整性约束
- 对被参照表(主码表)删除元组或修改主码属性列时,也会破坏参考完整性约束
处理这些破坏性约束的操作,三种方式
- 拒绝
- 级联删除(修改)
- 设置为空值
例 6:员工表的薪级编码列添加外码约束,引用薪资表的薪级编号,定义该完整性约束可以级联删除或修改。
ALTER TABLE 员工表
ADD CONSTRAINT FK_xinji
FOREIGN KEY (薪级编号) REFERENCES 薪资表(薪级编号)
ON DELETE CASCADE /* 级联删除 */
ON UPDATE CASCADE /* 级联修改 */上述的三种约束,也可以在表定义的时候一并进行定义添加CREATE TABLE
完整性约束删除:
ALTER TABLE <table_name>
[DROP <constraint_name>] /* 删除约束 */索引
基本介绍
- 索引是用来提高查询速度的重要手段
- 索引与图书目录类似,查找书本内容,可以在目录中直接查看该内容在书本中的页数,而不需要查阅整本书。
- 索引表本身会占用用户数据库空间,在对数据进行插入、更新、删除时,维护索引也会增加时间成本
索引可以分为:
- 聚集索引:是指数据库表中的数据按照索引关键字顺序存储,表设置主码后,就建立一个主码上的聚集索引。因为一个表的数据只能按照一种物理顺序存储,所以一个表上只能有一个聚集索引
- 非聚集索引:则不要求数据表的数据按照索引关键字书顺序排序,表的物理顺序与索引关键字顺序不同。一个表上可以有多个非聚集索引
- 唯一索引:索引关键字不允许重复。如果在 Student 表"SName"字段上建立了唯一索引,则 SName 的值不允许重复
注:聚集索引与非聚集索引都可以是唯一索引
索引的定义
相关操作CREATE INDEX
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
[index_type]
ON tbl_name (key_part,...)
[index_option]
[algorithm_option | lock_option] ...
key_part: {col_name [(length)] | (expr)} [ASC | DESC]
index_option: {
KEY_BLOCK_SIZE [=] value
| index_type
| WITH PARSER parser_name
| COMMENT 'string'
| {VISIBLE | INVISIBLE}
| ENGINE_ATTRIBUTE [=] 'string'
| SECONDARY_ENGINE_ATTRIBUTE [=] 'string'
}
index_type:
USING {BTREE | HASH}
algorithm_option:
ALGORITHM [=] {DEFAULT | INPLACE | COPY}
lock_option:
LOCK [=] {DEFAULT | NONE | SHARED | EXCLUSIVE}例 1:为“薪资表”中的“薪资名称”建立唯一的非聚集升序索引
CREATE UNIQUE NONCLUSTERED
INDEX index_name1 ON 薪资表(薪级名称 ASC)例 2:按应发薪资升序和实发薪资降序建立唯一索引
CREATE
UNIQUE
INDEX index_name2
ON 薪资表(应发薪资 ASC,实发薪资 DESC)查看索引
如果我们要查看索引,可以使用系统存储过程Sp_helpindex查看所建立索引,比如查看薪资表索引语句为
Sp_helpindex 薪资表索引的维护
索引一经建立,就由数据库系统维护,无需用户参与
常见准则:
- 避免在经常更新的表上建立过多索引,如果建立聚集索引,应设置较短索引建长度
- 对经常用户查询中的谓词和连接条件的列建立非聚集索引
- 在经常用作查询过滤的列上建立索引
- 在查询中经常进行
GROUP BY、 ORDER BY的列上建立索引 - 在不同值较少的列上不必要建立索引,如性别字段
- 对于经常存取的列避免建立索引
- 在经常存取的多个列上建立复合索引,但要注意复合索引的建立顺序要按照使用的频度来确定
- 考虑对计算列建立索引
删除索引:
DROP INDEX table_name.index_name
或者
DROP INDEX index_name ON table_name单表查询
SELECT 语句格式
SQL 使用 SELECT 语句一般格式:
SELECT [ALL|DISTINCT] <Target Column | Expression>[,<Target Column|Expression>]...
FROM <TABLE_name|VIEW_name> [,<TABLE_name|VIEW_name>...]
[WHERE <Conditional Expression>]
[GROUP BY <COLUMN_name> [, COLUMN_name...] HAVING <Condtional Expression>]
[ORDER BY <COLUMN_name> [ASC | DESC]];列操作
选择列即关系代数中的投影运算。SELECT 子句可以查询指定列、表达式。
查询指定列:
例 1:查询全体学生姓名、学号、专业
SELECT SName, SNO, Major FROM Student例 2:查询全体学生的详细信息
SELECT SNO, SName, BirthYear Ssex, college, Major, Weixin FROM Student
/* 使用表中列的顺序 */
SELECT * FROM Student查询表达式的值:
SELECT 子句中的表达式(Expression)可以是包含列的计算表达式,也可以是常量或函数。
例 3:查询全体学生的学号、姓名、年龄
SELECT SNO, SName, 2019-BirthYear FROM Student其中2019-Birthday是一个计算表达式,我们也可以用系统函数GETDATE()读取当前时间,再用YAER()读取年份:
SELECT SNO, SName, YEAR(GETDATE())-BirthYear FROM Student上述表达式的计算值记录在结果集中,但没有列名,显示为“无列名”,可以使用 AS 子句为其添加别名记录其语义
去掉重复列:
例 4:查询购买了商品的学生学号
SELECT SNO FROM SaleBill上述 SQL 语句查询出来的学生学号是有重复的。我们可以使用 DISTINCT 关键字,去掉重复数据。
SELECT DISTINCT SNO FROM SaleBill行操作
WHERE 子句:
我们可以使用WHERE子句对元组进行筛选
| 查询条件 | 谓词 |
|---|---|
| 比较 | =,>,<,>=,<=,!=,<>,!>,!<;NOT 上述比较符 |
| 确定范围 | BETWEEN AND,NOT BETWEEN AND |
| 确定集合 | IN,NOT IN |
| 字符匹配 | LIKE, NOT LIKE |
| 空值 | IS NULL, IS NOT NULL |
| 多重条件(逻辑运算) | AND,OR,NOT |
比较运算符:
例 1:查询管理信息系统专业学生名单
SELECT *
FROM Stuent
WHERE Major="MIS"例 2:查询年龄不大于 18 的学生名单
SELECT *
FROM Student
WHERE YEAR(GETDATE())-BirthYear !> 20确定范围:
例 3:查询现货存量在 2 到 10 之间的商品信息
SELECT * FROM Goods
WHERE Number BETWEEN 3 AND 10例 4:查询 2019 年生产的商品信息
SELECT * FROM GOODS
WHERE ProductTime BETWEEN "2019-1-1" AND "2019-12-31"例 5:查询年龄在 18-20 岁以外的学生信息
SELECT * FROM Student
WHERE YEAR(GETDATE())-BirthYear NOT BETWEEN 18 AND 20例 6:查询姓名在“李明”和“闵红”之间的学生信息
SELECT * FROM Student
WHERE SName BETWEEN "李明" AND "闵红"中文字符按字符拼音字母先后排序,如果拼音第一字母相同,则比较第二字母,以此类推
集合运算符:
IN用来查找属性值属于指定集合的元组,NOT IN的含义相反
例 7:查询商品编号为 GN0001、GN0002 的销售信息
SELECT * FROM SaleBill
WHERE GoodsNO IN ("GN0001",'GN0002')字符匹配:
在字符查询条件不确定时,可以使用 LIKE 运算符进行模糊匹配。LIKE 运算符通过匹配部分字符达到查询目的
[NOT] LIKE "<匹配串>" [ESCAPE "<转义字符>"]匹配串可以是完整的字符串,也可以是含有通配符的字符串,通配符包括:
%:(百分号)匹配任意长度字符_:(下划线)匹配任一字符[]:数据表列值匹配[]中任一字符成功,该LIKE运算符结果均为TRUE。如果[]中的字符连续的,可以使用-代表中间部分,比如[a-d][^]:表示不匹配[]中的任意字符,如[^a-d]
例 1:查询商品名称中包含“咖啡”的商品信息
SELECT * FROM Goods
WHERE GoodsName LIKE "%咖啡%"例 2:查询学生姓名第二个字为“民”的学生信息
SELECT * FROM Student
WHERE SName LIKE "_民%"例 3:商品编号最后一位不是 1、4、7 的商品信息
SELECT * FROM Goods
WHERE GoodsNO NOT LIKE "%[147]"
或者:
SELECT * FROM Goods
WHERE GoodsNO LIKE "%[^147]"如果查询的字符串含有通配符,为了与通配符区分开,需要使用 ESCAPE 关键字对通配符进行转义,告诉数据库系统该字符不是通配符,而是字符本身。
ESCAPE 关键字后面所跟的一个字符为转义字符,转义字符后所跟字符不再为通配符,而是代表其本来含义。
例 4:查找包含有5%的元组
WHERE column_name LIKE "%5a%%" ESCAPE "a"其中字符“a”即为转义字符,表明该转义字符后的“%”不是通配符,而是百分号本身。
例 5:查询包含[]元组
WHERE column_name LIKE "%![%!]%" ESCAPE "!"空值处理:
空值(null)在数据库中表示不确定值,即在字符集中没有确定值与之对应。未对某元组的某个列输入值,就会形成空值(null)
涉及空值的判断,不能用前述运算符,只能使用 IS 或 IS NOT 来判断
例 6:
SELECT * FROM Goods
WHERE SupplierNO IS NULL注:sql 中的 null 值是导致许多错误的罪魁祸首
多重条件查询:
- 使用运算符 AND 或 OR 可以连接多个查询条件
- 多个运算符的执行顺序是从左往右,AND 的运算级别高于 OR,用户也可以使用小括号改变优先级
例 7:查询 AC 专业的学生和 MIS 专业男生的信息
SELECT * FROM Student
WHERE Major="AC" OR Major="MIS" AND Ssex="男"
/* 这里会先判断 AND */
SELECT * FROM Student
WHERE (Major="AC" OR Major="MIS") AND Ssex="男"
/* 这里会先判断 OR */排序
可以按照ORDER BY子句指定升序(ASC)或降序(DESC)排列,默认升序。
例 1:查询学生信息,按照出生年升序排列
SELECT * FROM Student
ORDER BY BirthYearORDER BY子句也可以跟多个字段。先按第一个字段的顺序排列,如果第一个字段的排序结果相同,则按第二个字段顺序排列,以此类推
例 2:查询商品名称包含“咖啡”的商品的商品编号、商品名、现货存量和生产时间。按现货存量升序、生产日期降序排列
SELECT GoodsNO,GoodsName,Number,ProductTime FROM Goods
WHERE GoodsName LIKE "%咖啡%"
ORDER BY NUMBER ASC, ProductTime DESCORDER BY后也可以跟表达式、函数等
例 3:查询商品表的商品编号、商品名称、现货存量、生产日期、保质期剩余天数,按照保质期剩余天数升序排列。
SELECT GoodsNO,GoodsName,Number,ProductTime,
QGPeriod * 30 - DATEDIFF(day, ProductTime, GETDATE()) 保质期剩余天数 FROM Goods
ORDER BY QGPeriod * 30 - DATEDIFF(day, ProductTime, GETDATE())聚合函数
SQL 使用聚合函数提供了一些统计功能,常见聚合函数及功能如下:
| 聚合函数名及参数 | 功能 |
|---|---|
COUNT(*|<列名>) | 统计元组个数 |
COUNT([DISTINCT|ALL<列名>]) | 统计一列中值的个数 |
SUM([DISTINCT|ALL<列名>]) | 计算一列值的总和(此列必须为数值型) |
AVG([DISTINCT|ALL<列名>]) | 计算李磊值的平均值(此列必须为数值型) |
MAX([DISTINCT|ALL<列名>]) | 求一列中的最大值 |
MIN([DISTINCT|ALL<列名>]) | 求一列中的最小值 |
上述函数除了COUNT(*)外,其余函数均忽略 NULL 值
例 1:查询商品个数
SELECT COUNT(*) FROM Goods例 2:查询售出商品种类数
SELECT COUNT (DISTINCT GoodsNO) FROM SaleBill注:聚合函数计算时如果要忽略重复值,则要指定统计列为 DISTINCT
例 3:查询商品总的销售量
SELECT SUM(Number) 总销售量 FROM SaleBill例 4:统计销售表中的单次售出最多、最少和平均:
SELECT MAX(Number) 最大销售量, MIN(Number) 最小销售量, AVG(Number) 平均销售量 FROM SaleBill分组统计
分组就是将查询结果按照某一列或多列的值进行分组,值相同的分为一组。
对查询结果分组的目的是为了细化聚合函数的作用范围,没有分组聚合函数用于所有数据,分组后,聚合函数将作用于每组数据。
例 1:统计每个学生购买的商品种类数
SELECT SNO, COUNT(DISTINCT GoodsNO) AS 商品种类数
FROM SaleBill
GROUP BY SNOSQL 使用 GROUP BY 子句对元组分组。数据表中的列只有出现在 GROUP BY 子句后的列才能放在 SELECT 后面的目标列中。否则会报错。
错误示例:
SELECT SName, SNO, COUNT(DISTINCT GoodsNO) AS 商品种类 FROM SaleBill
GROUP BY SNO
/* 报错:SName 没有包含在聚合函数或 GROUP BY 子句中 */分组查询可以先对数据使用 WHERE 进行选择,再使用 GROUP BY 分组查询,一般情况下,可以提高查询效率。
例 2:统计 2019 年学生购买的商品种类数
SELECT SNO, COUNT(DISTINCT GoodsNO) AS 商品种类数
FROM SaleBill
WHERE YEAR(HappenTime) = 2019
GROUP BY SNO分组条件:对查询结果处理可以分组之外,SQL 同时还可以在分组的基础上,进行条件筛选,使用的关键字是 HAVING
例 3:统计每个学生购买的商品种类数,列出购买 3 种或以上商品学生的学号,购买商品种类数
SELECT SNO, COUNT(DISTINCT GoodsNO) AS 商品种类数
FROM SaleBill
GROUP BY SNO
HAVING COUNT(DISTINCT GoodsNO) >= 3- HAVING 对组进行选择,后面可以跟列名、聚合函数作为条件表达式。
- WHERE 对元组进行选择,因此聚合函数不能出现在 WHERE 子句里作为条件表达式
例 4:统计学生表中每年出生的男、女生人数,按出生年降序、人数升序排列
SELECT BirthYear,Ssex,COUNT(*)
FROM Student
GROUP BY BirthYear,Ssex
ORDER BY BirthYear DESC, COUNT(*)多表连接查询
前面的单表查询只涉及一个表的疏忽,更多的时候需要从多个表中查询数据。涉及到两个或两个以上表的查询,需要连接后查询。连接包括内连接和外连接。
内连接
内连接是一种常见的查询方式,内连接包括非等值来凝结、等值连接。等值连接的连接字段如果一样,去掉重复的列,就是自然连接。
方式一:使用 WHERE 子句
例 1:将商品表与商品种类表连接起来的语句
SELECT * FROM Goods.Category
WHERE Goods.CategoryNO = Category.CategoryNO商品表的字段 CategoryNO 与商品类别表的字段 CategoryNO 语义相同、数据类型相同(相容),被用作连接字段
方式二:使用 JOIN...ON 子句
基本格式:
FROM <TABLE1_name> [INNER] JOIN <TABLE2_name> ON
[<TABLE1_name>.]<COLUMN_name> <comparisonoperator> [<TABLE2_name>.]<COLUMN_name>
[JOIN ...]INNER 关键字表示是内连接,可以省略,即 JOIN 连接默认为内连接。关键字 ON 后的字段 COLUMN_name 如果在各表中是唯一的,则表名前缀(表 1.或表 2.)可以省略,否则必须加表名予以区分。连接字段在语法上必须是可以比较的数据类型。在语义上必须符合逻辑。否则比较毫无意义。
比较运算符为等号的连接称为等值连接,不为等号时为非等值连接。连接查询中常用等值连接查询
例 2:查询学生购物情况
SELECT * FROM Student
JOIN SaleBill ON Student.SNO = SaleBill.SNO上述的 SQL 语句的查询结果,会有两个 Sno,如果去掉重复字段,则为自然连接
SELECT Student,SNO,SName,BirthYear,Ssex,college,Major,Weixin,GoodsNO,HappenTime,Number
FROM Student JOIN SaleBill ON Student.SNO = SaleBill.SNO在查询的时候可以把多表连接的结果集看成一个单表来操作,在其后添加 WHERE 子句、GROUP BY 子句等。
为了简化代码,也可以为连接表指定别名,一旦指定别名后,查询语句中相应的表都要用该别名替代
例 3:查询“CS”学院各学生的消费金额
SELECT college, SNAME, SUM(SA,Number*SalePrice) 消费金额
FROM Student S JOIN SaleBill SA ON S.SNO=SA.SNO
JOIN Goods G ON G.GoodsNO=SA.GoodsNO
WHERE college="CS"
GROUP BY college, SNAME或者用 HAVING 子句实现相同的效果
SELECT college, SNAME, SUM(SA,Number*SalePrice) 消费金额
FROM Student S JOIN SaleBill SA ON S.SNO=SA.SNO
JOIN Goods G ON G.GoodsNO=SA.GoodsNO
GROUP BY college, SNAME
HAVING college="CS"自连接
自连接将同一张表进行连接。
同一张表之所以会自身连接,是因为该表存在不同属性列上的参照完整性约束,或者要查询同一张表中不同数据之间的部分共同属性值的情况。
- 自连接也是内连接
- 自连接需要在逻辑上复制出一张和数据表 A 一模一样的表 B
例 1:查询与商品“麦氏威尔冰咖啡”同一类别的商品的商品编号、商品名
SELECT G2.GoodsNO, G2.GoodsName
FROM Goods JOIN Goods G2 ON Goods.CategoryNO=G2.CategoryNO
WHERE Goods.GoodsName = "麦氏威尔冰咖啡"
AND G2.GoodsName != "麦氏威尔冰咖啡"
/* 这里相当于第一张表是为了选择信息,而第二张表就是为了显示更多信息 */等价于:
SELECT G2.GoodsNO, G2.GoodsName
FROM Goods, Goods G2
WHERE Goods.CategoryNO = G2.CategoryNO
AND Goods.GoodsName = "麦氏威尔冰咖啡"
AND G2.GoodsName != "麦氏威尔冰咖啡"外连接
内连接是将满足连接条件的元组连接起来形成结果集元组,但有时用户需要将不满足连接条件的元组也显示在结果集中。
比如查看哪些商品没有人买,这时就需要使用外连接来完成此类查询
外连接包括:
- 全外连接
- 左外连接
- 右外连接
全外连接
全外连接是将参与连接的表中不满足连接条件的元组均显示出来(关键字 OUTER 可以省略),无对应连接元组值使用 NULL 填充。
SELECT * FROM A
FULL JOIN A2 ON A.SNO=A2.SNO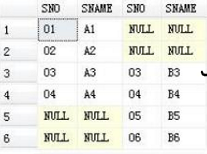
左外连接
左外连接使用LEFT [OUTER] JOIN ON语句连接。左边表的元组不管满不满足连接条件均显示,右边不满足连接条件的不显示。
SELECT * FROM A
JOIN A LEFT JOIN A2 ON A.SNO=A2.SNO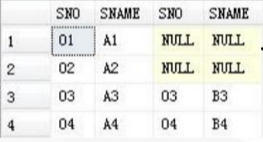
右外连接
右外连接使用RIGHT [OUTER] JOIN...ON语句连接,右边的元组不管满不满足连接条件均显示,左边不满足连接条件的不显示。
SELECT * FROM A
RIGHT JOIN A2 ON A.SNO=A2.SNO
子查询
嵌套查询
在 SQL 语句中,一个SELECT-FROM-WHERE是一个查询块。如果在一个查询块 WHERE 中还有一个SELECT-FROM-WHERE,则这样的查询称为嵌套查询。
SELECT SName FROM Student
WHERE SNO IN (
SELECT SNO FROM SaleBill
WHERE GoodsNO = "GN001"
)- 允许多层嵌套查询,也就是说一个子查询中,还可以再嵌套一个子查询
- 子查询的 SELECT 语句中不能有 ORDER BY 排序子句,ORDER BY 排序只能在最外层查询中
- 嵌套查询是用户可以用多个简单的查询语句构成一个复杂的查询,从而增强 SQL 语句的查询灵活性和效率。这也正是 SQL 结构化的特征之一。
IN 谓词子查询
例 1:查询与商品“麦氏威尔冰咖啡”同一类别的商品编号、商品名。
SELECT GoodsName FROM Goods WHERE CategoryNO IN
(
SELECT CategoryNO FROM Goods
WHERE GoodsName="麦氏威尔冰咖啡"
)
AND GoodsName != "麦氏威尔冰咖啡"例 2:查询购买了“某某食品销售部”经销的商品的学生学号,姓名
SELECT SNO,SName FROM Student WHERE SNO
IN (
SELECT DISTINCT SNO FROM SaleBill
WHERE GoodsNO
IN (
SELECT GoodsNO FROM Goods
WHERE SupplierNO
IN (
SELECT SupplierNO FROM Supplier
WHERE SupplierName="某某食品贸易部"
)
)
)比较子查询
比较运算符作为子查询
例 1:查询进价大于平均进价的商品名称,进价
SELECT GoodsName,InPrice FROM Goods
WHERE InPrice > (SELECT AVG(INPrice) FROM Goods)例 2:查询和“小明”在同一个学院的学生信息
SELECT * FROM Student
WHERE College = (
SELECT College FROM Student
WHERE SName = "小明"
)ANY ALL
子查询返回单个值时可以使用比较运算符,但返回多个值时,就不能直接使用比较运算符,可以采用 ANY ALL 谓词修饰符。
ANYALL 运算符是一个逻辑运算符,它将值与子查询返回的一组值进行比较。ANY 运算符必须以比较运算符开头,后跟子查询。
例 3:查询非计算机学院,比计算机学院任意一个学生都年龄大的学生信息
SELECT * FROM Student
WHERE BirthYear < ANY (
SELECT BirthYear FROM Student
WHERE College = "计算机学院"
) AND College <> "计算机学院"等价于:
SELECT * FROM Student
WHERE BirthYear < (
SELECT MAX(BirthYear) FROM Student
WHERE College = "计算机学院"
) AND College <> "计算机学院"例 4:查询非计算机学院,比计算机学院任意学生都年龄大的学生信息
SELECT * FROM Student
WHERE BirthYear < ALL (
SELECT BirthYear FROM Student
WHERE College = "计算机学院"
) AND College <> "计算机学院"等价于:
SELECT * FROM Student
WHERE BirthYear < (
SELECT MIN(BirthYear) FROM Student
WHERE College = "计算机学院"
) AND College <> "计算机学院"不相关子查询
不相关子查询是指内层查询条件不依赖于外层查询。即单独执行内层语句也会得到明确结果集。
例 1:查询与商品“麦氏威尔冰咖啡”同一类别的商品的商品编号、商品名
SELECT GoodsName FROM Goods WHERE CategoryNO
IN (
SELECT CategoryNO FROM Goods
WHERE GoodsName="麦氏威尔冰咖啡"
)
AND GoodsName != "麦氏威尔冰咖啡"例 2:查询进价大于平均进价的商品名称
SELECT GoodsName,InPrice
FROM Goods
WHERE InPrice > (
SELECT AVG(InPrice)
FROM Goods
)相关子查询
如果查询内层查询的查询条件依赖于外层查询,则被称为相关子查询。
例 3:查询超过同种类商品进价的商品信息
SELECT * FROM Goods
WHERE InPrice > (
SELECT AVG(InPrice)
FROM Goods G
WHERE G.CategoryNO = Goods.CategoryNO
)这里的平均价格就是在同类别中计算的,而类别就依赖于外层查询中正在查询的某个商品的信息
可见相关子查询不能像无相关子查询一样,一次性将内层查询结果获得,而是要根据外层查询,一个一个元组进行到内层查询中去求解。
EXISTS 谓词
- 带有 EXISTS 谓词的子查询不返回任何数据,如果子查询结果不为空,则返回真值,否则返回假值,不关心具体数据,所有带 EXISTS 谓词的子查询往往用
*代替目标列 - 所有 EXISTS 查询都是相关查询
例 4:查询购买了商品的学生信息
SELECT * FROM Student
WHERE EXISTS /* 查询该学生是否存在购买记录 */
(
SELECT * FROM SaleBill
WHERE SNO=Student.SNO
)集合查询
就是将两个查询结果集作集合操作
- 并 UNION
- 交 INTERSECT
- 差 EXCEPT
基于派生表查询
当子查询出现在 FROM 子句中时,子查询的查询结果形成一个临时派生表,这个表也可以作为查询对象。
例 1:查询各类别商品商品种类名,平均售价
SELECT C.CategoryName, AVG_CA, AVGSALEPRICE
FROM Category C JOIN
(
SELECT CategoryNO,AVG(SalePrice)
FROM Goods
GROUP BY CategoryNO
)
AS AVG_CA(CategoryNO AVGSALEPRICE)
ON C.CategoryNO=AVG_CA>CATEGORYNO例 2:查询购买了 GN0002 商品的学生信息
SELECT * FROM Student S JOIN
(
SELECT SNO, GoodsNO FROM SaleBill /* 这个查询结果作为一个派生表 */
WHERE GoodsNO="GN0002"
) SA_SNO
ON S.SNO=SA_SNO.SNOTOP 结果集选择
使用 TOP 谓词选择前 n 条记录TOP n [percent] [WITH TIES]
其中 n 为非负数,表示前 n 条元组。Percent 表示前n%条元组;WITH TIES 表示包括并列结果,如果使用了 WITH TIES,则必须使用 ORDER BY 对结果集进行排序
例:查询销售额前三的商品与销售额
SELECT TOP 3 G.GoodsNO, SUM(SA.Number*G.SalePrice) GOODSUM
FROM Goods G JOIN SaleBill SA
ON SA.GoodsNO=G.GoodsNO
GROUP BY G.GoodsNO
ORDER BY GOODSUM DESC插入数据
SQL 使用 INSERT 语句插入数据,通常由两种形式,一种时插入一个元组,一种时插入子查询结果。
SQL 插入元组的格式为:
INSERT INTO <TABLE_name>
[(<COLUMN_name1>[, COLUMN_name2]...)]
VALUES
(<CONSTANT1>[,<CONSTANT2>]...)- 插入全部列值,则列名可以省略
- 插入常量顺序与列名顺序一致,同时庶几乎类型更要匹配
- 指定插入部分列名,没有出现的列允许取空值,那就插入空值
插入元组
例:将学生程浩的信息插入 Student 表中
INSERT INTO Student
VAlUES ('S09', '程浩', 1999, '男', 'CS', 'IT', 'wx009')或
INSERT INTO
Student(SNO, SName, BirthYear, Ssex, college, Major, Weixin)
VALUES
('S09', '程浩', 1999, '男', 'CS', 'IT', 'wx009')因为时插入全部列,所以第一种写法省略了列名
插入子查询结果
格式:
INSERT INTO <TABLE_name>
( <COLUMN_name1> [,<COLUMN_name2>...] )
SELECT...执行该语句需要先建立表,然后将子查询结果集插入。
另外还有一种插入子查询结果的语句:
SELECT <COLUMN_name1>[,<COLUMN_name2>...]
INTO <NEW_TABLE_name>
FROM ...不需要建立表,在执行语句的时候同时建立于查询字段同数据类型的表,该表必须是新表。
例:查询没人购买的商品,列出商品名与现货存量插入新的表中
CREATE TABLE SubGoods(
GoodsName varchar(100),
Number int
)INSERT INTO SubGoods
SELECT GoodsName, G.Number FROM Goods G
LEFT JOIN SaleBill GA
ON GA.GoodsNO=G.GoodsNO WHERE GA.SNO IS NULL或者:
/* 该方法无需新建表,语句会自动创建 */
SELECT GoodsName,G.Number
INTO SubGoods1
FROM Goods G LEFT JOIN SaleBill GA
ON GA.GoodsNO=G.GOodsNO WHERE GA.SNO IS NULL修改数据
数据更新
格式:
UPDATE <TABLE_name>
SET <COLUMN_name = Expression>[,...]
[WHERE <UPDATE_condition>]无条件更新
无条件更新是指不带 WHERE 子句的数据更新
例 1:将货物保有量均加 2
UPDATE Goods
SET Number=Number+2有条件更新
1)单元组更新
只对一条数据进行数据更新
例 2:将学生 S002 的出生年份修改为 1992
UPDATE Student SET BIrthYear = 1992
WHERE Sno = "S002"2)多元组更新
同时对多条数据进行数据更新
无条件本身就是多元组的数据更新,或者讲全部数据
例 3:将过期商品现货存量清零
UPDATE Goods
SET Number=0
WHERE DATEDIFF(DAY,ProductTime,GETDATE()) - QGPeriod*30>0子查询更新
子查询也可以嵌套在 UPDATE 语句中,用以构造修改的条件。
例:将“重庆某某贸易公司”的商品加价 10%
UPDATE Goods
SET SalePrice*1.1
WHERE SupplierNO
IN (
SELECT SupplierNO FROM Supplier
WHERE SupplierName="重庆某某贸易公司"
)删除数据
数据删除
格式:
DELETE [FROM] <TABLE_name>
[WHERE <DELETE_condition]DELETE 删除满足条件的元组,FROM 关键字可以省略。没有 WHERE 子句则删除表全部元组
DELETE 与 DROP 的不同之处在于,前者删除表中的数据,后者删除表的结构。使用 DROP 后,数据库中不再存在删除对象。
无条件删除
无条件删除就是删除表中全部数据
示例 1:删除新增数据时的 SubGoods 表中的数据
DELETE FROM SubGoods条件删除
删除表中满足条件的数据
1)单元组删除
即满足条件的数据只有一个
例:删除学号为 S003 的学生信息
DELETE FROM Student
WHERE Sno = "S003"2)多元组删除
即满足条件的数据有多个,无条件删除本身也是多元组删除。
例:将某重庆某某贸易公司的商品下架,即删除该供应商在商品表中的元组
DELETE FROM Goods
FROM Supplier S JOIN Goods G ON
G.Supplier=S.SupplierNO
WHERE SupplierName="重庆某某贸易公司"子查询删除
使用子查询的方式,来构建删除条件
DELETE FROM Goods
WHERE SupplierNO
IN (
SELECT SupplierNO FROM Supplier
WHERE SupplierName="重庆某某贸易公司"
)视图
视图是数据库中常用对象之一,它的内容是数据库部分数据或以聚合等方式重构的数据。
- 只存放视图的定义,不存放数据
- 不存储数据,所以视图是一个虚表
- 因为数据存在于基本表中,基本表的数据发生变化时,视图查询的结果集会随之改变
- 视图的数据来源可以是一个表,也可以是多个表。定义好的视图可以和基本表一样被查询、被删除。
视图定义
格式:
CREATE VIEW <VIEW_name>
[(<COLUMN_name>[,<COLUMN_name>][...])]
AS <SELECT..> /* 跟子查询 */
[WITH CHECK OPTION]语句 WITH CHECK OPTION 表示通过属兔进行更新操作时要保证更新的数据满足子查询的条件表达式。
组成视图的列名要么省略,要么 1 全部指定。如果省略,则视图的列名就由子查询的列名组成
在下列情况下,必须指定视图列名:
- 子查询的某个目标列时聚合函数或列表达式
- 多表连接时出现同名列作为视图的列
- 需要在视图中指定新列名替代子查询列名
例 1:建立咖啡类商品的视图
CREATE VIEW Coffee
AS
SELECT GoodsNO,GoodsName,InPrice,SalePrice,ProductTime
FROM Goods G JOIN Category V ON
G.CategoryNO=C.CategoryNO
WHERE CategoryName="咖啡"例 2:建立 MIS 专业学生的视图,并要求通过视图完成修改于插入操作时视图仍只有 MIS 专业学生
CREATE VIEW MIS_student
AS
SELECT * FROM Student WHERE Major="MIS"
WITH CHECK OPTION本例使用WITH CHECK OPTION语句对以后通过视图进行插入、修改的数据进行限制,均要求数据存在于该视图中,这里就是满足Major="MIS"条件
视图可以定义在已经定义的视图上,也可以建立在表与视图的连接上。
例 3:建立购买了咖啡类商品的学生视图
CREATE VIEW Buy_coffee
AS
(
SELECT * FROM SaleBill S JOIN Coffee C ON
C.GoodsNO=S.GoodsNO
WHERE S.SNO=Student.SNO
)本例基于视图Coffee建立了新的视图
定义基本表时,为了减少数据冗余,表中只存放基本数据,在基本数据上的聚合运算、列表达式运算等一般不予存储。可以定义视图存储这些操作,便于使用。
例 4:建立保存商品编号于销售额的视图
CREATE VIEW SumSale(GoodsNO, SumSale)
AS
SELECT G.GoodsNO, SUM(SalePrice*S.Number) SumSale
FROM SaleBill S JOIN Goods G ON S.GoodsNO=G.GoodsNO
GROUP BY G.GoodsNO在视图中必须使用新的列名,这里取名"SumSale"
注:视图子查询中也可以使用 TOP、ORDER BY 等谓词
删除视图
DROP VIEW <VIEW_name>查询视图
和基本表的查询类似
更新视图
更新视图时通过视图来插入、删除、修改数据。由于视图不存储数据,通过视图更新数据最终要转换为对基本表的更新
例:在 Buy_coffee 视图中插入一个新的学生信息,其中学号为“S09”,姓名为“程伟”,出生年为 1993,其余为空
INSERT INTO Buy_coffee (SNO,SName,BirthYear)
VALUES("009", "程伟", 1993)执行 SQL 时转换为:
INSERT INTO Student (SNO,SName,BirthYear)
VALUES("009","程伟",1993)视图作用
合理使用视图会带来很多好处:
- 简化数据查询
- 使用户多角度看待同一数据
- 提供一定程度的逻辑独立性
- 提供数据库安全性:可以在设计数据库时对不同用户定义不同的视图,使各级用户只能看权限范围内的数据。