排序
稳定性:相同关键字元素的相对次序保持不变,则是稳定排序。
直接插入排序
每次将一个待排序的记录插入到已排好序的数据区中直到全部插入完为止。
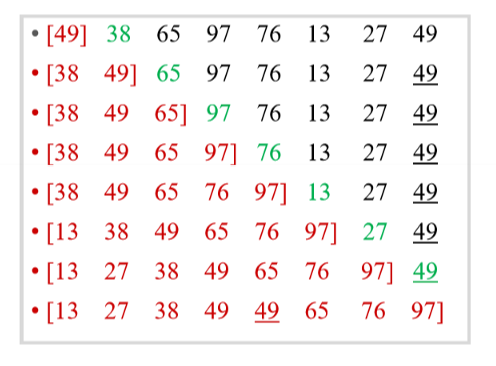
是稳定的排序。
带监视哨的插入排序:
- 设置监视哨 r[0],将待插入记录的值赋给 r[0]
- 设置查找起始位置 j
- 查找:
- while(r[0].key<r[j-1].key)
- r[j]=r[0]
- 监视哨的作用
- 进入查找循环之前,保存了 r[i]的副本,记录后移时不会丢失 r[i]的内容。
- 循环中“监视”下标变量 j 是否越界。
- 一旦越界(即 j=0),能控制 while 循环结束。
- 避免在 while 循环内每次都要检测 j 是否越界的问题。
希尔排序
shell 排序是对位置间隔较大的结点进行比较,则结点一次比较后能跨过较距离,可能提高排序速度。

shell 排序是不稳定的排序。
冒泡排序
此处省略。
稳定的排序。
快速排序
对一组无序的数据集合,选择任意元素作为基准点
- 该基准点左边的所有记录都小于或等于它。
- 是基准点右边的所有记录都大于多等于它。
- 然后重复上述操作,分别对左右半区进行快速排序。

是不稳定的排序。
需要一个栈空间来实现递归。
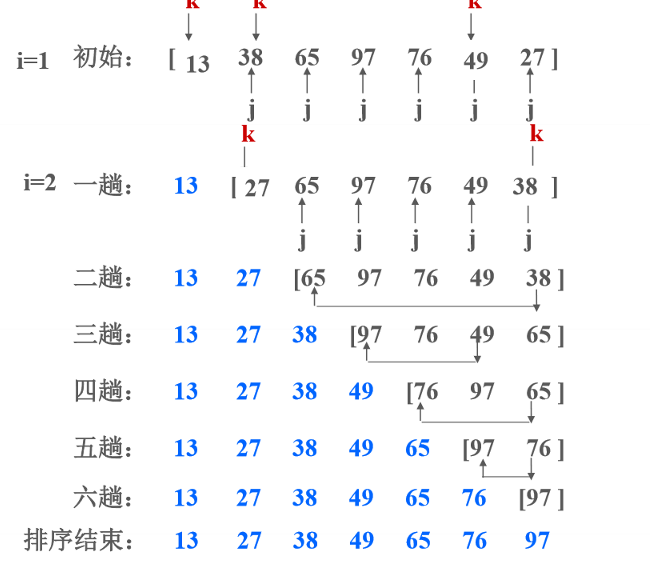
简单选择排序
- 通过 n-1 次关键字比较,从 n 个记录中找出关键字最小的记录,将它与第一个记录交换。
- 通过 n-2 次比较,从剩余的 n-1 个记录中找出关键字次小的记录。
- 重复上述操作,进行 n-1 躺排序后结束。
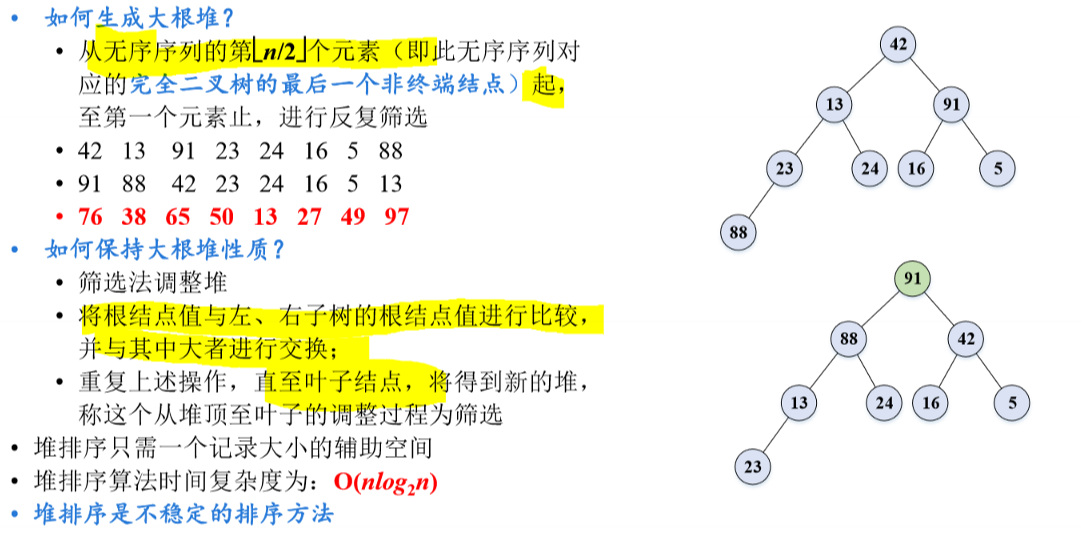
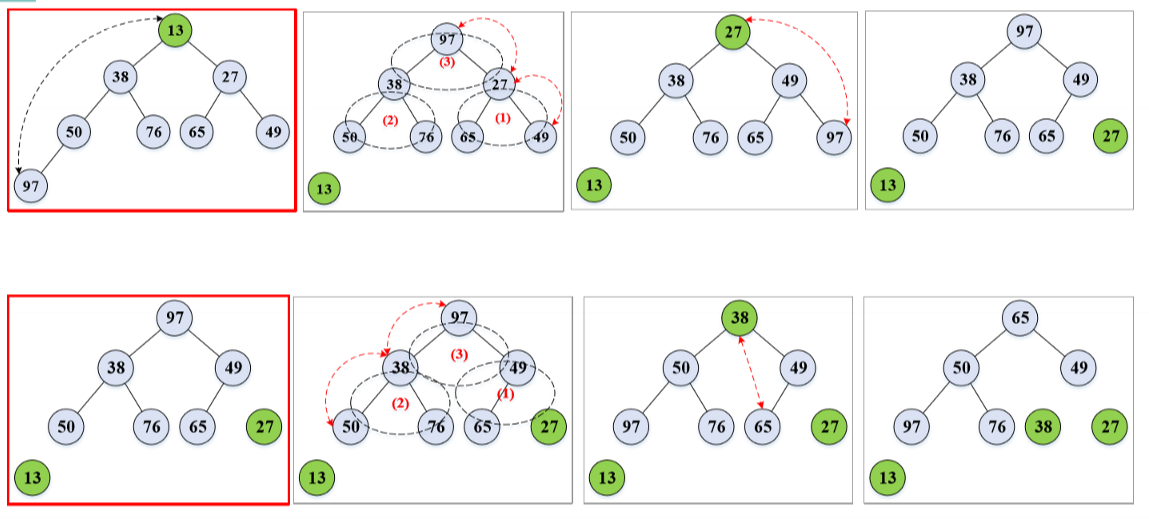
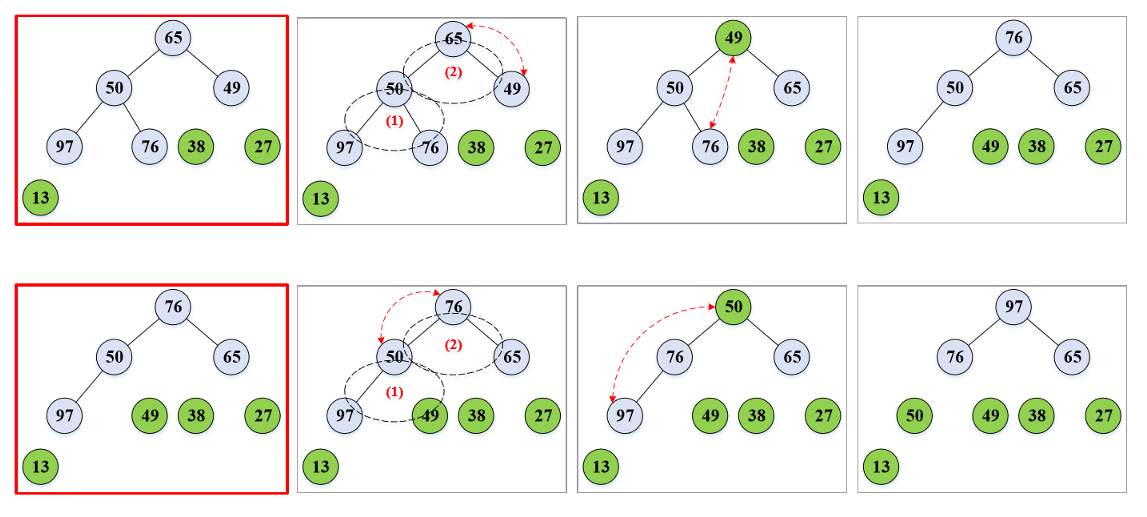
堆排序
大根堆:根结点(即堆顶)的关键字是堆里所有结点关键字中最大者的堆,称为大根堆。
小根堆:根结点(即堆顶)的关键字是堆里所有结点关键字中最小者的堆,称为小根堆。

堆排序的思路:
- 按某种方法生成大根堆,该大根堆的根就是键值最大的元素。
- 将根与向量尾部的元素进行互换,即最大值放到向量的末尾(有序区)。
- 将剩余的 n-1 个元素再次调整成大根堆,可得到次大值。
- 将次大值放到向量的倒数第二的位置。
- ······
- 如此反复,直到全部关键字排好序为止。

python
# -*- coding:utf-8 -*-
def head_sort(list):
length_list = len(list)
first=int(length_list/2-1)
# 假设 len=8, 这里 first=3, 下面的 range 就是[3210]
for start in range(first,-1,-1): # 循环把所有子树生成大根堆
max_heapify(list,start,length_list-1)
for end in range(length_list-1,0,-1):
list[end],list[0]=list[0],list[end]
max_heapify(list,0,end-1) # 后面就是自上而下的交换了,不用每个都判断了(不用像生成大根堆那样)
return list
def max_heapify(ary,start,end): # 把子树生成大根堆
root = start
# 其中标*的两句话是为什么结点到上面的几层仍然可以与底层的进行比较交换的原因
while True: # *
child = root*2 + 1
if child > end: # 判断是否有左孩子
break
if child + 1 <= end and ary[child]<ary[child+1]: # 判断是否有右孩子,且如有就留大的
child = child + 1
if ary[root]<ary[child]: # 把刚那个大的孩子与根进行比较交换
ary[root],ary[child]=ary[child],ary[root]
root=child # *
else:
break
#测试:
list=[10,23,1,53,654,54,16,646,65,3155,546,31]
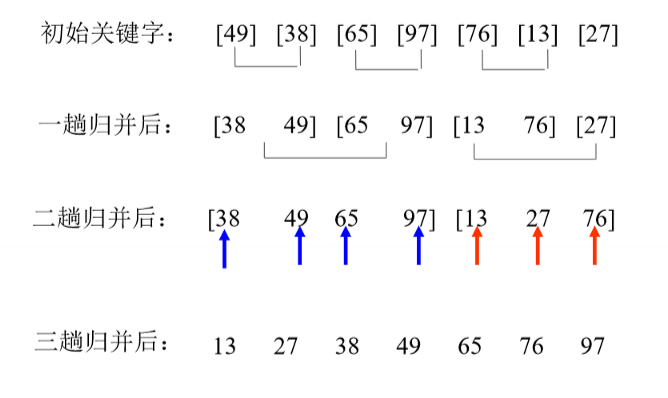
print head_sort(list)归并排序
将若干已排好序的子序列合并成一个有序的。